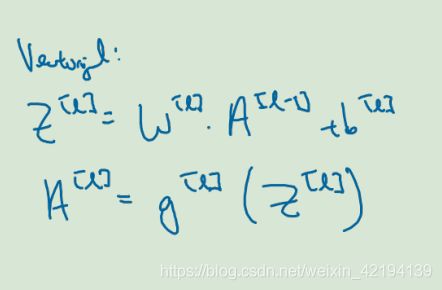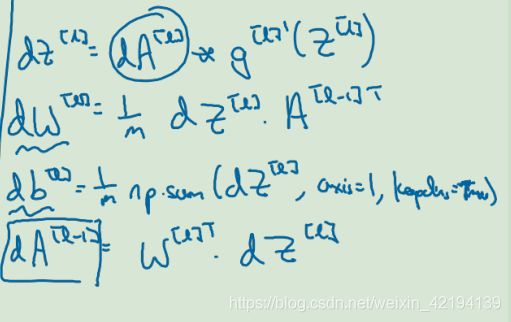吴恩达神经网络和深度学习笔记
Python广播运算
cal=A.sum(axis=0)矩阵A竖直相加,每一列相加,如果axis=1就是每一行求和
用reshape指令来确定矩阵的形式,如果不是非常清楚矩阵的行列的话,用reshape自己定义一下
用一个m*n的矩阵加减乘除一个1*n的矩阵,Python会把后者复制成一个m*n的矩阵,然后逐个元素计算
避免Python程序和NUMPY出现bug的方法:
1.避免使用秩为1的定义,如a=np.random.randn(5),用a=np.random.randn(5,1)代替。前者为秩为1的数组,后者为列向量。5行1列。
2.多使用类似assert(a.shape=(5,1))这种声明。
激活函数:
1.tanh函数要优于sigmoid函数。一般场合tanh函数要优于sigmoid函数,输出层有例外。
2.如果做二元分类,输出不是0就是1,那么输出层使用sigmoid激活函数比较好,然后其他层激活函数都是用ReLU激活函数,又叫线性修正单元。
3.隐藏层激活函数最好默认选择ReLU函数。
为什么要使用非线性激活函数:
如果使用线性激活函数,最终输出时x的线性组合,所有的隐藏层失去了作用。
一般情况只有输出层使用线性激活函数,隐藏层使用非线性激活函数。
梯度下降:
随机初始化参数:
不要将W初始化为0,因为这样不管迭代多少次,所有的隐藏单元都在做同样的事情,都在计算同一个函数。
一般将W初始化成很小的值,可以使用np.random.randn()*0.01来初始化W,b不影响,可以初始化为0.
第三周编程作业笔记:
红色点label=0,蓝色点label=1;
向量X里面包含特征(x1,x2),Y里面标签(red0,blue1);
The shape of X is: (2, 400)
The shape of Y is: (1, 400)
I have m = 400 training examples!Reminder: The general methodology to build a Neural Network is to:
1. Define the neural network structure ( # of input units, # of hidden units, etc).
2. Initialize the model's parameters
3. Loop:
- Implement forward propagation
- Compute loss
- Implement backward propagation to get the gradients
- Update parameters (gradient descent)
W的维度【后一层神经元个数,前一层神经元个数】
W(l)=[n(l),n(l-1)] b(l)=[n(l),1]
反向传播中,dW的维度和W的维度保持一致,db的维度和b的维度保持一致
Z(l)=[n(l),m] m表示训练集大小 A(l)的维度和 Z(l)的维度保持一致 dZ和dA的维度和Z、A的维度是一样的
X=[n(0),m] m表示训练集的大小
A(l)