(IMDN ACMM2019)轻量化Lightweight Image Super-Resolution with Information Multi-distillation Network
文章地址:https://arxiv.org/pdf/1909.11856.pdf
作者的项目地址:代码
论文作者:Zheng Hui 西安电子科技大学
一、简单介绍
受IDN(CVPR2018)的的启发,文章提出了Multi-distillation模块,实现了内存和实时性之间的最优。整个文章的主要的贡献有:
1、提出了轻量化的Multi-distillation网络,来快速和准确的做SR。
2、提出了自适应裁剪的方法,来实现任意尺度的放大。
3、研究发现网络的深度才是影响速度的主要因素。
参考文献:
Fast and Accurate Single Image Super-Resolution via Information Distillation Network(CVPR2018)
Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network(ECCV2018)
加上本文,三篇文章是同一个作者。
二、网络结构

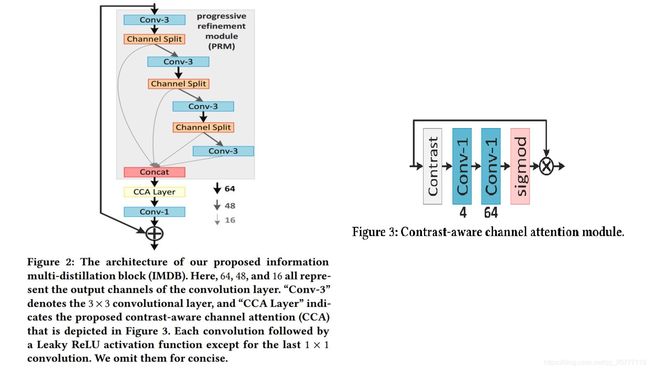
class IMDModule(nn.Module):
def __init__(self, in_channels, distillation_rate=0.25):
super(IMDModule, self).__init__()
self.distilled_channels = int(in_channels * distillation_rate)
self.remaining_channels = int(in_channels - self.distilled_channels)
self.c1 = conv_layer(in_channels, in_channels, 3)
self.c2 = conv_layer(self.remaining_channels, in_channels, 3)
self.c3 = conv_layer(self.remaining_channels, in_channels, 3)
self.c4 = conv_layer(self.remaining_channels, self.distilled_channels, 3)
self.act = activation('lrelu', neg_slope=0.05)
self.c5 = conv_layer(in_channels, in_channels, 1)
self.cca = CCALayer(self.distilled_channels * 4)
def forward(self, input):
out_c1 = self.act(self.c1(input))
distilled_c1, remaining_c1 = torch.split(out_c1, (self.distilled_channels, self.remaining_channels), dim=1)
#难道这里就是他所为的distillation模块?其实就是将通道进行分离操作
out_c2 = self.act(self.c2(remaining_c1))
distilled_c2, remaining_c2 = torch.split(out_c2, (self.distilled_channels, self.remaining_channels), dim=1)
out_c3 = self.act(self.c3(remaining_c2))
distilled_c3, remaining_c3 = torch.split(out_c3, (self.distilled_channels, self.remaining_channels), dim=1)
out_c4 = self.c4(remaining_c3)
out = torch.cat([distilled_c1, distilled_c2, distilled_c3, out_c4], dim=1)
out_fused = self.c5(self.cca(out)) + input
return out_fused代码中的torch.spilt就是将通道分离出来。
def mean_channels(F):
assert(F.dim() == 4)
spatial_sum = F.sum(3, keepdim=True).sum(2, keepdim=True)
return spatial_sum / (F.size(2) * F.size(3))
def stdv_channels(F):
assert(F.dim() == 4)
F_mean = mean_channels(F)
F_variance = (F - F_mean).pow(2).sum(3, keepdim=True).sum(2, keepdim=True) / (F.size(2) * F.size(3))
return F_variance.pow(0.5)
# contrast-aware channel attention module
class CCALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CCALayer, self).__init__()
self.contrast = stdv_channels
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.contrast(x) + self.avg_pool(x)
y = self.conv_du(y)
return x * y
他这里所为的Contrast-aware channel attention module.实际上就是在SE的global average pooling部分上再加上像素点的均方差。如下图所示,红色的部分为global average pooling,其他部分为像素点对应的均方差。
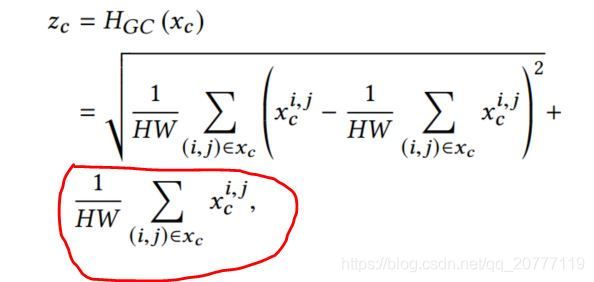
4、实验
训练集:DIV2K dataset。评价指标:PSNR and SSIM on Y channel
网络由6个IMDB模块组成
4.3 模型分析
4.3.1 模型参数

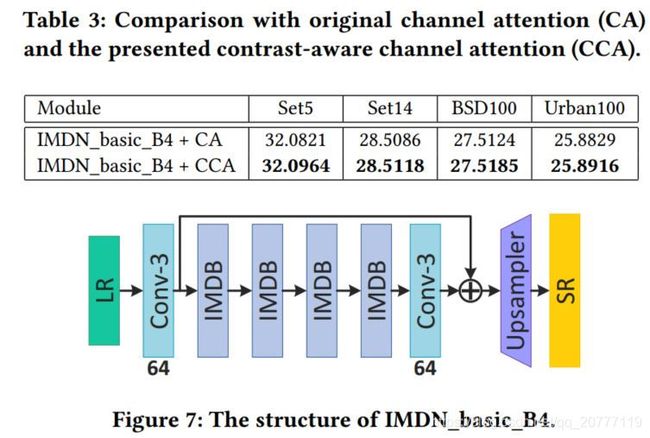
4.3.2 消融实验
分别验证了CCA(原图3)、PRM(原图2中的灰色部分)、IIC(模块间连接)模块的性能。

4.3.3 自适应裁剪模块的验证
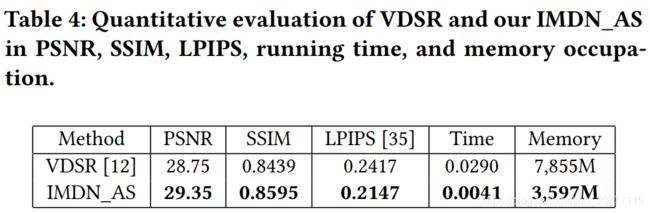
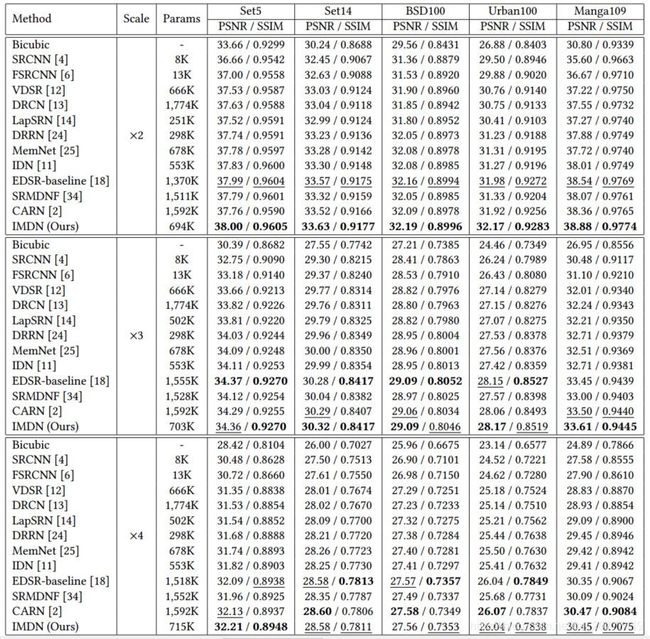
4.4 与现有的最好算法对比
4.5 运行时间
4.5.1 复杂度分析
4.5.2 运行时间
文章的实验表明,运行时间和网络的深度有关。例如EDSR虽然有43M,但是深度为69,所以运行时间短;而RCAN虽然参数数量较少,但是很深,所以运行慢。
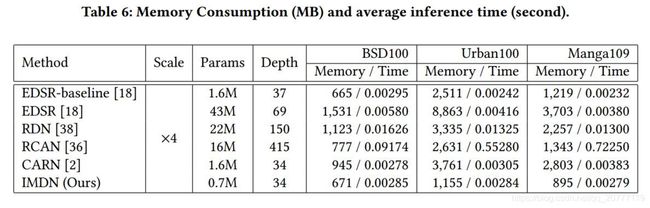

method achieves a balance including visual quality, execution speed, and memory consumption.