win10+maskrcnn-benchmark+cocodataset+GPU
windows不能让maskrcnn-benchmark跑自己的训练集吗?不可能的,都是操作系统,只是网上的资料都是在Linux下面搞的。
首先声明:显存2G或者内存小于12G的滚一边去,嗯,我的就是显存2G的,一个同学4G的显存8G的内存显示内存不够,给他加了一个4G的内存条后没有显示显存不够,也没有显示内存不够,就是报了个index out of range的错误,我也不知道为什么
数据集准备
COCO数据集,自己的数据集也行,但是我没试过,可以看其它文章,虽然他们都是Linux的,但是,都是操作系统,有什么区别,数据集优先下载val2017、train2017和2017 Train/Val annotations,其它的就挂在那里下载吧,指不定什么时候要用
修改.yaml文件
这个肯定是要修改的,怎么改你们自己搞,用哪个也自己搞,但是
DATASETS:
TRAIN: ("coco_2014_train", "coco_2014_valminusminival")
TEST: ("coco_2014_minival",)这个是必须要改的,因为它规定了你用的是哪个训练集和测试集,而里面写的coco_2014_train、coco_2014_valminusminival、coco_2014_minival来自/maskrcnn_benchmark/config/paths_catalog.py,代码如下
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
"""Centralized catalog of paths."""
import os
class DatasetCatalog(object):
DATA_DIR = "datasets"
DATASETS = {
"coco_2017_train": {
"img_dir": "coco/train2017",
"ann_file": "coco/annotations/instances_train2017.json"
},
"coco_2017_val": {
"img_dir": "coco/val2017",
"ann_file": "coco/annotations/instances_val2017.json"
},
"coco_2014_train": {
"img_dir": "coco/train2014",
"ann_file": "coco/annotations/instances_train2014.json"
},
"coco_2014_val": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_val2014.json"
},
"coco_2014_minival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_minival2014.json"
},
"coco_2014_valminusminival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/instances_valminusminival2014.json"
},
"keypoints_coco_2014_train": {
"img_dir": "coco/train2014",
"ann_file": "coco/annotations/person_keypoints_train2014.json",
},
"keypoints_coco_2014_val": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_val2014.json"
},
"keypoints_coco_2014_minival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_minival2014.json",
},
"keypoints_coco_2014_valminusminival": {
"img_dir": "coco/val2014",
"ann_file": "coco/annotations/person_keypoints_valminusminival2014.json",
},
"voc_2007_train": {
"data_dir": "voc/VOC2007",
"split": "train"
},
"voc_2007_train_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_train2007.json"
},
"voc_2007_val": {
"data_dir": "voc/VOC2007",
"split": "val"
},
"voc_2007_val_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_val2007.json"
},
"voc_2007_test": {
"data_dir": "voc/VOC2007",
"split": "test"
},
"voc_2007_test_cocostyle": {
"img_dir": "voc/VOC2007/JPEGImages",
"ann_file": "voc/VOC2007/Annotations/pascal_test2007.json"
},
"voc_2012_train": {
"data_dir": "voc/VOC2012",
"split": "train"
},
"voc_2012_train_cocostyle": {
"img_dir": "voc/VOC2012/JPEGImages",
"ann_file": "voc/VOC2012/Annotations/pascal_train2012.json"
},
"voc_2012_val": {
"data_dir": "voc/VOC2012",
"split": "val"
},
"voc_2012_val_cocostyle": {
"img_dir": "voc/VOC2012/JPEGImages",
"ann_file": "voc/VOC2012/Annotations/pascal_val2012.json"
},
"voc_2012_test": {
"data_dir": "voc/VOC2012",
"split": "test"
# PASCAL VOC2012 doesn't made the test annotations available, so there's no json annotation
},
"cityscapes_fine_instanceonly_seg_train_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_train.json"
},
"cityscapes_fine_instanceonly_seg_val_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_val.json"
},
"cityscapes_fine_instanceonly_seg_test_cocostyle": {
"img_dir": "cityscapes/images",
"ann_file": "cityscapes/annotations/instancesonly_filtered_gtFine_test.json"
}
}
@staticmethod
def get(name):
if "coco" in name:
data_dir = DatasetCatalog.DATA_DIR
attrs = DatasetCatalog.DATASETS[name]
args = dict(
root=os.path.join(data_dir, attrs["img_dir"]),
ann_file=os.path.join(data_dir, attrs["ann_file"]),
)
return dict(
factory="COCODataset",
args=args,
)
elif "voc" in name:
data_dir = DatasetCatalog.DATA_DIR
attrs = DatasetCatalog.DATASETS[name]
args = dict(
data_dir=os.path.join(data_dir, attrs["data_dir"]),
split=attrs["split"],
)
return dict(
factory="PascalVOCDataset",
args=args,
)
raise RuntimeError("Dataset not available: {}".format(name))
class ModelCatalog(object):
S3_C2_DETECTRON_URL = "https://dl.fbaipublicfiles.com/detectron"
C2_IMAGENET_MODELS = {
"MSRA/R-50": "ImageNetPretrained/MSRA/R-50.pkl",
"MSRA/R-50-GN": "ImageNetPretrained/47261647/R-50-GN.pkl",
"MSRA/R-101": "ImageNetPretrained/MSRA/R-101.pkl",
"MSRA/R-101-GN": "ImageNetPretrained/47592356/R-101-GN.pkl",
"FAIR/20171220/X-101-32x8d": "ImageNetPretrained/20171220/X-101-32x8d.pkl",
}
C2_DETECTRON_SUFFIX = "output/train/{}coco_2014_train%3A{}coco_2014_valminusminival/generalized_rcnn/model_final.pkl"
C2_DETECTRON_MODELS = {
"35857197/e2e_faster_rcnn_R-50-C4_1x": "01_33_49.iAX0mXvW",
"35857345/e2e_faster_rcnn_R-50-FPN_1x": "01_36_30.cUF7QR7I",
"35857890/e2e_faster_rcnn_R-101-FPN_1x": "01_38_50.sNxI7sX7",
"36761737/e2e_faster_rcnn_X-101-32x8d-FPN_1x": "06_31_39.5MIHi1fZ",
"35858791/e2e_mask_rcnn_R-50-C4_1x": "01_45_57.ZgkA7hPB",
"35858933/e2e_mask_rcnn_R-50-FPN_1x": "01_48_14.DzEQe4wC",
"35861795/e2e_mask_rcnn_R-101-FPN_1x": "02_31_37.KqyEK4tT",
"36761843/e2e_mask_rcnn_X-101-32x8d-FPN_1x": "06_35_59.RZotkLKI",
"37129812/e2e_mask_rcnn_X-152-32x8d-FPN-IN5k_1.44x": "09_35_36.8pzTQKYK",
# keypoints
"37697547/e2e_keypoint_rcnn_R-50-FPN_1x": "08_42_54.kdzV35ao"
}
@staticmethod
def get(name):
if name.startswith("Caffe2Detectron/COCO"):
return ModelCatalog.get_c2_detectron_12_2017_baselines(name)
if name.startswith("ImageNetPretrained"):
return ModelCatalog.get_c2_imagenet_pretrained(name)
raise RuntimeError("model not present in the catalog {}".format(name))
@staticmethod
def get_c2_imagenet_pretrained(name):
prefix = ModelCatalog.S3_C2_DETECTRON_URL
name = name[len("ImageNetPretrained/"):]
name = ModelCatalog.C2_IMAGENET_MODELS[name]
url = "/".join([prefix, name])
return url
@staticmethod
def get_c2_detectron_12_2017_baselines(name):
# Detectron C2 models are stored following the structure
# prefix//2012_2017_baselines/.yaml./suffix
# we use as identifiers in the catalog Caffe2Detectron/COCO//
prefix = ModelCatalog.S3_C2_DETECTRON_URL
dataset_tag = "keypoints_" if "keypoint" in name else ""
suffix = ModelCatalog.C2_DETECTRON_SUFFIX.format(dataset_tag, dataset_tag)
# remove identification prefix
name = name[len("Caffe2Detectron/COCO/"):]
# split in and
model_id, model_name = name.split("/")
# parsing to make it match the url address from the Caffe2 models
model_name = "{}.yaml".format(model_name)
signature = ModelCatalog.C2_DETECTRON_MODELS[name]
unique_name = ".".join([model_name, signature])
url = "/".join([prefix, model_id, "12_2017_baselines", unique_name, suffix])
return url
看到那个DATASETS了么,那就是coco_2014_train、coco_2014_valminusminival、coco_2014_minival的来源,你把训练集和测试集改成自己想要的,保险起见,名字还是沿用DATASETS的比较好,然后把.yaml中的名字改成自己想要的DATASETS中的名字就行了,比如我是这样改的:
DATASETS:
TRAIN: ("coco_2017_train",)
TEST: ("coco_2017_val",)然后把paths_catalog.py中的DATASETS中的对应的训练集和测试集的路径改成自己的,虽然他用的是什么coco/......,但是我们windows就有我们windows的粗暴路径,比如这样的
O:/Users/xxx/Anaconda3/envs/maskrcnn_benchmark/maskrcnn-benchmark/datasets/coco记得斜杠的方向
训练命令
这个其实官方就有提供,查看官方指南会好一点
我这里就提供几个能用的,记得在Anaconda Prompt (Anaconda3)里面cd到maskrcnn_benchmark里面
单GPU:
python tools/train_net.py --config-file O:/Users/XXX/Anaconda3/envs/maskrcnn_benchmark/maskrcnn-benchmark/configs/e2e_mask_rcnn_R_101_FPN_1x.yaml SOLVER.IMS_PER_BATCH 1 SOLVER.BASE_LR 0.0025 SOLVER.MAX_ITER 60000 SOLVER.STEPS "(30000, 40000)" TEST.IMS_PER_BATCH 1 MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN 2000python tools/train_net.py --config-file O:/Users/XXX/Anaconda3/envs/maskrcnn_benchmark/maskrcnn-benchmark/configs/e2e_mask_rcnn_R_101_FPN_1x.yamlpython tools/train_net.py --config-file O:/Users/XXX/Anaconda3/envs/maskrcnn_benchmark/maskrcnn-benchmark/configs/e2e_mask_rcnn_R_101_FPN_1x.yaml SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025 SOLVER.MAX_ITER 60000 SOLVER.STEPS "(30000, 40000)" TEST.IMS_PER_BATCH 1 MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN 2000python tools/train_net.py --config-file O:/Users/XXX/Anaconda3/envs/maskrcnn_benchmark/maskrcnn-benchmark/configs/e2e_mask_rcnn_R_101_FPN_1x.yaml SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025 SOLVER.MAX_ITER 720000 SOLVER.STEPS "(480000, 640000)" TEST.IMS_PER_BATCH 1 MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN 2000多GPU直接看官方的吧
在添加两张照片:
单GPU第一个命令:
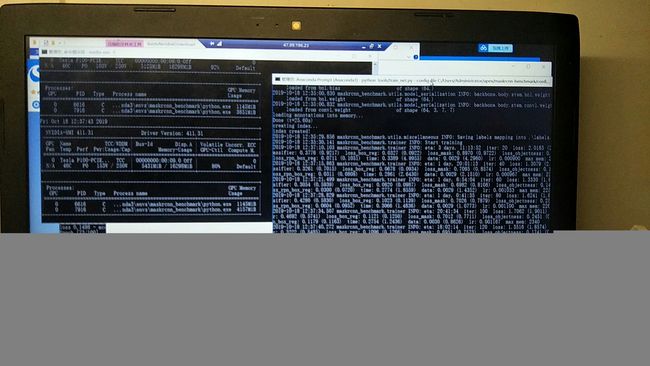
单GPU第四个命令(基于官方参数修改):
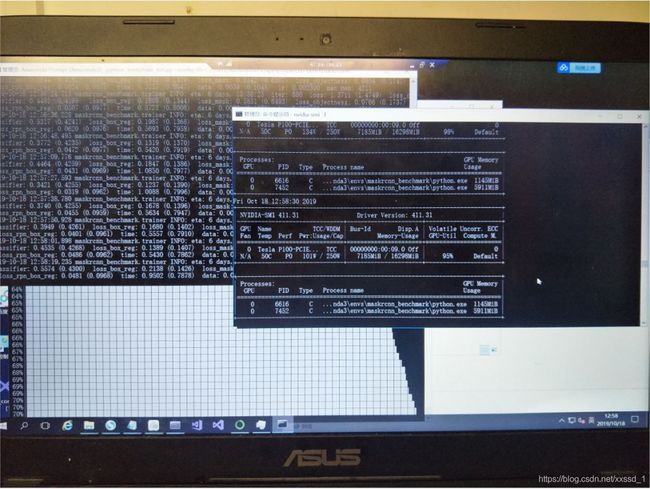
从图中可以看出,显存最低4G,最低4G,最低4G,内存若干,8G肯定不行
单GPU第二个命令,显存16G也不行