简单阐述python多线程
python多线程
python中创建多线程方法有两种,这里只介绍简单的一种:
from threading import Thread #导入模块
import time
def test(thread_num): #线程需要执行的函数
print('线程%d:aaaaaaa' % thread_num)
time.sleep(2)
print('线程%d:bbbbbbb' % thread_num )
time.sleep(2)
print('线程%d:ccccccc' % thread_num)
if __name__ == '__main__':
print('主线程开启...')
#创建线程,target表示线程需要执行的函数,args表示函数的参数,必须是元组形式
t1 = Thread(target=test, args=(1,))
t2 = Thread(target=test, args=(2,))
t1.start() #线程t1就绪
t2.start() #线程t2就绪
t1.join()#主线程等待线程t1结束
t2.join() #主线程等待线程t2结束
print('主线程结束...')
这是运行两次的结果:
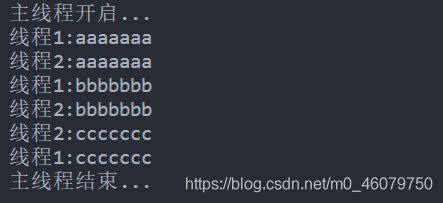
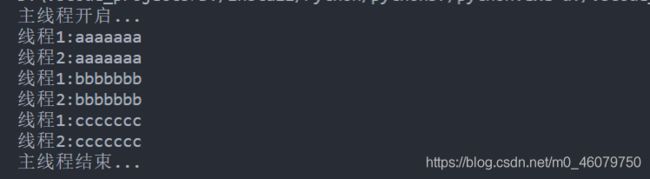
执行
start方法后,表明线程以准备就绪,但还没开始执行,具体什么时间执行由cpu决定。
可以看到,打印 ccccccc 的时候,第一次是线程2先执行,第二次是线程1先执行,实际上这是随机的,是由操作系统自己决定哪个线程先执行的。
线程锁
当多个线程同时对某个数据进行修改的时候,就会导致数据结果与预期不符,例如,
from threading import Thread
money = 0
def change_money(n=300000):
global money
for i in range(n): #进行30万次 +1 操作
money += 1
t1 = Thread(target=change_money, args=())
t2 = Thread(target=change_money, args=())
if __name == '__main__':
t1.start()
t2.start()
t1.join()
t2.join()
print('money:',money)
该程序即是对 money 全局变量进行30万次 +1 操作,由于是有2个线程,按道理总共是操作了60万次,因此结果应该是 600000,但是,运行3次的输出却是:
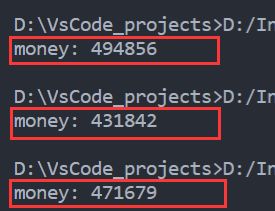
明显与预期不符,为什么会这样,因为 money += 1 这条语句在程序执行起来实际上是有2步操作的,第一步是计算 money + 1,第二步是把计算的结果赋值给变量 money。
然而,当我们开启了多个线程后,可能某个线程只执行了第一步,还未执行第二步,数据就被另一个线程拿去使用了。如果这些线程执行的次数很少,可能不会出问题,但是执行几十万、几百万次这种操作时,就会出现这样的状况。
因此为了避免这种状况发生,可以给数据上锁,将数据锁起来,由于锁只有一个,某个线程获得了锁后,另一个线程就必须等待这个线程把锁释放,然后所有线程公平竞争获取这个锁。线程获得锁后,在释放锁前把计算和赋值这两步操作都执行了,这样就不会出错了。
例如:
from threading import Thread, Lock
money = 0
def change_money(n=500000):
global money
for i in range(n):
lock.acquire() #获得锁
money += 1
lock.release() #操作完成,释放锁
t1 = Thread(target=change_money, args=())
t2 = Thread(target=change_money, args=())
lock = Lock() #首先创建锁
t1.start()
t2.start()
t1.join()
t2.join()
print('money:',money)
这是运行3次的结果:
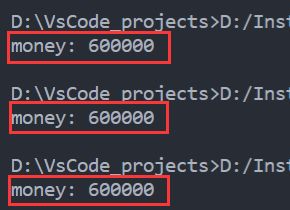
可以看到,没有出错。
时间问题
假设对 money执行 6 次 +1 操作,每操作一次等待 2 秒,最后共耗费多少时间?
在没学过线程之前,也就是执行时只采用一个线程,按道理最后耗时大概是 12秒,实际上也是这样,此处不再写代码了,可以自己试一下。
学了多线程后,可以采用2个线程,每个线程操作 3 次,理论上耗时 6秒,看下这个代码:
from threading import Thread, Lock
import time
money = 0
def change_money(n=3):
global money
for i in range(n):
lock.acquire()
money += 1
time.sleep(2) #等待2秒
lock.release()
t1 = Thread(target=change_money, args=())
t2 = Thread(target=change_money, args=())
lock = Lock()
time1 = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
time2 = time.time()
print('money:',money)
print('耗时:{}'.format(time2 - time1))
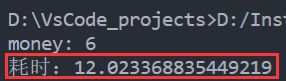
输出耗时12秒,怎么回事,不急,再看下面这个代码(在上面这个代码基础上稍微改动一下):
from threading import Thread, Lock
import time
money = 0
def change_money(n=3):
global money
for i in range(n):
lock.acquire()
money += 1
lock.release()
time.sleep(2) #等待2秒
t1 = Thread(target=change_money, args=())
t2 = Thread(target=change_money, args=())
lock = Lock()
time1 = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
time2 = time.time()
print('money:',money)
print('耗时:{}'.format(time2 - time1))
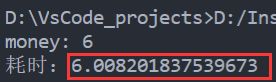
这时输出为 6秒, 倒是跟理论值符合。比较这两个代码,只有 11和12行有改动,第一个是先等待2秒,再释放锁;第二个是先释放锁,再等待2秒,问题关键就在于这个锁。
因为锁只有一个,锁在释放前其他所有未获得锁的线程都会等待锁的释放,即锁在释放前只能有一个线程执行,而
time.sleep(2)这句代码放在lock.release()前的时候,因为有2个线程,每个线程操作3次,因此耗时2 * 3 * 2 = 12秒;
但是当
lock.release()这句代码放在time.sleep(2)前的时候,即先释放锁,再等待,由于释放了锁后,释放锁的线程在等待2秒,而另一个线程立即获取锁,然后进行计算操作,由于计算操作的时间很快,可忽略不计,最后就会出现2个线程都在同时(可以认为是同时)执行等待2秒这个操作,因此最后实际上只耗费了一个线程的时间3 * 2 = 6秒