【转】爬虫的几种方法的效率比较
该文非原创文字,文字转载至 jclian91 链接:https://www.cnblogs.com/jclian91/p/9799697.html
问题的由来
前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何利用爬虫来实现如下的需求,需要爬取的网页如下(网址为:https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0):
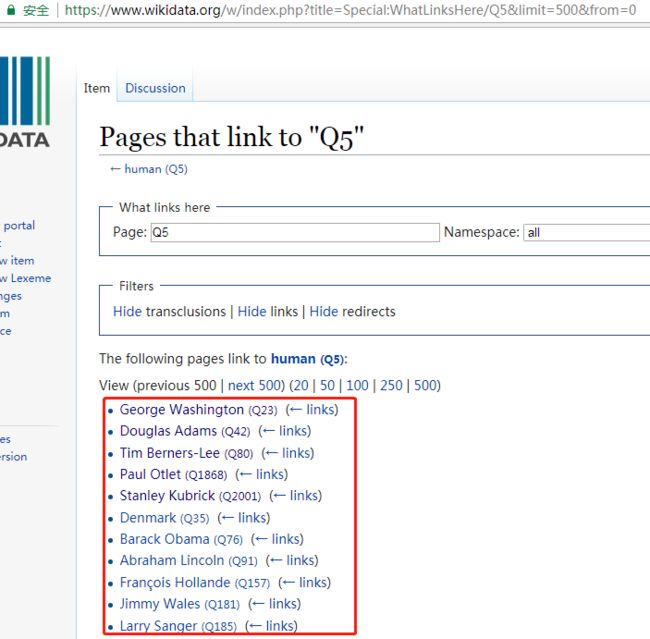
我们的需求为爬取红色框框内的名人(有500条记录,图片只展示了一部分)的 名字以及其介绍,关于其介绍,点击该名人的名字即可,如下图:
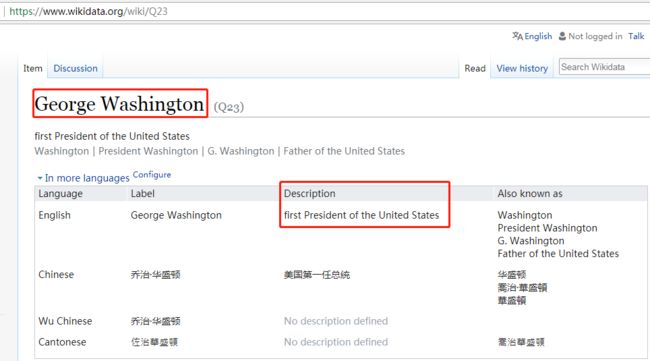
这就意味着我们需要爬取500个这样的页面,即500个HTTP请求(暂且这么认为吧),然后需要提取这些网页中的名字和描述,当然有些不是名人,也没有描述,我们可以跳过。最后,这些网页的网址在第一页中的名人后面可以找到,如George Washington的网页后缀为Q23.
爬虫的需求大概就是这样。
爬虫的N中姿势
首先,分析来爬虫的思路:先在第一个网页(https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0)中得到500个名人所在的网址,接下来就爬取这500个网页中的名人的名字及描述,如无描述,则跳过。
接下来,我们将介绍实现这个爬虫的4种方法,并分析它们各自的优缺点,希望能让读者对爬虫有更多的体会。实现爬虫的方法为:
- 一般方法(同步,requests+BeautifulSoup)
- 并发(使用concurrent.futures模块以及requests+BeautifulSoup)
- 异步(使用aiohttp+asyncio+requests+BeautifulSoup)
- 使用框架Scrapy
一般方法
一般方法即为同步方法,主要使用requests+BeautifulSoup,按顺序执行。完整的Python代码如下:
import requests
from bs4 import BeautifulSoup
import time
# 开始时间
t1 = time.time()
print('#' * 50)
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org'+url)
# 获取每个网页的name和description
def parser(url):
req = requests.get(url)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(req.text, "lxml")
# 获取name和description
name = soup.find('span', class_="wikibase-title-label")
desc = soup.find('span', class_="wikibase-descriptionview-text")
if name is not None and desc is not None:
print('%-40s,\t%s'%(name.text, desc.text))
for url in urls:
parser(url)
t2 = time.time() # 结束时间
print('一般方法,总共耗时:%s' % (t2 - t1))
print('#' * 50)输出的结果如下(省略中间的输出,以......代替):
##################################################
George Washington , first President of the United States
Douglas Adams , British author and humorist (1952–2001)
......
Willoughby Newton , Politician from Virginia, USA
Mack Wilberg , American conductor
一般方法,总共耗时:724.9654655456543
##################################################使用同步方法,总耗时约725秒,即12分钟多。
一般方法虽然思路简单,容易实现,但效率不高,耗时长。那么,使用并发试试看。
并发方法
并发方法使用多线程来加速一般方法,我们使用的并发模块为concurrent.futures模块,设置多线程的个数为20个(实际不一定能达到,视计算机而定)。完整的Python代码如下:
import requests
from bs4 import BeautifulSoup
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 开始时间
t1 = time.time()
print('#' * 50)
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org'+url)
# 获取每个网页的name和description
def parser(url):
req = requests.get(url)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(req.text, "lxml")
# 获取name和description
name = soup.find('span', class_="wikibase-title-label")
desc = soup.find('span', class_="wikibase-descriptionview-text")
if name is not None and desc is not None:
print('%-40s,\t%s'%(name.text, desc.text))
# 利用并发加速爬取
executor = ThreadPoolExecutor(max_workers=20)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
t2 = time.time() # 结束时间
print('并发方法,总共耗时:%s' % (t2 - t1))
print('#' * 50)输出的结果如下(省略中间的输出,以......代替):
##################################################
Larry Sanger , American former professor, co-founder of Wikipedia, founder of Citizendium and other projects
Ken Jennings , American game show contestant and writer
......
Antoine de Saint-Exupery , French writer and aviator
Michael Jackson , American singer, songwriter and dancer
并发方法,总共耗时:226.7499692440033
##################################################使用多线程并发后的爬虫执行时间约为227秒,大概是一般方法的三分之一的时间,速度有了明显的提升啊!多线程在速度上有明显提升,但执行的网页顺序是无序的,在线程的切换上开销也比较大,线程越多,开销越大。
关于多线程与一般方法在速度上的比较,可以参考文章:Python爬虫之多线程下载豆瓣Top250电影图片。
异步方法
异步方法在爬虫中是有效的速度提升手段,使用aiohttp可以异步地处理HTTP请求,使用asyncio可以实现异步IO,需要注意的是,aiohttp只支持3.5.3以后的Python版本。使用异步方法实现该爬虫的完整Python代码如下:
import requests
from bs4 import BeautifulSoup
import time
import aiohttp
import asyncio
# 开始时间
t1 = time.time()
print('#' * 50)
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org'+url)
# 异步HTTP请求
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
# 解析网页
async def parser(html):
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(html, "lxml")
# 获取name和description
name = soup.find('span', class_="wikibase-title-label")
desc = soup.find('span', class_="wikibase-descriptionview-text")
if name is not None and desc is not None:
print('%-40s,\t%s'%(name.text, desc.text))
# 处理网页,获取name和description
async def download(url):
async with aiohttp.ClientSession() as session:
try:
html = await fetch(session, url)
await parser(html)
except Exception as err:
print(err)
# 利用asyncio模块进行异步IO处理
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(download(url)) for url in urls]
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
t2 = time.time() # 结束时间
print('使用异步,总共耗时:%s' % (t2 - t1))
print('#' * 50)输出结果如下(省略中间的输出,以......代替):
##################################################
Frédéric Taddeï , French journalist and TV host
Gabriel Gonzáles Videla , Chilean politician
......
Denmark , sovereign state and Scandinavian country in northern Europe
Usain Bolt , Jamaican sprinter and soccer player
使用异步,总共耗时:126.9002583026886
##################################################显然,异步方法使用了异步和并发两种提速方法,自然在速度有明显提升,大约为一般方法的六分之一。异步方法虽然效率高,但需要掌握异步编程,这需要学习一段时间。
关于异步方法与一般方法在速度上的比较,可以参考文章:利用aiohttp实现异步爬虫。
如果有人觉得127秒的爬虫速度还是慢,可以尝试一下异步代码(与之前的异步代码的区别在于:仅仅使用了正则表达式代替BeautifulSoup来解析网页,以提取网页中的内容):
import requests
from bs4 import BeautifulSoup
import time
import aiohttp
import asyncio
import re
# 开始时间
t1 = time.time()
print('#' * 50)
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org' + url)
# 异步HTTP请求
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
# 解析网页
async def parser(html):
# 利用正则表达式解析网页
try:
name = re.findall(r'(.+?)', html)[0]
desc = re.findall(r'(.+?)', html)[0]
print('%-40s,\t%s' % (name, desc))
except Exception as err:
pass
# 处理网页,获取name和description
async def download(url):
async with aiohttp.ClientSession() as session:
try:
html = await fetch(session, url)
await parser(html)
except Exception as err:
print(err)
# 利用asyncio模块进行异步IO处理
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(download(url)) for url in urls]
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
t2 = time.time() # 结束时间
print('使用异步(正则表达式),总共耗时:%s' % (t2 - t1))
print('#' * 50)输出的结果如下(省略中间的输出,以......代替):
##################################################
Dejen Gebremeskel , Ethiopian long-distance runner
Erik Kynard , American high jumper
......
Buzz Aldrin , American astronaut
Egon Krenz , former General Secretary of the Socialist Unity Party of East Germany
使用异步(正则表达式),总共耗时:16.521944999694824
##################################################16.5秒,仅仅为一般方法的43分之一,速度如此之快,令人咋舌(感谢某人提供的尝试)。笔者虽然自己实现了异步方法,但用的是BeautifulSoup来解析网页,耗时127秒,没想到使用正则表达式就取得了如此惊人的效果。可见,BeautifulSoup解析网页虽然快,但在异步方法中,还是限制了速度。但这种方法的缺点为,当你需要爬取的内容比较复杂时,一般的正则表达式就难以胜任了,需要另想办法。
爬虫框架Scrapy
最后,我们使用著名的Python爬虫框架Scrapy来解决这个爬虫。我们创建的爬虫项目为wikiDataScrapy,项目结构如下:
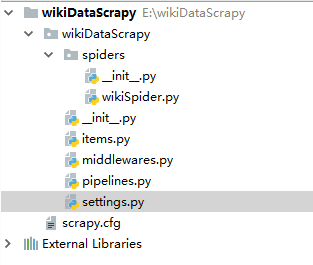
在settings.py中设置“ROBOTSTXT_OBEY = False”. 修改items.py,代码如下:
# -*- coding: utf-8 -*-
import scrapy
class WikidatascrapyItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
desc = scrapy.Field()然后,在spiders文件夹下新建wikiSpider.py,代码如下:
import scrapy.cmdline
from wikiDataScrapy.items import WikidatascrapyItem
import requests
from bs4 import BeautifulSoup
# 获取请求的500个网址,用requests+BeautifulSoup搞定
def get_urls():
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org' + url)
# print(urls)
return urls
# 使用scrapy框架爬取
class bookSpider(scrapy.Spider):
name = 'wikiScrapy' # 爬虫名称
start_urls = get_urls() # 需要爬取的500个网址
def parse(self, response):
item = WikidatascrapyItem()
# name and description
item['name'] = response.css('span.wikibase-title-label').xpath('text()').extract_first()
item['desc'] = response.css('span.wikibase-descriptionview-text').xpath('text()').extract_first()
yield item
# 执行该爬虫,并转化为csv文件
scrapy.cmdline.execute(['scrapy', 'crawl', 'wikiScrapy', '-o', 'wiki.csv', '-t', 'csv'])输出结果如下(只包含最后的Scrapy信息总结部分):
{'downloader/request_bytes': 166187,
'downloader/request_count': 500,
'downloader/request_method_count/GET': 500,
'downloader/response_bytes': 18988798,
'downloader/response_count': 500,
'downloader/response_status_count/200': 500,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 10, 16, 9, 49, 15, 761487),
'item_scraped_count': 500,
'log_count/DEBUG': 1001,
'log_count/INFO': 8,
'response_received_count': 500,
'scheduler/dequeued': 500,
'scheduler/dequeued/memory': 500,
'scheduler/enqueued': 500,
'scheduler/enqueued/memory': 500,
'start_time': datetime.datetime(2018, 10, 16, 9, 48, 44, 58673)}可以看到,已成功爬取500个网页,耗时31秒,速度也相当OK。再来看一下生成的wiki.csv文件,它包含了所有的输出的name和description,如下图:
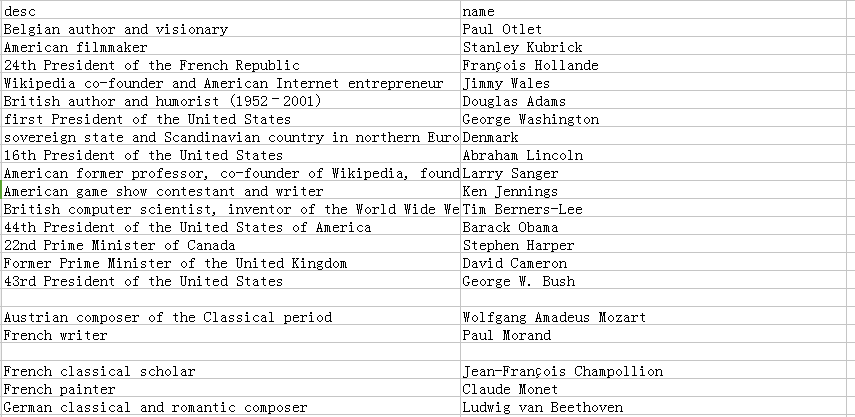
可以看到,输出的CSV文件的列并不是有序的。至于如何解决Scrapy输出的CSV文件有换行的问题,请参考stackoverflow上的回答:https://stackoverflow.com/questions/39477662/scrapy-csv-file-has-uniform-empty-rows/43394566#43394566 。
Scrapy来制作爬虫的优势在于它是一个成熟的爬虫框架,支持异步,并发,容错性较好(比如本代码中就没有处理找不到name和description的情形),但如果需要频繁地修改中间件,则还是自己写个爬虫比较好,而且它在速度上没有超过我们自己写的异步爬虫,至于能自动导出CSV文件这个功能,还是相当实在的。
总结
本文内容较多,比较了4种爬虫方法,每种方法都有自己的利弊,已在之前的陈述中给出,当然,在实际的问题中,并不是用的工具或方法越高级就越好,具体问题具体分析嘛~