面试官:谈一谈你对 redis 分布式锁的理解

为什么需要分布式锁
在 jdk 中为我们提供了多种加锁的方式:
(1)synchronized 关键字
(2)volatile + CAS 实现的乐观锁
(3)ReadWriteLock 读写锁
(4)ReenTrantLock 可重入锁
等等,这些锁为我们变成提供极大的便利性,保证在多线程的情况下,保证线程安全。
但是在分布式系统中,上面的锁就统统没用了。
我们想要解决分布式系统中的并发问题,就需要引入分布式锁的概念。
锁的准则
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。
在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。
即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。
只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。
加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
-
具备可重入特性;
-
具备非阻塞锁特性;
即没有获取到锁将直接返回获取锁失败。
- 高性能 & 高可用
多快好省一直使我们追求的目标,加锁带来的时间消耗太大,肯定使我们不想见到的。
- 锁的公平性
避免饱汉子不知饿汉子饥,饿汉子不知饱汉子虚。保证锁的公平性也比较重要。
分布式锁的实现方式多种多样,此处选择比较流行的 redis 进行我们的 redis 锁实现。
单机版 Redis 的实现
我们首先来看一下 antirez 的实现 RedLock,这个也是一种流传比较广泛的版本。
antirez 是谁?
是 redis 的作者,那么一个写 redis 的,真的懂锁吗?
加锁的实现
只需要下面的一条命令:
SET resource_name my_random_value NX PX 30000
看起来非常简单,但是其中还是有很多学问的。
setnx
其实目前通常所说的setnx命令,并非单指redis的 setnx key value 这条命令。
一般代指redis中对set命令加上nx参数进行使用 set 这个命令,目前已经支持这么多参数可选:
SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]
主要依托了它的key不存在才能set成功的特性,个人理解类似于 putIfAbsent
PX 30000
为什么需要设置过期时间?
根据墨菲定律,如果一件事情可能发生,那么他就一定会发生。
如果当前锁的持有者挂掉了,他持有的锁永远也无法释放,那岂不是太悲剧了。
于是我们设定一个过期时间,让 redis 为我们做一次兜底工作。
一般这个超时时间可以根据自己的业务灵活调整,大部分都不会超过 10min。
真正的高并发,如果锁住了 10min,带来的经济损失也是比较客观的。但是总比一直锁住强的太多。
my_random_value 有什么用
细心的同学一定发现了这里的 value 是一个 my_random_value,一个随机值。
这个值是用来做什么的?
其实这个值是一种标识,最大的作用就是解铃还须系铃人。
不能你在洗手间锁上门,准备解放身心的时候,别人直接把门打开了,这样不就乱了套了。
我们可以让一个线程持有唯一的标识,这样在解锁的时候就知道这个锁是属于自己的,大家井然有序,社会和平美好。
释放锁的实现
在完成操作之后,通过以下Lua脚本来释放锁:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1])else return 0end
保证是锁的持有者
这里是先确认资源对应的value与客户端持有的value是否一致,如果一致的话就释放锁。
保证原子性
注意上面的脚本是通过 lua 脚本实现的,必须是一个原子性操作。
- eval 的原子性
Atomicity of scriptsRedis uses the same Lua interpreter to run all the commands. Also Redis guarantees that a script is executed in an atomic way: no other script or Redis command will be executed while a script is being executed. This semantic is similar to the one of MULTI / EXEC. From the point of view of all the other clients the effects of a script are either still not visible or already completed.However this also means that executing slow scripts is not a good idea. It is not hard to create fast scripts, as the script overhead is very low, but if you are going to use slow scripts you should be aware that while the script is running no other client can execute commands.
直接翻译:
脚本的原子性Redis使用相同的Lua解释器来运行所有命令。 另外,Redis保证以原子方式执行脚本:执行脚本时不会执行其他脚本或Redis命令。 这种语义类似于MULTI / EXEC中的一种。 从所有其他客户端的角度来看,脚本的效果还是不可见或已经完成。但是,这也意味着执行慢速脚本不是一个好主意。 创建快速脚本并不难,因为脚本开销非常低,但是如果要使用慢速脚本,则应注意,在脚本运行时,没有其他客户端可以执行命令。
java 代码的实现
maven 引入
redis.clients jedis ${jedis.version}
获取锁
/** * 尝试获取分布式锁 * * expireTimeMills 保证当前进程挂掉,也能释放锁 * * requestId 保证解锁的是当前进程(锁的持有者) * * @param lockKey 锁 * @param requestId 请求标识 * @param expireTimeMills 超期时间 * @return 是否获取成功 * @since 0.0.1 */@Overridepublic boolean lock(String lockKey, String requestId, int expireTimeMills) { String result = jedis.set(lockKey, requestId, LockRedisConst.SET_IF_NOT_EXIST, LockRedisConst.SET_WITH_EXPIRE_TIME, expireTimeMills); return LockRedisConst.LOCK_SUCCESS.equals(result);}
释放锁
/** * 解锁 * * (1)使用 requestId,保证为当前锁的持有者 * (2)使用 lua 脚本,保证执行的原子性。 * * @param lockKey 锁 key * @param requestId 请求标识 * @return 结果 * @since 0.0.1 */@Overridepublic boolean unlock(String lockKey, String requestId) { String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId)); return LockRedisConst.RELEASE_SUCCESS.equals(result);}
完整代码:https://github.com/houbb/lock
RedLock
看到这里,你是不是觉得上面的实现已经很完美了?
但是遗憾的是,上面的实现有一个致命的缺陷,那就是单点问题。
当锁服务所在的redis节点宕机时,会导致锁服务不可用,数据恢复之后可能会丢失部分锁数据。
为了解决明显的单点问题,antirez 设计提出了RedLock算法。
antirez 是何许人也?
如果你知道 redis,你就应该知道他。
实现步骤
RedLock的实现步骤可以看成下面几步:
-
获取当前时间t1,精确到毫秒;
-
依次向锁服务所依赖的N个节点发送获取锁的请求,加锁的操作和上面单节点的加锁操作请求相同;
-
如果获取了超过半数节点的资源锁(>=N/2+1),则计算获取锁所花费的时间,计算方法是用当前时间t2减去t1,如果花费时间小于锁的过期时间,则成功的获取了锁;
-
这时锁的实际有效时间是设置的有效时间t0减去获取锁花费的时间(t2-t1);
-
如果在第3步没有成功的获取锁,需要向所有的N个节点发送释放锁的请求,释放锁的操作和上面单节点释放锁操作一致;
由于引入了多节点的redis集群,RedLock的可用性明显是大于单节点的锁服务的。
节点故障重启
这里需要说明一个节点故障重启的例子:
-
client1向5个节点请求锁,获取了a,b,c上的锁;
-
b节点故障重启,丢失了client1申请的锁;
-
client2向5个节点请求锁,获取了b,d,e上的锁;
这里例子中,从客户端角度来看,有两个客户端合法的在同一时间都持有同一资源的锁,关于这个问题,antirez提出了延迟重启(delayed restarts)的概念:在节点宕机之后,不要立即重启恢复服务,而是至少经过一个完整锁有效周期之后再启动恢复服务,这样可以保证节点因为宕机而丢失的锁数据一定因为过期而失效。
接下来就是比较有趣的部分了。
Martin Flower 的分析
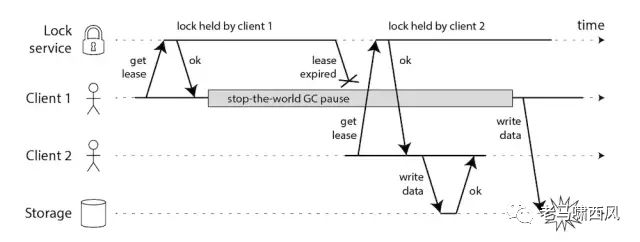
Martin Flower 首先说明,在没有fencing token的保证之下,锁服务可能出现的问题,他给出了下面的图:
Martin Flower 又是谁?
被称为软件开发教父的男人。以前拜读过其写的《重构》一书,确实厉害。
不怕大佬有文化,就怕大佬会说话。我们天天吹的微服务,就是 Matrin 大佬提出的。

客户端停顿导致锁失效
上图说明的问题可以描述成下面的步骤:
-
client1成功获取了锁,之后陷入了长时间GC中,直到锁过期;
-
client2在client1的锁过期之后成功的获取了锁,并去完成数据操作;
-
client1从GC中恢复,从它本身的角度来看,并不会意识到自己持有的锁已经过期,去操作数据;
从上面的例子看出,这里的锁服务提供了完整的互斥锁语义保证,从资源的角度来看,两次操作都是合法的。
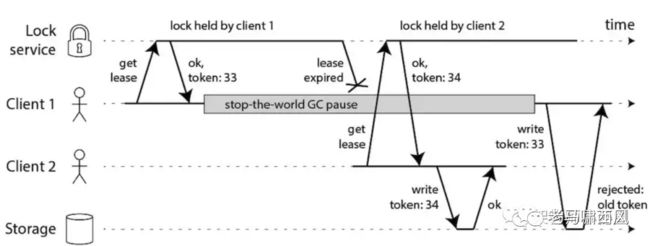
上面提到,RedLock根据随机字符串来作为单次锁服务的token,这就意味着对于资源而言,无法根据锁token来区分client持有的锁所获取的先后顺序。
为此,Martin引入了fencing token机制,fencing token可以理解成采用全局递增的序列替代随机字符串,作为锁token来使用。
这样就可以从资源侧确定client所携带锁的获取先后顺序了。
大佬就是大佬,张口就来 GC。
GC 对于 java go 这种语言大家肯定不陌生,对于写 C/C++ 的开发者肯定很少接触。
fencing token机制
除了没有fencing机制保证之外,Martin还指出,RedLock依赖时间同步不同节点之间的状态这种做法有问题。
具体可以看个例子:
-
client1获取节点a,b,c上的锁;
-
节点c由于时间同步,发生了时钟漂移,时钟跳跃导致client1获取的锁失效;
-
client2获取节点c,d,e上的锁;
本质上来看,RedLock通过不同节点的时钟来进行锁状态的同步。
而在分布式系统中,物理时钟本身就有可能出现问题,也就是说,RedLock的安全性保证建立在物理时钟没问题的假设上。
分布式系统中不同节点的协调一般不使用物理时钟作为度量,相应的,Lamport提出逻辑时钟作为分布式事件先后顺序的度量。
引入锁的目的
Martin还指出,引入锁的主要目的无非以下两个:
-
为了资源效率,避免不必要的重复昂贵计算;
-
为了正确性,保证数据正确;
对于第一点而言,采用单redis节点的锁就可以满足需求;对于第二点而言,则需要借助更严肃的分布式协调系统(如zookeeper,etcd,consul等等)。
antirez 的反驳
在Martin发表自己对RedLock的分析之后,antirez也发表了自己的反驳。
针对Martin提出的两点质疑,antirez分别提出反驳:
-
首先,antirez认为在RedLock中,虽然没有用到fencing保证机制,但是随机字符串token也可以提供client到具体锁的匹配映射;
-
其次,antirez认为分布式系统中的物理时钟可以通过良好的运维来保证;

个人理解
关于第一点,随机的 token 确实可以和客户端做映射。但是这并没有什么卵用,除非我们再多加一个字段,标识时间或者是顺序。
如果这么做,不如直接使用一个 fetching token。
关于第二点,将开发的锅直接推到运维头上了,也不是不可以,可惜大部分的现实情况总是没有那么美好。
不过随着云技术的兴起,也许有一天所有的应用都在云上,然后各大云厂商统一运维,也不是不能解决这个问题。
但是 antirez 的反驳确实没有说服我,所以我选择 —— Matrin 的简化版本。

一种实现方案
整体思路
我们在 antirez 的基础上做一点点改进,引入 Matrin 提出的 fetching token 来解决 GC 的问题。
加锁
client先获取一个fencing token,携带fencing token去获取资源相关的锁,这时出现两种情况:
-
锁已被占用,且锁的fencing token大于此时client的fencing token,这种情况的主要原因是client在获取fencing token之后出现了长时间GC;
-
锁已被占用,且锁的fencing token小于此时的client的fencing token,这种情况就是之前有其他客户端成功持有了锁且还没有释放(这里的释放包括client主动释放和锁超时之后的被动释放);
-
锁未被占用,成功加锁;
解锁
解锁和 antirez 的方案类似,直接采用 lua 脚本释放。
对于锁的持有者也是大同小异。
不足
当然这个方案的优点是可以解决 GC 问题,缺点依然比较明显,就是无法解决 redis 单点问题。
不过我个人的工作经验中,redis 一般都是采用集群的方式,所以单点问题并没有那么严重。
就像我们平时存储分布式 session 一样。
当然,问题还是要面对的,解决方案也是有的。
其他方案
数据库实现 https://houbb.github.io/2018/09/08/distributed-lock-sql
zookeeper 实现 https://houbb.github.io/2018/09/08/distributed-lock-zookeeper
只不过性能和维护的复杂度,这些问题都需要我们去权衡。
