Java8 Stream API详细操作
一、Stream流的基本概念
1、什么是Stream流?
流是Java8引入的全新概念,它用来处理集合中的数据,对集合(Collection)对象功能的增强,专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。
Java中的Stream并不会存储元素,而是按需计算,且只能遍历一次。同时结合 Lambda 表达式,极大的提高编程效率和程序可读性。
Stream流采用内部迭代方式,通过访问者模式(Visitor)实现。
若要对集合进行处理,则需我们手写处理代码,这就叫做外部迭代。比如:使用Iterator或for循环来遍历集合。
若要对流进行处理,我们只需告诉流我们需要什么结果,处理过程由流自行完成,这就称为内部迭代。比如:Collection.forEach(…)方法迭代。
2、Stream流的操作种类
流的操作可以分为两种:中间操作和终端操作。
1. 中间操作
当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为 Pipelining 操作。
中间操作可以连接起来,将一个流转换为另一个流。这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。
中间操作都会返回流对象本身。
2. 终端操作
当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终端操作。
一个流只能有一个 Terminal 操作,当这个操作执行后,流的操作就结束了,无法再被操作。
Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果。
3、Stream流的操作过程
Stream流操作可以分三个步骤:
1、获取一个数据源:可以是集合,数组,I/O channel, 产生器generator 等。
2、中间操作(intermediate operation):
在管道的节点上进行处理,比如: filter、 distinct、 sorted等,它们可以串连起来形成流水线。
3、最终操作(terminal operation):执行终端操作后本次流结束,并返回一个执行结果。
注意:流进行了终止操作后,不能再次使用,否则会报错。
二、获取Stream流对象
在使用流之前,需要先拥有一个数据源,并通过StreamAPI提供的一些方法获取该数据源的Stearm接口类型流对象。
注意:
- 除了Stream类型外,还有几个IntStream、LongStream、DoubleStream很常用, 因为boxing 和 unboxing 会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
- 此外还有一个流类型:并行流parallelStream,parallelStream提供了流的并行处理,它是Stream的另一重要特性,其底层使用Fork/Join框架实现。
串行流:适合存在线程安全问题、阻塞任务、重量级任务,以及需要使用同一事务的逻辑。
Stearm类型有:Stream,还有IntStream、LongStream、DoubleStream也很常用,因boxing和 unboxing会很耗时,所以这三种基本数值型提供了对应的 Stream。
并行流:适合没有线程安全问题、较单纯的数据处理任务。
Stearm类型有:并行流parallelStream。
parallelStream提供了流的并行处理,其中 parallelStream()方法能够充分利用多核CPU的优势,使用多线程加快对集合数据的处理速度。
下面来认识常用的数据源来获取Stearm对象。后面进行操作的更多方法等,请查看API。函数式接口就不多说了。
public class User {
private int id;
private String name;
private String sex;
private int age;
private int height;
...
}1、集合
集合 数据源比较为常用,通过 stream()方法即可获取 Stearm对象。
List list = new ArrayList<>();
list.add(new User(1, "赵云", "男", 18, 178));
list.add(new User(2, "后裔", "男", 20, 188));
list.add(new User(1, "妲己", "女", 17, 175));
Stream stream = list.stream();
Stream parallelStream = list.parallelStream(); 2、数组
通过 Arrays 类提供的静态 stream()方法获取数组的 Stearm对象。
String[] arr = new String[]{"赵云", "后裔", "妲己"};
Stream stream = Arrays.stream(arr); 3、值
直接将几个值变成 Stearm对象,IntStream、LongStream、DoubleStream。
IntStream intStream = IntStream.of(new int[]{1, 2, 3});
LongStream longStream = LongStream.range(1, 3); // [1,3)
LongStream longStream2 = LongStream.rangeClosed(1, 3); // [1,3]
DoubleStream doubleStream = DoubleStream.of(1.0, 3.0); 4、其他创建方法
-
-
staticStream generate(Suppliers) 返回一个无穷序列无序流,其中每个元素是由提供
Supplier生成。staticStream iterate(T seed, UnaryOperatorf) 返回一个无穷序列有序
Stream由最初的一元seed函数的f迭代应用产生的,产生一个由seed,f(seed),f(f(seed))Stream,等。
-
Stream中的generate() 很好理解。 iterate () 方法,参数为一个种子值,和一个一元操作符(例如 f)。然后种子值成为 Stream 的第一个元素,f(seed) 为第二个,f(f(seed)) 第三个,以此类推。
注意:这两种方法创建的流是无限的,在管道中,必须利用 limit 之类的操作限制 Stream 大小。
// 生成 10 个随机整数
Stream stream = Stream.generate(new Random()::nextInt).limit(10);
// 生成10个等差(2)数列
Stream stream1 = Stream.iterate(0, n -> n + 2).limit(10);
三、中间操作
1、filter方法:过滤掉不符合谓词判断的数据
-
-
Streamfilter(Predicate predicate)返回由该流的元素组成的流,该元素与给定的谓词匹配。
-
在执行过程中,流将元素逐一输送给filter,并筛选出Predicate函数执行结果为true的元素。
public static void main(String[] args) {
List list = new ArrayList<>();
initList(list);
List userList = list.stream().filter(u -> "男".equals(u.getSex())).collect(Collectors.toList());
userList.forEach(System.out::println);
}
private static void initList(List list) {
list.add(new User(1, "赵云", "男", 18, 178));
list.add(new User(2, "后裔", "男", 20, 188));
list.add(new User(1, "妲己", "女", 17, 175));
} 2、distinct方法:去重
-
-
Streamdistinct()返回一个包含不同的元素流(根据
Object.equals(Object))这个流。
-
long count = IntStream.of(1, 2, 3, 4, 3, 2, 1).distinct().count();
System.out.println(count); // 43、limit方法:截取多少条数据
-
-
Streamlimit(long maxSize)返回一个包含该流的元素流,截断长度不超过
maxSize。
-
4、skip方法:跳过前几条数据
-
-
Streamskip(long n)返回一个包含此流的其余部分丢弃的流的第一
n元素后流。
-
List userList = list.stream().filter(u -> "男".equals(u.getSex())).skip(1).collect(Collectors.toList());
userList.forEach(System.out::println); // 后裔 5、map方法:映射,将一个元素转换成另一个元素类型
-
-
Stream map(Function mapper)返回一个流,包括将给定函数应用到该流元素的结果。
-
对流中的每个元素执行一个函数,使得元素转换成另一种类型输出。流会将每一个元素输送给map函数,并执行map中的Lambda表达式,最后将执行结果存入一个新的流中。
List nameList = list.stream().map(User::getName).collect(Collectors.toList());
nameList.forEach(System.out::println); 6、flatMap方法:合并多个流
-
-
Stream flatMap(Function> mapper)返回由将所提供的映射函数应用到每个元素的映射流的内容替换此流的每个元素的结果的结果流。
-
注意:
- map 方法:是将元素转换成另一种类型输出,返回一个大流,大流里面包含了一个个小流,
- flatMap 方法:是将大流中的这些小流合并成一个流返回。
List list = new ArrayList();
list.add("a,b,c,d");
list.add("e,f,a,b");
list.add("h,i,c,d");
List list1 = list.stream().map(line -> line.split(",")).collect(Collectors.toList());
List list21 = list.stream().map(line -> line.split(",")).flatMap((arr) -> Arrays.stream(arr)).collect(Collectors.toList());
List list22 = list.stream().map(line -> line.split(",")).flatMap(Arrays::stream).distinct().collect(Collectors.toList()); 
7、peek方法:遍历操作
-
-
Streampeek(Consumer action)返回由该流的元素组成的流,并在所提供的流中执行所提供的每个元素上的动作。
-
peek()操作,当元素被消费时(终端操作方法被调用时),会触发前面peek。有多少个就触发多少次。
// 不会有任何的输出
Stream.of("a", "b", "c", "d").peek(e -> System.out.print(e + " "));
// 会输出
Stream.of("a", "b", "c", "d").peek(System.out::print).collect(Collectors.toSet());8、unordered方法:返回一个无序的流,对于不关心顺序的数据处理和并行配合使用更佳。
-
-
Sunordered()返回一个等效流, unordered。
-
IntStream.rangeClosed(0,9).unordered().forEach(System.out::print); // 0123456789
System.out.println();
IntStream.rangeClosed(0,9).parallel().unordered().forEach(System.out::print); // 6570918342如果不关心顺序,则可以使用并行,这样使用,能提高CPU的利用率,进而提高处理的效率。比如。某活动(参与用户大数量)随机获取三名幸运观众。
9、sorted方法:对数据排序
-
-
Streamsorted()返回由该流的元素组成的流,按自然顺序排序。
Streamsorted(Comparator comparator)返回一个包含该流的元素流,根据提供的
Comparator排序。
-
应用非常广泛,重点掌握。
// 年龄升序
List userList = list.stream().sorted(Comparator.comparingInt(User::getAge)).collect(Collectors.toList());
userList.forEach(System.out::println); 四、终端操作
1、allMatch方法:匹配所有元素都满足返回true
2、anyMatch方法:匹配任何元素有满足返回true
3、noneMatch方法:匹配所有元素都不满足返回true
noneMatch与allMatch恰恰相反
boolean |
allMatch(Predicate predicate) 返回此流中的所有元素是否匹配所提供的谓词。 |
boolean |
anyMatch(Predicate predicate) 返回此流中的任何元素是否匹配所提供的谓词。 |
boolean |
noneMatch(Predicate predicate) 返回此流中的任何元素是否匹配所提供的谓词。 |
public static void main(String[] args) {
List list = new ArrayList<>();
initList(list);
// 判断所有人是否都为男性
boolean b1 = list.stream().allMatch(user -> "男".equals(user.getSex()));
System.out.println(b1); // false
// 判断所有人中是否有个男性
boolean b2 = list.stream().anyMatch(user -> "男".equals(user.getSex()));
System.out.println(b2); // true
// 判断所有人中是否都为女性
boolean b3 = list.stream().noneMatch(user -> "男".equals(user.getSex()));
System.out.println(b3); // false
}
private static void initList(List list) {
list.add(new User(1, "赵云", "男", 18, 178));
list.add(new User(2, "后裔", "男", 20, 188));
list.add(new User(1, "妲己", "女", 17, 175));
} 4、findAny方法:获取任一元素。
findAny能够从流中随便选一个元素出来(该操作行为明确不确定的),它返回一个Optional类型的元素。比如:随机抽取一名幸运观众。
5、findFirst方法:获取第一个元素
-
-
OptionalfindAny()返回一个
Optional描述一些流元素,或一个空的Optional如果流是空的。OptionalfindFirst()返回一个
Optional描述此流的第一个元素,或者一个空的Optional如果流是空的。
-
OptionalInt optional = IntStream.rangeClosed(1, 1000).findFirst();
System.out.println(optional.getAsInt());
OptionalInt optionalInt = IntStream.rangeClosed(1, 1000).parallel().findAny();
System.out.println(optionalInt.getAsInt());6、forEach和forEachOrdered方法:遍历每一个元素
-
-
voidforEach(Consumer action)对该流的每个元素执行一个动作。
voidforEachOrdered(Consumer action)对该流的每个元素执行一个操作,如果流有一个定义的遇到顺序,则在该流的遇到顺序中执行一个动作。
-
IntStream.rangeClosed(0,9).parallel().unordered().forEachOrdered(System.out::print); // 01234567897、mapToXxx方法:将普通流转换成数值流
提供了将普通流转换成数值流的三种方法:mapToInt、mapToDouble、mapToLong。
-
-
DoubleStreammapToDouble(ToDoubleFunction mapper)返回一个包含应用给定的功能,该流的元素的结果
DoubleStream。IntStreammapToInt(ToIntFunction mapper)返回一个包含应用给定的功能,该流的元素的结果
IntStream。LongStreammapToLong(ToLongFunction mapper)返回一个包含应用给定的功能,该流的元素的结果
LongStream。
-
IntStream intStream = list.stream().mapToInt(User::getAge);8、数值计算
每种数值流都提供了数值计算函数,如max、min、sum等。
-
-
Optionalmax(Comparator comparator)返回最大元本流根据提供的
Comparator。Optionalmin(Comparator comparator)返回最小元本流根据提供的
Comparator。
-
OptionalDouble average = list.stream().mapToInt(User::getAge).average();
System.out.println(average.getAsDouble()); // 18.3333333333333329、reduce方法:能实现归约,输出一个值(任何类型)。
归约是将集合中的所有元素经过指定运算,折叠成一个元素值输出。比如:求最值、平均数等。
-
-
Optionalreduce(BinaryOperatoraccumulator) 对这一 reduction流元素,使用 associative累积函数,并返回一个
Optional描述价值减少,如果任何。Treduce(T identity, BinaryOperatoraccumulator) 对这一 reduction流元素,使用提供的价值认同和 associative累积函数,返回值减少。
Ureduce(U identity, BiFunction对这一 reduction流元素,使用提供的身份,积累和组合功能。
-
三个参数的含义:
identity:一个初始化的值;这个初始化的值其类型是泛型U(与Stream中元素的类型可以不一样也可以一样),与Reduce方法返回的类型一致;
accumulator:其类型是 BiFunction函数(输入U与T两个类型的参数数据,而返回计算后的数据)
combiner: 其类型是 BinaryOperator函数,支持的是对U类型的对象进行操作,主要是使用在并行计算的场景下。注意:如果Stream是非并行时,第三个参数不起作用。
ArrayList result = Stream.of("a", "b", "c", "d").reduce(new ArrayList<>(),
(u, s) -> {
u.add(s);
return u;
}, (strings, strings2) -> strings); //无效的
System.out.println(result); //[a, b, c, d]
Integer reduce = Stream.of(1, 2, 3).reduce(4,
(integer, integer2) -> integer + integer2,
(integer, integer2) -> integer * integer2); //无效的
System.out.println(reduce); //10
Integer reduce2 = Stream.of(1, 2, 3).parallel().reduce(4,
(integer, integer2) -> integer + integer2, //开启三个线程,每个线程里对应一个元素+4
(integer, integer2) -> integer * integer2); //有效的,它会将不同线程计算的结果调用combiner做汇总后返回。
System.out.println(reduce2); //210
int accResult = Stream.of(1, 2, 3)
.reduce(4, (acc, item) -> {
System.out.println("acc : " + acc);
acc += item;
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("--------");
return acc;
});
System.out.println("accResult: " + accResult); //10 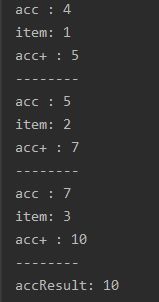
也可以进行元素求最值、平均数等操作。
int sum1 = 0;
for (User user : list) {
sum1 = sum1 + user.getAge();
}
System.out.println(sum1); // 55
Optional sum = list.stream().map(user -> user.getAge()).reduce((u1, u2) -> u1 + u2);
System.out.println(sum.get()); // 55 10、collect方法:收集方法,对于 reduce 和 collect方法个人更喜欢collect的强大。
-
-
collect(Collector collector)执行 mutable reduction操作对元素的使用
Collector流。R collect(Suppliersupplier, BiConsumer 执行该流的元素 mutable reduction操作。
-
collect(Collector c) 将流转换为其他形式,接收一个 Collector接口的实现,用于给Stream中元素做汇总处理。
下面汇总的方法来自:JAVA8之collect总结
| 工厂方法 | 返回类型 | 作用 |
| toList | List |
把流中所有元素收集到List中 |
| 示例:List | ||
| toSet | Set |
把流中所有元素收集到Set中,并删除重复项 |
| 示例:Set | ||
| toCollection | Collection |
把流中所有元素收集到创建的集合中 |
| 示例:ArrayList | ||
| Counting | Long | 计算流中元素的个数 |
| 示例:Long count = Menu.getMenus.stream().collect(counting); | ||
| SummingInt | Integer | 对流中元素的一个整数属性求和 |
| 示例:Integer count = Menu.getMenus.stream().collect(summingInt(Menu::getCalories)) | ||
| averagingInt | Double | 计算流中元素Integer属性的平均值 |
| 示例:Double averaging = Menu.getMenus.stream().collect(averagingInt(Menu::getCalories)) | ||
| summarizingInt | IntSummaryStatistics | 收集流中元素Integer属性的统计值,如:平均值 |
| 示例:IntSummaryStatistics summary = list.stream().collect(Collectors.summarizingInt(Menu::getCalories)); | ||
| Joining | String | 连接流中每个元素的字符串 |
| 示例:String name = Menu.getMenus.stream().map(Menu::getName).collect(joining(“, ”)) | ||
| maxBy | Optional |
根据比较器选出的最大值的optional 如果为空返回的是Optional.empty() |
| 示例:Optional | ||
| minBy | Optional |
根据比较器选出的最小值的的optional 如果为空返回的是Optional.empty() |
| 示例: Optional | ||
| Reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用binaryOperator与流中的元素逐个结合,从而将流归约为单个值 |
| 示例:int count = Menu.getMenus.stream().collect(reducing(0,Menu::getCalories,Integer::sum)); | ||
| collectingAndThen | 转换函数返回的类型 | 包裹另一个转换器,对其结果应用转换函数 |
| 示例:Int count = Menu.getMenus.stream().collect(collectingAndThen(toList(),List::size)) | ||
| groupingBy | Map |
根据流中元素的某个值对流中的元素进行分组,属性值为K, 结果为V |
| 示例:Map |
||
| partitioningBy | Map |
根据流中每个元素应用谓语的结果(true/false)进行分区 |
| 示例:Map |
这里使用几个方法,具体请查看Collectors API。
1. toMap方法:
static |
toMap(Function keyMapper, Function valueMapper) 返回一个 |
static |
toMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction) 返回一个 |
static |
toMap(Function keyMapper, Function valueMapper, BinaryOperator mergeFunction, Supplier 返回一个 |
如果需求使用线程安全的Map,可以用toConcurrentMap、groupingByConcurrent。
使用两个参数
注意:
- 当key重复时,会抛出异常:java.lang.IllegalStateException: Duplicate key *
- 当value为 null 时,会抛出异常:java.lang.NullPointerException
public static void main(String[] args) {
List list = new ArrayList<>();
initList(list);
Map map= list.stream().collect(Collectors.toMap(User::getName, User::getAge));
System.out.println(map); // {妲己=18, 貂蝉=18, 露娜=20, 后裔=20, 赵云=18, 鲁班=9}
}
private static void initList(List list) {
list.add(new User(1, "赵云", "男", 18, 178));
list.add(new User(2, "后裔", "男", 20, 190));
list.add(new User(6, "妲己", "女", 18, 175));
list.add(new User(3, "鲁班", "男", 9, 155));
list.add(new User(8, "貂蝉", "女", 18, 175));
list.add(new User(9, "露娜", "女", 20, 175));
} 使用三个参数
当两个key相同时,只能有一个key存在,那对应的value如何处理? value交由我们自己处理。
// key重复,v覆盖
Map collect = list.stream().collect(Collectors.toMap(User::getSex, user -> user, (oldUser, newUser)->newUser));
System.out.println(collect);
// {女=User{id=1, name='露娜', sex='女', age=20, height=175}, 男=User{id=1, name='鲁班', sex='男', age=9, height=155}}
使用四个参数
mergeFunction和mapSupplier 调用者可以自定义希望返回什么类型的Map
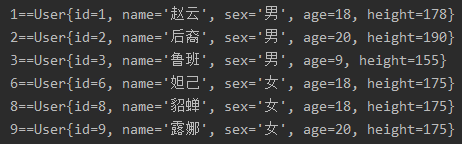
// List转成Map,且保证List的顺序,使用LinedHashMap。
LinkedHashMap linkedHashMap = list.stream()
.sorted(Comparator.comparingInt(User::getId))
.collect(Collectors.toMap(User::getId, user -> user, (oldUser, newUser) -> newUser, LinkedHashMap::new));
linkedHashMap.forEach((k, v) -> {
System.out.println(k + "==" + v);
}); 
2. mapping 方法:
static |
mapping(Function mapper, Collector downstream) 适应 |
// 和中间操作map方法类似
String collect = list.stream().collect(Collectors.mapping(u -> {
return new Float(u.getHeight() / 100 + "." + u.getHeight() % 100).toString();
}, Collectors.joining(",")));
System.out.println(collect); // 1.78,1.9,1.75,1.55,1.75,1.753. maxBy、minBy方法:
static |
maxBy(Comparator comparator) 返回一个 |
static |
minBy(Comparator comparator) 返回一个 |
static |
collectingAndThen(Collector 适应 |
当使用maxBy、minBy统计最值时,结果会封装在Optional中。
如果我们明确结果不可能为null时,可以采用 collectingAndThen函数包裹maxBy、minBy,从而将Optional对象进行转换值。
// age最大
Optional optional = list.stream().collect(Collectors.maxBy((u1, u2) -> {
return u1.getAge() - u2.getAge();
}));
System.out.println(optional);
// age最小
User user = list.stream().collect(Collectors.collectingAndThen(Collectors.minBy((u1, u2) -> {
return u1.getAge() - u2.getAge();
}), Optional::get));
System.out.println(user); 
4. groupBy和groupingByConcurrent方法:
API有几个重载的方法,对数据分组,并且可以无限的分组下去。
注意:groupBy返回的Map,groupingByConcurrent 返回的是 ConcurrentMap。
单字段分组
// 根据性别分组
ConcurrentMap> concurrentMap = list.stream()
.collect(Collectors.groupingByConcurrent(User::getSex));
concurrentMap.forEach((k, v) -> {
System.out.println(k + "==" + v);
}); ![]() 多字段分组
多字段分组
// 根据性别,年龄分组
Map>> map = list.stream()
.collect(Collectors.groupingBy(User::getSex, Collectors.groupingBy(User::getAge)));
map.forEach((k, m) -> {
m.forEach((k2, v) -> {
System.out.println(k + "==" + k2 + "==" + v);
});
}); 
单字段分组并统计
// 根据性别分组并统计个数
Map map = list.stream()
.collect(Collectors.groupingBy(User::getSex, Collectors.counting()));
map.forEach((k, v) -> {
System.out.println(k + "==" + v);
});
==
女==3
男==3 5. partitioningBy方法:分区
static |
partitioningBy(Predicate predicate) 返回一个 |
static |
partitioningBy(Predicate predicate, Collector downstream) 返回一个 |
分区是分组的一种特殊情况,它只能分成true、false两组。
List list = Arrays.asList(1, 2, 3, 4, 5, 5, 5, 6, 9);
Map> partition = list.stream().collect(Collectors.partitioningBy(x -> x >= 4));
System.out.println(partition);
Map>> partition2 = list.stream()
.collect(Collectors.partitioningBy(x -> x >= 4, Collectors.partitioningBy(x -> x > 6)));
System.out.println(partition2);
//也可以结合groupBy等
Map>> collect = list.stream()
.collect(Collectors.partitioningBy(x -> x >= 4, Collectors.groupingBy(x -> x)));
System.out.println(collect); 
7. 生成统计信息的方法
static |
summarizingDouble(ToDoubleFunction mapper) 返回一个 |
static |
summarizingInt(ToIntFunction mapper) 返回一个 |
static |
summarizingLong(ToLongFunction mapper) 返回一个 |
IntSummaryStatistics、LongSummaryStatistics和DoubleSummaryStatistics对象包含的很多统计信息。比如:最值,平均值等。
// 统计list的age信息
IntSummaryStatistics summary = list.stream().collect(Collectors.summarizingInt(User::getAge));
System.out.println(summary.getMax()); // 20
System.out.println(summary.getMin()); // 9
System.out.println(summary.getSum()); // 103
System.out.println(summary.getAverage()); // 17.166666666666668
System.out.println(summary.getCount()); // 6也可以使用 combine方法:将一个IntSummaryStatistics与另一个IntSummaryStatistics组合起来(必须是同一类型)。
-
-
voidaccept(int value)将一个新的值记录到汇总信息中
voidcombine(IntSummaryStatistics other)结合另一个
IntSummaryStatistics状态进入这一。
-
// 统计list的age信息
IntSummaryStatistics summary = list.stream().collect(Collectors.summarizingInt(User::getAge));
// 添加一个age
IntSummaryStatistics summary2 = new IntSummaryStatistics();
summary2.accept(100);
summary.combine(summary2);
System.out.println(summary.getMax()); // 100
System.out.println(summary.getMin()); // 9
System.out.println(summary.getSum()); // 203
System.out.println(summary.getAverage()); // 29.0
System.out.println(summary.getCount()); // 7
Stream 结合Lambda表达式,函数式接口等操作,使代码简洁,优雅,对数据的处理更加灵活。在开发中推荐使用。
参考文章:
谈谈并行流parallelStream
Java 8系列之Stream的基本语法详解
—— Stay Hungry. Stay Foolish. 求知若饥,虚心若愚。