8、NumPy 基础:N维数组和通用函数
文章目录
- 一、NumPy 简介
- 1、NumPy 最重要的特点及功能
- 2、与 TensorFlow 以及 Pytorch 等的区别
- 二、ndarray:单一数据类型的多维数组
- 1. ndarray 的创建
- 2. ndarray 的访问
- 3. ndarray 的常用属性和方法
- `a、常用属性`
- `b、常用方法`
- 4. ndarray 的轴(Axes)和广播机制(Broadcasting)
- a、轴(Axes)
- b、广播机制(Broadcasting)
- 5. ndarrary 的内存结构
- 6. ndarrary 的常用函数
- a、数组随机打乱、选择
- b、数组组合
- c、数组分割
- d、数组复制
- e、数组分段
- 三、通用函数(ufunc): 元素级运算
- 1. 常用的通用函数
- 2. 常用的统计方法
- 3. 操作数组和文本文件
一、NumPy 简介
1、NumPy 最重要的特点及功能
- 具有两种基本对象:
ndarray & ufunc- N 维数组对象(ndarray):该对象是存储单一数据类型的多维数组(可表示标量、向量、矩阵或张量等)
- 通用函数(ufunc):具有用于对整组数据进行快速运算的标准数学函数(无需编写循环)
- 具有矢量运算和复杂广播能力,内存使用效率高
- 具有
线性代数、随机数生成以及傅里叶变换功能
2、与 TensorFlow 以及 Pytorch 等的区别
- Numpy 定位是各种各样的
科学计算,其在CPU上比较快 - TF 和 Pytorch 等的定位是
机器学习,它们在 Numpy 的基础上做了扩展,使其支持GPU 编程、分布式编程、自动微分等特性
二、ndarray:单一数据类型的多维数组
1. ndarray 的创建
-
通过构造函数
np.array(collection, dtype=None, copy=True)创建:collection为 python 列表(list of list)、元组、数组或其它序列类型
-
通过内置函数创建:
np.zeros(shape, dtype=None)、np.ones(shape)、np.empty(shape)、np.full(shape, fill_value):shape 为 int(1dim) or tuple of ints(>=2dim)np.zeros_like(arr)、np.ones_like(arr)、np.empty_like(arr)、np.full_like(arr, fill_value):以另一个数组为参数,并根据其形状和dtype创建一个全 0、1、空等的数组np.eye(scalar):创建一个形状为scalar*scalar的单位矩阵
-
通过随机数函数创建:
np.random.uniform(low=0.0, high=1.0, size=None):默认产生[0, 1)之间,形状为 size 的均匀分布(注意要带上参数);np.random.rand(3, 4)是其特例(注意 tuple 不用加括号)np.random.normal(loc=0.0, scale=1.0, size=None):默认产生形状为 size 的标准正态分布 ( μ , σ 2 ) = ( 0 , 1 ) (\mu, \sigma^2) = (0, 1) (μ,σ2)=(0,1)(注意要带上参数);np.random.randn(3, 4)是其特例(注意 tuple 不用加括号)np.random.randint(low=0, high=None, size=None):Return random integers from low (inclusive) to high (exclusive)- 注意:使用时要带上参数
- 0.5 的概率:
if np.random.randint(2): do something - 0.5 的概率:
if np.random.choice([0,1]): do something
np.random.seed(integer):随机数种子,固定后可用于重现某一实验结果Note:size 为 int or tuple of ints
-
通过序列函数创建:
np.arange(start, stop, step)创建:和 range 的区别是它返回的是数组而不是列表(不包括 stop)np.linspace(start, stop, N, endpoint=True):产生N个等距分布在[start, stop]间元素组成的数组,包括start & stop,步长为 ( s t o p − s t a r t ) / ( N − 1 ) (stop-start) / (N-1) (stop−start)/(N−1)np.logspace(start, stop, N, endpoint=True):产生N个对数等距分布的数组,包括start & stop,基数默认以 10 为底数,可以通过base参数指定(另外可通过endpoint指定是否包含 stop)
2. ndarray 的访问
-
索引(View)
-
一维数组的索引:和列表类似
(可以逆序索引(arr[ : : -1])和负索引arr[-3]) -
二维数组的索引:
arr[i, j] == arr[i][j] -
多维数组的索引:如果省略了后面的索引,则返回的对象会是一个维度低一点的
ndarray(但它含有高一级维度上的某条轴上的所有数据) -
条件索引:
arr[conditon] # conditon 可以使用 & | 进行多条件组合,应返回 ndarray- 布尔数组索引:仅返回结果的
一维数组,无论原数组是否是多维数组 - 整数数组索引:仅返回结果的
一维数组,无论原数组是否是多维数组 - Masked Array:
numpy.ma.masked_where(condition, a, copy=True)[source],用于处理瑕疵数据>>> a array([1, 8, 4, 9, 6, 7, 2, 5, 0, 3]) # 布尔数组索引 >>> a > 5 array([False, True, False, True, True, True, False, False, False, False]) >>> a[a>5] array([8, 9, 6, 7]) # 整数数组索引 >>> np.where(a>5) (array([1, 3, 4, 5]),) >>> a[np.where(a>5)] array([8, 9, 6, 7]) # Mask an array where a condition is met >>> b = ma.masked_where(a<=5, a) masked_array(data=[--, 8, --, 9, 6, 7, --, --, --, --], mask=[ True, False, True, False, False, False, True, True, True, True], fill_value=999999) >>> b.mean() = 7.5 # 加了mask,只处理没被 mask 的数据 >>> a.mean() = 4.5 >>> b.set_fill_value(-1) >>> b.filled() # 注意 b.data == a, 并没有改变,只是结合 mask 使用 array([-1, 8, -1, 9, 6, 7, -1, -1, -1, -1]) - np.where(condition, x=None, y=None):矢量版本的三元表达式
x if condition else y- If only
conditionis given, return the tuplecondition.nonzero(), the indices whereconditionis True# 1、一维数据 x = np.arange(5) array([0, 1, 2, 3, 4]) np.where(x>2) # 返回一个 tuple,第一个元素对应索引的坐标 (array([3, 4]),) # 2、二维数据 x = np.arange(9.).reshape(3, 3) array([[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]]) np.where( x > 5 ) # 返回一个 tuple,第一个元素对应索引的 x 坐标,第二个元素对应索引 的 y 坐标 (array([2, 2, 2]), array([0, 1, 2])) - If both
xandyare specified, the output array contains elements ofxwhereconditionis True, and elements fromyelsewhere.# 1、一维数据 y = np.arange(5) array([0, 1, 2, 3, 4]) np.where(x > 2, x, -1) array([-1, -1, -1, 3, 4]) # 返回一个一维的 array # 2、二维数据 x = np.arange(9.).reshape(3, 3) np.where(x < 5, x, -1) # Note: broadcasting. array([[ 0., 1., 2.], # 返回一个二维的 array [ 3., 4., -1.], [-1., -1., -1.]])
- If only
- 布尔数组索引:仅返回结果的
-
使用 ndarray/list 索引 ndarray
import numpy as np # 产生一个一组数组,使用数组/列表来索引出需要的元素(数组本身并不改变) x = np.arange(10, 1, -1) >>> array([10, 9, 8, 7, 6, 5, 4, 3, 2]) x[np.array([3, 3, -3, 8])] # 使用数组索引数组 >>> array([7, 7, 4, 2]) x[[8, 7, 6, 5, 4, 3, 2, 1, 0]] # 使用列表索引数组 >>> array([ 2, 3, 4, 5, 6, 7, 8, 9, 10]) # 注意:这一点和 list 不同 lst = [10, 9, 8, 7, 6, 5, 4, 3, 2] lst[[3, 3, -3, 8]] >>> TypeError: list indices must be integers or slices, not list
-
-
切片(View)
- 一维数组的切片:和列表类似
- 二维数组的切片:
arr[r1:r2, c1:c2:step] # 也可指定 step 进行切片,尽量不要使用arr[][]这种形式的切片,因为后面括号是基于前面括号的结果,而只使用一个大括号则是共同考虑,没有先后顺序
3. ndarray 的常用属性和方法
a、常用属性
- ndim 属性:表示数组的维度个数
- shape 属性:表示数组各个维度的大小(返回一个 tuple),各个维度相乘之积即为 size 属性
- dtype 属性:表示数组中各数据类型(
默认 np.int64, np.float64 or 'int64', 'float64'),可通过astype函数转换数组的数据类型 - strides 属性:保存的是当每个轴的下标增加 1 时,数据存储区中的指针所增加的字节数,eg:
(40, 8) - nbytes 属性:表示数组占多少个字节
- Note: 所有元素必须是相同类型(和 list 的区别)
b、常用方法
- 数组拷贝方法
- copy() 方法:拷贝一份数组,开辟新内存,不影响原始数组
- 改变数组形状的方法
- reshape() 方法:
- 改变数组的维度大小(可以把一个一维的向量转换成一个二维的矩阵),返回原始数组的视图
- transpose() 方法:
- 一维数组的转置:不起作用(这和线代不同),可以先 reshape 到二维再转置
- 二维数组的转置:可用
arr.T or arr.transpose() or np.transpose(arr, axes=None),返回原始数组的视图 - 高维数组的转置:需要得到一个由编号(0, 1, 2,…)组成的元组才能对这些轴进行转置,本质是轴对换,
arr.transpose(2, 1, 0) or np.transpose(arr, axes=(2, 1, 0)) or np.swapaxes(arr, 0, 2),返回原始数组的视图
- flatten() 和 ravel() 方法:
- 将多维数组转换为一维数组,可用
arr.reshape(-1), np.reshape(arr, -1) # 注意并没有np.flatten()函数 arr.flatten()返回原始数组的拷贝,对拷贝所做的修改不会影响原始矩阵,而arr.ravel()返回的是视图(view),会影响原始矩阵
- 将多维数组转换为一维数组,可用
np.expand_dims(a, axis)方法:Insert a new axisthat will appear at theaxisposition in the expanded array shape
np.squeeze(a, axis=None)方法:- 剔除所有长度为 1 的轴,也可指定剔除哪个轴
- reshape() 方法:
- 数组(数据类型)转换的方法
tolist()方法:将数组转换成列表(针对一维数组也可使用list(arr))tostring()==tobytes()方法:根据数组的数据类型将其转换成不同长度的字符串(1bytes=8bits)astype(dtype)方法:转换数组的数据类型,dtype 为 str 或 dtype- eg:
a = a.astype('float32') or a = a.astype(np.float32) # str 不加 np or 加 np 不加引号 - 整型在 64 位操作系统中默认数据类型为
int64 - 浮点型在 64 位操作系统中默认数据类型为
float64
- eg:
4. ndarray 的轴(Axes)和广播机制(Broadcasting)
a、轴(Axes)
- 多维数组做统计时要指定统计的维度(
eg: np.mean(x, axis=1, keepdims=False)),否则默认是在全部维度上做统计- keepdims=True:axis 是几,那就表明哪一维度
被压缩成 1 维 - keepdims=False:axis 是几,那就表明哪一维度
被干掉了,新数组的形状由剩余的维度组成的
- keepdims=True:axis 是几,那就表明哪一维度
- Note: 在内存上的排列是一维存储的,只是我们显示的视图不同而已(遵循行优先原则,先横轴再纵轴)

b、广播机制(Broadcasting)
- shape 相同数组间的任何算术运算都会将运算应用到
元素级 - shape 不相同的两个数组会间进行如下的
广播 (broadcasting)处理:- 让所有输入数组都向其中
shape 最长的数组看齐,shape 中不足的部分都通过在前面加 1 补齐 - 输出数组的 shape 是输入数组 shape 的
各个轴上的最大值 - 如果输入数组的某个轴和输出数组的对应轴的
长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错 - 当输入数组的某个轴的长度为 1 时,沿着此轴运算时都
用此轴上的第一组值
- 让所有输入数组都向其中
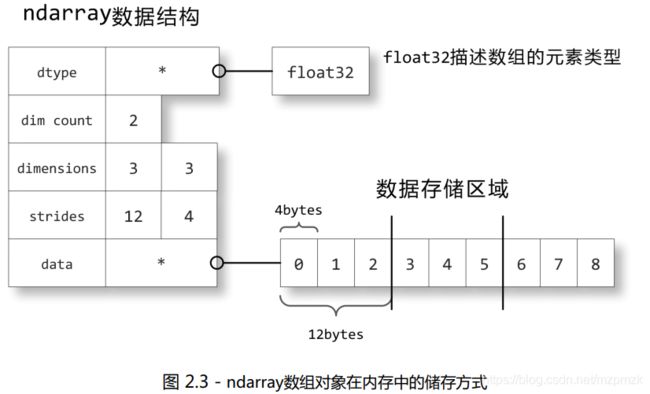
5. ndarrary 的内存结构
- ndarray 对象的内存组成:
-
rawdata:内存上一维连续的二进制流
-
metadata:用于解读二进制流的数据
- data 属性:存放的是 rawdata 的首地址
- strides 属性: 保存的是当每个轴的下标增加 1 时,数据存储区中的指针所增加的字节数
- dtype 属性:如何将元素的二进制数据转换为可用的值
-
Indexing schema(不同视图下的解读):- 根据 data 指针找到 ndarray 二进制流在内存上的位置
- 根据 strides 将二进制流切分成数据块
- 根据 dtype 将数据块解读成数据元素(注意 dtype 大小端问题)
-
- 不同的视图(
View)下 metadata 不同(id 不同),但共享 rawdata,只是对内存的展示方式不同而已:- 引用:
b = a,id 不会变,因为 metadata 不用改变b=a.reshape((3,4)),id 会变,因为 metadata 中的ndim shape strides等都改变了- 和 a 共享一块内存,不同的
视图
- 拷贝:
b = a.copy(),开辟一块新内存 - 赋值:
a[:] = -1 - ndarray 设计哲学:让绝大多数的多维数组的操作
仅需要改变其 metadata 部分即可
- 引用:
- 创建 ndarray 以及解读 ndarray 时的 Index order 问题:
- Matrix-Oriented:先横轴再纵轴(行优先),Numpy 里基本遵循此习惯
- Image-Oriented:先纵轴再横轴(列优先)
list(np.nditer(arr)):nditer 的迭代 基于内存上的结构
>>> np.arange(9).reshape((3,3),order='C')
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> b = np.arange(9).reshape((3,3),order='F')
>>> b.ravel()
array([0, 3, 6, 1, 4, 7, 2, 5, 8])
# list(np.nditer(a)) == list(np.nditer(b)), 内存上都是 0,1,2,3,4,5,6,7,8 这样排列的,只是不同的 View
# C++ 中 BGR 图像(HWC)在内存中的排列顺序(BGRBGRBGR...)-->C-->W-->H
for (i=0; i<h; i++)
for (j=0, j<w; j++)
for (k=0, k<c; k++)
# C++ 中 RGB 图像(CHW)在内存中的排列顺序(RRR...GGG...BBB...)-->W-->H-->C
for (i=0; i<c; i++)
for (j=0, j<h; j++)
for (k=0, k<w; k++)
6. ndarrary 的常用函数
a、数组随机打乱、选择
-
np.random.permutation(x):- If x is an integer, randomly permute np.arange(x).
- If x is an array, make a
copyand shuffle the elements randomly. Return a permuted sequence(ndarray)>>> nr.permutation(6) array([4, 5, 2, 3, 1, 0]) >>> nr.permutation(np.arange(-3,7,2)) array([ 3, -3, -1, 1, 5]) >>> nr.permutation(np.arange(6).reshape((2,3))) # only shuffled along its first index. array([[3, 4, 5], [0, 1, 2]]) - 多个数组(
ndarray)以相同顺序打乱import numpy as np # 多个数组(ndarray,存放在 lst 中)以相同顺序打乱 def shuffle_seqs(lst): # lst[1] 中存放的是 label random_order = np.random.permutation(len(lst[1])) permuted_lst = [] for arr in lst: permuted_lst.append(arr[random_order]) # 以数组索引数组 return permuted_lst X = np.array( [[0, 0], [0, 1], [1, 0], [1, 1]], dtype='int32') # 训练数据 Y = np.array([0, 1, 1, 0] , dtype='int32') # label epoch = 1000 for i in range(epoch): # shuffle per epoch X, Y = shuffle_seqs([X, Y]) print(X) print(Y) >>> [[1 1] [0 0] [0 1] [1 0]] >>> [0 0 1 1]
-
np.random.shuffle(arr):- Modify a sequence
in-placeby shuffling its contents - This function
onlyshuffles the array along thefirst axisof a multi-dimensional array# shuffle in the same way def shuffle_in_unison_scary(a, b): rng_state = np.random.get_state() np.random.shuffle(a) np.random.set_state(rng_state) np.random.shuffle(b) - split trainval and test datasets(
shuffle first)# -*- coding: utf-8 -*- import os import codecs import numpy as np def split_datasets(xml_dir, trainval_path, test_path): xml_prefix = [i[:-4] + '\n' for i in os.listdir(xml_dir)] np.random.shuffle(xml_prefix) xml_num = len(xml_prefix) test_num = int(xml_num * 0.2) # 0.2/0.8 test_xml_prefix = xml_prefix[:test_num] trainval_xml_prefix = xml_prefix[test_num:] with codecs.open(trainval_path, 'w', encoding='utf-8') as f1: f1.writelines(trainval_xml_prefix) with codecs.open(test_path, 'w', encoding='utf-8') as f2: f2.writelines(test_xml_prefix) if __name__ == '__main__': XML_DIR = 'data/plate_devkit/plate/Annotations' TRAIN_VAL_PATH = 'data/plate_devkit/plate/ImageSets/Main/trainval.txt' TEST_PATH = 'data/plate_devkit/plate/ImageSets/Main/test.txt' split_datasets(XML_DIR, TRAIN_VAL_PATH, TEST_PATH) print('job done!')
- Modify a sequence
-
np.random.choice(a, size=None, replace=True, p=None):- Generates a random sample from a given 1-D array
- 可用于 data shuffle & augmentation (通过设置 replace=True)
# Parameters: a : 1-D array-like or int # If an ndarray, a random sample is generated from its elements. If an int, the random sample is generated as if a were np.arange(a) size : int or tuple of ints, optional # Output shape. If the given shape is, e.g., (m, n, k), then m * n * k samples are drawn. Default is None, in which case a single value is returned. replace : 决定采样中是否有重复值, True 表示可以重复,默认是 True p : 1-D array-like, optional # The probabilities associated with each entry in a. If not given the sample assumes a uniform distribution over all entries in a. # Returns: single item or ndarray,the generated random samples # eg: # 1、随机取 0 或 1,0.5 的概率 if np.random.choice([0,1]): do something # 2、Generate a uniform random sample from np.arange(5) of size 3 without replacement # this is equivalent to np.random.permutation(np.arange(5))[:3] np.random.choice(5, 3, replace=False) ---> array([3, 1, 0]) # 3、Generate a non-uniform random sample from np.arange(5) of size 3 np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0]) ---> array([3, 3, 0]) # 4、Generate a 2 dim array >>>np.random.choice(6, (3,2), replace=False) array([[2, 0], [5, 4], [3, 1]])
-
np.take(a=params, indices=indices, axis=0)orarr[indices]:indices 为 list 或 ndarray,若不指定 axis 则按展平的顺序取>>> a = np.array([4, 3, 5, 7, 6, 8]) >>> indices = [0, 1, 4] >>> np.take(a, indices) array([4, 3, 6]) >>> a[indices] array([4, 3, 6]) >>>b = np.arange(9).reshape(3, 3) array([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) >>>np.take(b, indices=[[0, 1], [2, 3]]) # If indices is not one dimensional, the output also has these dimensions array([[0, 1], [2, 3]]) >>>np.take(b, indices=[0, 1, 2, 3]) array([0, 1, 2, 3]) >>>np.take(b, axis=1, indices=[0,2]) array([[0, 2], [3, 5], [6, 8]])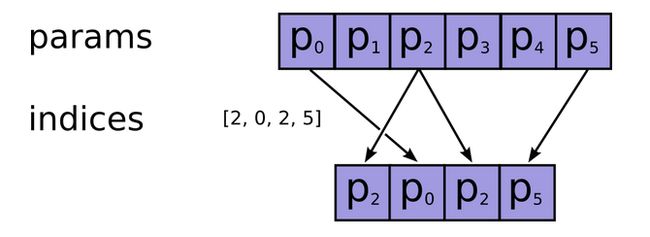
b、数组组合
- Vertical stacking(row wise)
- 格式:
np.vstack(tup) - Equivalent to
np.concatenate(tup, axis=0)iftupcontains arrays that are at least 2-dimensional - 注意:元组必须带括号,新数组第 0 维为所有数组的第 0 维之
和 - 作用:可以用于两个数组 batch 维度的拼接
- 格式:
- Horizontal stacking(column wise)
- 格式:
np.hstack(tup) - Equivalent to
np.concatenate(tup, axis=1) - 注意:元组必须带括号,新数组第 1 维为所有数组的第 1 维之
和
- 格式:
- Depth stacking(depth wise/along third dimension)
- 格式:
np.dstack(tup) - Equivalent to
np.concatenate(tup, axis=2) - 注意:元组必须带括号,新数组第 2 维为所有数组的第 2 维之
和
- 格式:
- 增加 batch 维度的做法:
- 使用
np.expand_dims(a, axis=0)方法,然后concat - 创建一个
目标维度的全零向量,然后赋值

- 使用
- ndarrary 中添加多行或列数组的方法
- Column stacking:
np.column_stack(tup) - Row stacking:
np.row_stack(tup) - np.insert() 方法
np.c_[] && np.r_[]# 一维数组的 stacking a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) np.vstack((a,b)) # 一维变二维,和 concat 的区别(一维情况下不能在 axis=1 下进行 concat) array([[1, 2, 3], [4, 5, 6]]) np.hstack((a,b)) # 还是一维 array([1, 2, 3, 4, 5, 6]) np.dstack((a,b)) # 一维变三维 array([[[1, 4], [2, 5], [3, 6]]]) # 二维数组的 stacking c = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) d = np.array([[ 2, 4, 6], [ 8, 10, 12], [14, 16, 18]]) np.vstack((c, d)) # 相当于 np.concatenate((c, d), axis=0) array([[ 1, 2, 3], [ 4, 5, 6], [ 7, 8, 9], [ 2, 4, 6], [ 8, 10, 12], [14, 16, 18]]) np.hstack((c, d)) # 相当于 np.concatenate((c, d), axis=1) array([[ 1, 2, 3, 2, 4, 6], [ 4, 5, 6, 8, 10, 12], [ 7, 8, 9, 14, 16, 18]]) np.dstack((c, d)) # 和 concat 的区别(二维情况下不能在 axis=2 下进行 concat) array([[[ 1, 2], [ 2, 4], [ 3, 6]], [[ 4, 8], [ 5, 10], [ 6, 12]], [[ 7, 14], [ 8, 16], [ 9, 18]]]) # 1.使用 np.c_[] 和 np.r_[] 分别添加行和列 e = np.array([[1, 2, 3], [4, 5, 6], [7 , 8 ,9]]) f = np.eye(3) np.c_[e,f] # 添加某列时 b 可以是低一维的数据 array([[ 1., 2., 3., 1., 0., 0.], [ 4., 5., 6., 0., 1., 0.], [ 7., 8., 9., 0., 0., 1.]]) np.r_[e, f] # 添加某行时 a, b 必须维度相同 array([[ 1., 2., 3.], [ 4., 5., 6.], [ 7., 8., 9.], [ 1., 0., 0.], [ 0., 1., 0.], [ 0., 0., 1.]]) # 2.使用 np.insert() 方法添加行和列 np.insert(e, 3, values=f, axis=1) # 3代表 b 插入的位置,axis 表示那个轴,在此表示y轴(列) array([[1, 2, 3, 1, 0, 0], [4, 5, 6, 0, 1, 0], [7, 8, 9, 0, 0, 1]]) np.insert(e, 3, values=f, axis=0) array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 0, 0], [0, 1, 0], [0, 0, 1]]) # 3. 使用 np.pad() 进行补零操作 Z = np.ones((5,5)) Z = np.pad(Z, pad_width=1, mode='constant', constant_values=0) array([[0., 0., 0., 0., 0., 0., 0.], [0., 1., 1., 1., 1., 1., 0.], [0., 1., 1., 1., 1., 1., 0.], [0., 1., 1., 1., 1., 1., 0.], [0., 1., 1., 1., 1., 1., 0.], [0., 1., 1., 1., 1., 1., 0.], [0., 0., 0., 0., 0., 0., 0.]])
- Column stacking:
c、数组分割
np.split(ary, indices_or_sections, axis=0)- ary : Array to be divided into sub-arrays.
- indices_or_sections : int or 1-D array
- If
indices_or_sectionsis an integer, N, the array will be divided into N equal arrays alongaxis. If such a split is not possible, an error is raised. - If
indices_or_sectionsis a 1-D array of sorted integers, the entries indicate where alongaxisthe array is split;For example,[2, 3]would, foraxis=0, result in[ary[:2], ary[2:3], ary[3:]]按上面的区间分成三份,If an index exceeds the dimension of the array alongaxis, an empty sub-array is returned correspondingly.
- If
- 一维情形示例:
>>> x = np.arange(9.0) >>> np.split(x, 3) [array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])] >>> x = np.arange(8.0) >>> np.split(x, [3, 5, 6, 10]) [array([0., 1., 2.]), array([3., 4.]), array([5.]), array([6., 7.]), array([], dtype=float64)] - 二维情形示例:

d、数组复制
np.repeat(a, repeats, axis=None):对数组中的每个元素进行连续重复复制# Parameters: a : array_like, Input array. repeats : int or array of ints # The number of repetitions for each element. `repeats` is broadcasted to fit the shape of the given axis. axis : int, optional # The axis along which to repeat values. By default, use the flattened input array, and return a flat output array. # Returns:ndarray Examples -------- # 一维数据情况 x = 3 np.repeat(x, 4) array([3, 3, 3, 3]) # 二维数据情况,对每一个数据 repeat,然后 flatten x = np.array([[1,2],[3,4]]) np.repeat(x, 2) array([1, 1, 2, 2, 3, 3, 4, 4]) # 沿着水平坐标轴对每一个数据进行 repeat,不进行 flatten np.repeat(x, 3, axis=1) array([[1, 1, 1, 2, 2, 2], [3, 3, 3, 4, 4, 4]]) # 沿着垂直坐标轴对每一个元素(这里是【1,2】和 【3,4】)进行 repeat,不进行 flatten np.repeat(x, [1, 2], axis=0) array([[1, 2], [3, 4], [3, 4]])np.tile(A, reps):对整个数组进行复制拼接# Parameters: A : array_like, Input array. reps : array_like # The number of repetitions of `A` along each axis. # Returns: If `reps` has length `d`, the result will have dimension of `max(d, A.ndim)`. Examples -------- # 一维数据的情况 >>> a = np.array([0, 1, 2]) >>> np.tile(a, 2) array([0, 1, 2, 0, 1, 2]) >>> np.tile(a, (2, 2)) # 构建一个 2*2 的 copy array([[0, 1, 2, 0, 1, 2], [0, 1, 2, 0, 1, 2]]) # 二维数据的情况 >>> b = np.array([[1, 2], [3, 4]]) >>> np.tile(b, 2) array([[1, 2, 1, 2], [3, 4, 3, 4]])
e、数组分段
- 函数:
np.piecewise(x, condlist, funclist)>>> x = np.arange(-2,3) >>> x array([-2, -1, 0, 1, 2]) >>> np.piecewise(x, [x < 0, x >= 0], [lambda x:0, lambda x:x]) array([0, 0, 0, 1, 2]) >>> np.piecewise(x, [x < 0, x >= 0], [-1, 1]) array([-1, -1, 1, 1, 1])
三、通用函数(ufunc): 元素级运算
1. 常用的通用函数
一元通用函数- np.ceil():取向上最接近的整数
- np.floor():取向下最接近的整数
- np.rint():四舍五入
- np.fix(): Round an array of floats element-wise
to nearest integer towards zero - np.isnan():判断元素是否为 NaN(Not a Number)
- np.abs():计算整数、浮点数或复数的绝对值
- np.exp():计算各元素的指数
- np.sqrt():计算各元素的平方根
- np.square():计算各元素的平方
- np.log()、np.log10():分别为以 e 和 10 为底的元素级对数运算
- np.tan()、np.tanh()、np.sin()、np.cos():三角函数的元素级运算
- np.logical_not():取反,返回布尔型值
二元通用函数np.add(x1, x2)、np.subtract(x1, x2)、np.multiply(x1, x2)、np.divide(x1, x2)、np.mod(x1, x2)、np.power(x1, exp):- 元素级加减乘除、取余及指数运算,当第二个数为标量时,将进行
broadcast运算
- 元素级加减乘除、取余及指数运算,当第二个数为标量时,将进行
np.matmul(x1, x2):使用此函数实现矩阵乘积np.maximum(x1, x2)、np.minimum(x1, x2):- 逐元素比较取其大/小者,当第二个数为标量时,将进行
broadcast运算 x1, x2可以为 n 维 array,此时将逐元素比较取大者或小者a = np.array([1,3]); b = np.array([2,4]); np.maximum(a,b)=array([2, 4])
- 逐元素比较取其大/小者,当第二个数为标量时,将进行
np.equal(x1, x2)、np.not_equal(x1, x2)、np.greater(x1, x2)、np.greater_equal(x1, x2)、np.less(x1, x2)、np.less_equal(x1, x2):- 元素级比较元素,返回布尔型值
np.logical_and(x1, x2)、np.logical_or(x1, x2)、np.logical_xor(x1, x2):- 元素级逻辑运算,返回布尔型值
2. 常用的统计方法
多维数组做统计时要指定统计的维度(
eg: np.mean(x, axis=1, keepdims=False)),否则默认是在全部维度上做统计
- keepdims=True:axis 是几,那就表明哪一维度
被压缩成 1 维- keepdims=False:axis 是几,那就表明哪一维度
被干掉了,新数组的形状由剩余的维度组成的
- np.mean(),np.sum():取均值和累积和
- np.std(),np.var():标准差和方差
- np.max(),np.min():返回原数组的最大值和最小值
- np.sort():从小到大排序,返回原数组的 copy
- np.product():求所有元素或某一轴上所有元素的乘积
- np.argmax(),np.argmin():最大和最小元素的索引
- np.argsort(x),np.argsort(-x):取得从小到大或从大到小排序的索引
- np.argwhere(condition):找出符合条件元素的索引
- np.cumsum():所有元素的累加和
- np.cumprod():所有元素的累计积
- np.all(a, axis=None):全部满足条件
- np.any(a, axis=None):Test whether any array element along a given axis evaluates to True.
- np.unique():找到唯一值并返回排序结果
3. 操作数组和文本文件
- NumPy 能够读写磁盘上的文本数据或二进制数据
np.load & np.save是读写磁盘数组数据的两个主要函数- 将数组以二进制格式保存到磁盘
# np.save # 默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的 # 如果文件路径末尾没有扩展名.npy, 则该扩展名会被自动加上 arr = np.arrange(10) np.save('some_array', arr) # np.load np.load('some_array.npy') # load 的时候要加上后缀名 array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) - 存取文本文件
# loadtxt filename = './presidential_polls.csv' data_array = np.loadtxt(filename, # 文件名 delimiter=',', # 分隔符 dtype=str, # 数据类型 usecols=(0,2,3)) # 指定读取的列索引号 print data_array, data_array.shape [['cycle' 'type' 'matchup'] ['2016' '"polls-plus"' '"Clinton vs. Trump vs. Johnson"'] ['2016' '"polls-plus"' '"Clinton vs. Trump vs. Johnson"'] ..., ['2016' '"polls-only"' '"Clinton vs. Trump vs. Johnson"'] ['2016' '"polls-only"' '"Clinton vs. Trump vs. Johnson"'] ['2016' '"polls-only"' '"Clinton vs. Trump vs. Johnson"']] (10237L, 3L) # loadtxt, 明确指定每列数据的类型 filename = './presidential_polls.csv' data_array = np.loadtxt(filename, # 文件名 delimiter=',', # 分隔符 skiprows=1, dtype={'names':('cycle', 'type', 'matchup'), 'formats':('i4', 'S15', 'S50')}, # 数据类型 usecols=(0,2,3)) # 指定读取的列索引号 print data_array, data_array.shape # 读取的结果是一维的数组,每个元素是一个元组 [(2016, '"polls-plus"', '"Clinton vs. Trump vs. Johnson"') (2016, '"polls-plus"', '"Clinton vs. Trump vs. Johnson"') (2016, '"polls-plus"', '"Clinton vs. Trump vs. Johnson"') ..., (2016, '"polls-only"', '"Clinton vs. Trump vs. Johnson"') (2016, '"polls-only"', '"Clinton vs. Trump vs. Johnson"') (2016, '"polls-only"', '"Clinton vs. Trump vs. Johnson"')] (10236L,) # 保存文本文件:np.savetxt # 文本读写主要用 pandas 实现,这里就不介绍啦