Redis介绍以及操作
Redis的数据类型
String :最基本的数据类型,二进制安全redis的String能存储任何数据 例如图片序列化对象 最大能存储512m set key ”value” get key 就能获取到value值 redis的单个操作都是原子性的 是一个事物不可分割的最小单位 incr 递增
String 能够存储这么多东西是因为其底层的sdshdr 简单动态字符串该字符串包含了 int len buf中已占用空间长度 int free buf中剩余可用的长度,char buf[]数据空间
redis的原子性让我们不用考虑并发问题
Hash:String元素组成的字典,适用于存储对象 hmset xiaohong name ‘xiaohong’ age 20 hget 获取 hget xiaohong age hset xiaohong age 22 hash对象存储很不错
List:列表,按照String插入顺序排序 左边插入元素 lpush mylist aaa lpush mylist bbb 从左往右取数据 llrange mylist 0 10 从左往右从第零位往右取出十个数据 从第一个开始取 list能存储41个成员 实现最新消息排行榜
Set:String 元素组成的无序集合,通过hash表实现,不允许重复 sadd myset test sadd myset test2 返回值为 1 当插入重复元素时返回值为 0 smenbers myset 查看set中的元素
Sorted set:通过分数来为集合中的成员进行从小到大的排序不能重复 zadd myzset 3(这个三是分数)abc zrangebyscore myzset 0 10 按照分数去取十个 分数越小越往前排
底层数据类型基础
1:简单动态字符串
2:链表
3:字典
4:跳跃表
5:整数集合
6:压缩列表
7:对象
从海量key中查询出某一固定前缀的key
留意细节
1:摸清楚数据规模,即问清楚边界
Keys pattern :查找所有符合给定,模式pattern的key keys k1*查找所有k1开头的字段 因为数据量太大会被卡主
1:keys的缺点就是需要一次性返回所有匹配的key
2:键的数量过大会使服务卡顿 对内存的消耗 和redis的服务器都是一个隐患
可以使用scan指令 SCAN cursor [MATCH pattern][COUNT count]
1:基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程 游标就是 cursor ---!kese
2:以0作为游标开始一次新的迭代、直到命令返回游标0完成一次遍历
3:不保证每次执行都返回某个给定数量的元素,支持模糊查询
4:一次返回数量不可控,只是大概符合count 参数
例子: scan 0 match k1* count 10 scan 2003 match k1* count 10
5:会存在获取重复key的现象,需要去重 可以使用hashset
如何实现分布式锁
分布式锁需要解决的问题:
1:互斥性
2:安全性
3:死锁
4:容错 redis节点宕机的时候不影响客户端使用
SETNX key value :如果key不存在,则创建并赋值 时间复杂度为O(1)
返回值,如果当前的key存在则创建失败返回 0 ,如果key不存在则创建成功返回1
setnx是有原子性的;
如何解决SETNX长期有效问题:
EXPIRE key second
1:设置key的生存时间,当key过期(生存时间为0),会被自动删除
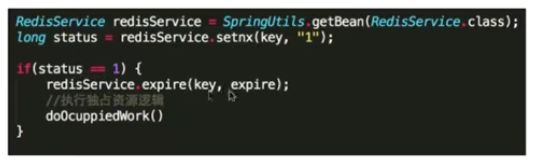
2:缺点,原子性得不到满足 当SETNX之后就直接挂掉来不及expire,此时key就会被一直占用着。
如何通过redis实现分布式锁?
SET key value [EX seconds][PX milliseconds][NX|XX]
EXsecond:设置键的过期时间为 second秒
PXmilliseconds:设置键的过期时间为millisecond毫秒
NX:只在键不存在时,才对键进行设置操作
XX:只在键已经存在时,才对键进行设置操作
SET操作成功完成时返回OK,否则返回nil
age:set name test ex 10 nx 能确保 name在十秒之内是锁定的
大量的key同时过期的注意事项
集中过期,由于清除大量的key很耗时,会出现短暂的卡顿现象
解决方案:在给key设置过期时间时,给每个key加一个随机值
用redis做异步队列:
使用List作为队列,RPUSH生产消息,LPOP消费消息
age: rpush sequence 001 rpush sequence 002 rpush sequence 003
lpop sequence 值为 001
lpop sequence 值为 002
lpop sequence 值为 003
缺点:没有等待队列里有值,就直接消费
弥补:可以通过在应用层引入Sleep机制去调用LPOP
如果不用sleep去做的话:使用 blpop key timeout 阻塞 直到队列有消息过来或者阻塞 blpop sequence 30
缺点:只能供一个消费者消费
pub/sub:主题订阅者模式
发送者(pub)发送消息,订阅者(sub)接收消息
订阅者可以订阅任意数量的频道 订阅为age:subscribe sequence publish myTopic "I love you"
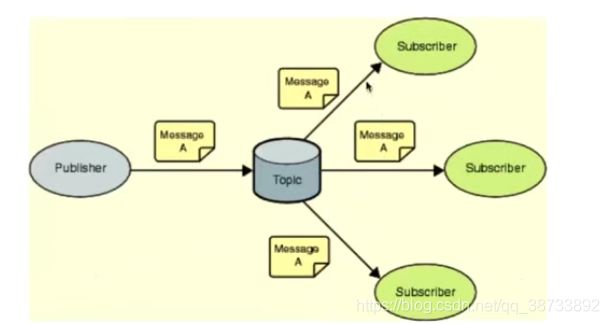
缺点:消息发布是无状态的,无法保证可达 消息即发即失
缓存雪崩和缓存穿透问题解决方案
缓存雪崩
简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决办法:
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存

缓存穿透
简介:一般是黑客故意去请求缓存中不存在的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决办法: 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
如何解决 Redis 的并发竞争 Key 问题
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
在实践中,当然是从以可靠性为主。所以首推Zookeeper。