可分离卷积及深度可分离卷积详解
再来看一下nn.Conv2d():
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
输入为(N,C_in,H,W),输出为(N,C_out,H_out,W_out).
dilation空洞卷积来控制卷积膨胀间隔;
groups分组卷积来控制输入和输出的连接方式,in_channels和out_channels都要被groups整除。当groups设置不同时,可以区分出分组卷积或深度可分离卷积:
- 当
groups=1时,表示普通卷积层 - 当
groups - 当
groups=in_channels时,表示深度可分离卷积,每个通道都有一组自己的滤波器,大小为:
可分离卷积
可分离卷积包括空间可分离卷积(Spatially Separable Convolutions)和深度可分离卷积(depthwise separable convolution)。
假设feature的size为[channel, height , width]
- 空间也就是指:[height, width]这两维度组成的。
- 深度也就是指:channel这一维度。
1. 空间可分离卷积
通俗的说,空间可分离卷积就是将nxn的卷积分成1xn和nx1两步计算。
- 普通的3x3卷积在一个5x5的feature map上的计算方式如下图,每个位置需要9此惩罚,一共9个位置,整个操作要81次做乘法:
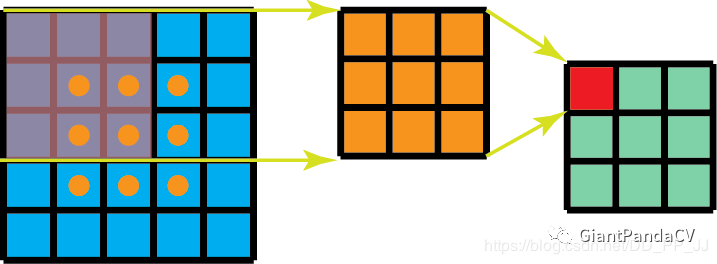

虽然空间可分离卷积可以节省计算成本,但一般情况下很少用到。所以我们后面主要以深度可分离卷积展开讲解。
2. 深度可分离卷积:
在Google的Xception以及MobileNet论文中都有描述。它的核心思想是将一个完整的卷积运算分解为两步进行,分别为Depthwise Convolution(逐深度卷积)与Pointwise Convolution(逐点1*1卷积)。
高效的神经网络主要通过:1. 减少参数数量;2. 量化参数,减少每个参数占用内存
目前的研究总结来看分为两个方向:
一是对训练好的复杂模型进行压缩得到小模型;
二是直接设计小模型并进行训练。(Mobile Net属于这类)
首先,我们比较下全卷积和深度可分离卷积:
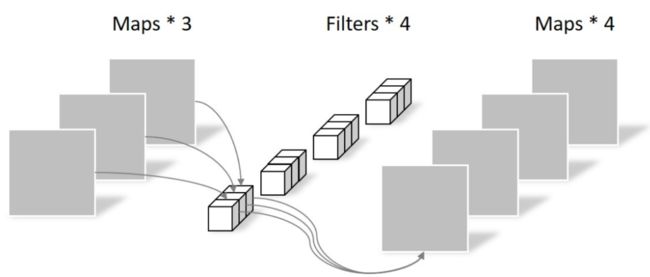
- 常规卷积:假设输入层为一个大小为64×64像素、三通道彩色图片。经过一个包含4个Filter的卷积层,最终输出4个Feature Map,且尺寸与输入层相同。我们可以计算出卷积层的参数数量是 4x3x3x3=108,参考下图:

- 逐深度卷积(滤波):将单个滤波器应用到每一个输入通道。还用上面那个例子,这里的Filter的数量与上一层的Depth相同。所以一个三通道的图像经过运算后生成了3个Feature map,参数数量是 3x3x3=27,参考下图:

代码测试
1. 普通卷积、深度可分离卷积对比:
import torch.nn as nn
import torch
from torchsummary import summary
class Conv_test(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, padding, groups):
super(Conv_test, self).__init__()
self.conv = nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=kernel_size,
stride=1,
padding=padding,
groups=groups,
bias=False
)
def forward(self, input):
out = self.conv(input)
return out
#标准的卷积层,输入的是3x64x64,目标输出4个feature map
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 4, 3, 1, 1).to(device)
print(summary(conv, input_size=(3, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 4, 64, 64] 108
================================================================
Total params: 108
Trainable params: 108
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 0.12
Params size (MB): 0.00
Estimated Total Size (MB): 0.17
----------------------------------------------------------------
None
# 逐深度卷积层,输入同上
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 3, 3, padding=1, groups=3).to(device)
print(summary(conv, input_size=(3, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 3, 64, 64] 27
================================================================
Total params: 27
Trainable params: 27
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 0.09
Params size (MB): 0.00
Estimated Total Size (MB): 0.14
----------------------------------------------------------------
None
# 逐点卷积层,输入即逐深度卷积的输出大小,目标输出也是4个feature map
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(3, 4, kernel_size=1, padding=0, groups=1).to(device)
print(summary(conv, input_size=(3, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 4, 64, 64] 12
================================================================
Total params: 12
Trainable params: 12
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 0.12
Params size (MB): 0.00
Estimated Total Size (MB): 0.17
----------------------------------------------------------------
None
2. 分组卷积、深度可分离卷积对比:
- 普通卷积:总参数量是 4x8x3x3=288。
- 分组卷积:假设输入层为一个大小为64×64像素的彩色图片、in_channels=4,out_channels=8,经过2组卷积层,最终输出8个Feature Map,我们可以计算出卷积层的参数数量是 2x8x3x3=144。
- 深度可分离卷积:逐深度卷积的卷积数量是 4x3x3=36, 逐点卷积卷积数量是 1x1x4x8=32,总参数量为68。
#普通卷积层
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(4, 8, 3, padding=1, groups=1).to(device)
print(summary(conv, input_size=(4, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 64, 64] 288
================================================================
Total params: 288
Trainable params: 288
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.06
Forward/backward pass size (MB): 0.25
Params size (MB): 0.00
Estimated Total Size (MB): 0.31
----------------------------------------------------------------
None
# 分组卷积层,输入的是4x64x64,目标输出8个feature map
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(4, 8, 3, padding=1, groups=2).to(device)
print(summary(conv, input_size=(4, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 64, 64] 144
================================================================
Total params: 144
Trainable params: 144
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.06
Forward/backward pass size (MB): 0.25
Params size (MB): 0.00
Estimated Total Size (MB): 0.31
----------------------------------------------------------------
None
# 逐深度卷积层,输入同上
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(4, 4, 3, padding=1, groups=4).to(device)
print(summary(conv, input_size=(4, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 4, 64, 64] 36
================================================================
Total params: 36
Trainable params: 36
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.06
Forward/backward pass size (MB): 0.12
Params size (MB): 0.00
Estimated Total Size (MB): 0.19
----------------------------------------------------------------
None
# 逐点卷积层,输入即逐深度卷积的输出大小,目标输出也是8个feature map
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv = Conv_test(4, 8, kernel_size=1, padding=0, groups=1).to(device)
print(summary(conv, input_size=(4, 64, 64)))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 64, 64] 32
================================================================
Total params: 32
Trainable params: 32
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.06
Forward/backward pass size (MB): 0.25
Params size (MB): 0.00
Estimated Total Size (MB): 0.31
----------------------------------------------------------------
None
3. MobileNet V1

V1这篇文章是17年的提出的一个轻量级神经网络。一句话概括:MobileNetV1就是把VGG中的标准卷积层换成深度可分离卷积。
这种方法能用更少的参数、更少的运算,达到跟跟普通卷差不多的结果。
3.1 MobileNetV1与普通卷积:
大致结构对比:

卷积过程对比:

输入尺寸为D_f是输入的特征高度,D_w是输入特征宽度,M是输入的channel,N是输出的channel。
标准的卷积运算和Depthwise Separable卷积运算计算量的比例为:

3.2 宽度因子:更薄的模型
如果需要模型更小更快,可以定义一个宽度因子 ,它可以让网络的每一层都变的更薄。如果input的channel是
,它可以让网络的每一层都变的更薄。如果input的channel是 就变为
就变为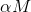 ,如果output channel是N就变为
,如果output channel是N就变为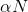 ,那么在有宽度因子情况下的深度分离卷积运算的计算量公式就成了如下形式:
,那么在有宽度因子情况下的深度分离卷积运算的计算量公式就成了如下形式:

3.3 分辨率因子:减少表达力
分辨率因子 就是减少计算量的超参数,这个因子是和input的长宽相乘,会缩小input的长宽而导致后面的每一层的长宽都缩小。
就是减少计算量的超参数,这个因子是和input的长宽相乘,会缩小input的长宽而导致后面的每一层的长宽都缩小。

3.4 疑惑解答
- ReLU6:

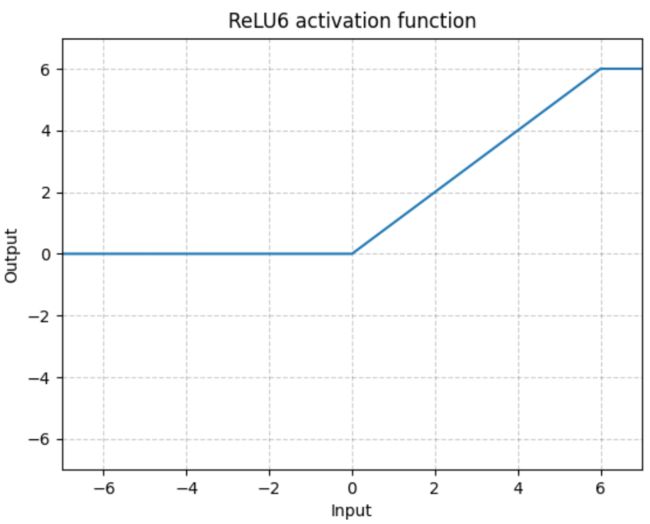
-
宽度因子和分辨率因子为什么没有出现在V1代码中?
这是我在看代码时疑惑,因为github上找MobileNetV1的代码官方码是TF的,py给的都是功能块。所以参照官方TF代码可以发现代码对
为0.75,0.5和0.25进行了封装,这样当我们调用模型来构建网络的时候,depth_multiplier就已经设置为0.75了:separable_conv2d( inputs, #size为[batch_size, height, width, channels]的tensor num_outputs, # 是pointwise卷积运算output的channel,如果为空,就不进行pointwise卷积运算。 kernel_size, #是filter的size [kernel_height, kernel_width],如果filter的长宽一样可以只填入一个int值。 depth_multiplier, #就是前面介绍过的宽度因子,在代码实现中改成了深度因子,因为是影响的channel,确实深度因子更合适。 stride=1, padding='SAME', data_format=DATA_FORMAT_NHWC, rate=1, ... )关于这两个因子是怎么使用的,代码后面写的是:

3.5 代码部分相关解释:
torch.nn.Linear(in_features, out_features, bias=True)
- in_features:输入特征图的大小
- out_features:输出特征图的大小
- bias:如果设置为False,该层不会增加偏差;默认为:True
代码里出现了Sequential,想必我们都不陌生,都知道他是个容器,但我此前并不知道nn.module()里面都包括什么样的“容器”,下面来了解一些常用的:
-
torch.nn.Sequential(*args):用于按顺序包装一组网络层 -
torch.nn.ModuleList(modules=None):用于包装一组网络层,以迭代的方式调用网络层 -
torch.nn.ModuleDict(modules=None):用于包装一组网络层,以索引的方式调用网络层
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# 深度卷积,通道数不变,用于缩小特征图大小
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# 逐点卷积,用于增大通道数
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class MobileNet(nn.Module):
cfg = [
64, (128,2), 128, (256,2), 256, (512,2), 512, 512, 512, 512, 512, (1024,2), 1024
]
def __init__(self, num_classes=10):
super(MobileNet, self).__init__()
# 首先是一个标准卷积
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
# 然后堆叠深度可分离卷积
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes) # 输入的特征图大小为1024,输出特征图大小为10
def _make_layers(self, in_planes):
laters = [] #将每层添加到此列表
for x in self.cfg:
out_planes = x if isinstance(x, int) else x[0] #isinstance返回的是一个布尔值
stride = 1 if isinstance(x, int) else x[1]
laters.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*laters)
def forward(self, x):
# 一个普通卷积
out = F.relu(self.bn1(self.conv1(x)))
# 叠加深度可分离卷积
out = self.layers(out)
# 平均池化层会将feature变成1x1
out = F.avg_pool2d(out, 7)
# 展平
out = out.view(out.size(0), -1)
# 全连接层
out = self.linear(out)
# softmax层
output = F.softmax(out, dim=1)
return output
def test():
net = MobileNet()
x = torch.randn(1, 3, 224, 224) # 输入一组数据,通道数为3,高度为224,宽度为224
y = net(x)
print(y.size())
print(y)
print(torch.max(y,dim=1))
test()
net = MobileNet()
print(net)
结果:
torch.Size([1, 10])
tensor([[0.0943, 0.0682, 0.1063, 0.0994, 0.1305, 0.1021, 0.0594, 0.1143, 0.1494,
0.0761]], grad_fn=)
torch.return_types.max(
values=tensor([0.1494], grad_fn=),
indices=tensor([8]))
MobileNet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layers): Sequential(
(0): Block(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
......
......
(12): Block(
(conv1): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024, bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(linear): Linear(in_features=1024, out_features=10, bias=True)
)
4. MobileNet V2

V2这篇文章是18年公开发布的,V2是对V1的改进,同样是一个轻量化卷积神经网络。
4.1 V1存在的问题
作者发现V1在训练阶段卷积核比较容易废掉(训练之后发现深度卷积训练出出来的卷积和不少是空的)。作者认为这是RELU的锅,它的结论是对低维度数据做ReLU运算,很容易造成信息丢失;但是在高维度做ReLU运算,信息丢失会降低。

4.2 V2的改进:
(改进的东西全写在标题上了)
- linear bottleneck:将最后的ReLU6换成Linear

- Expansion layer: 逐深度卷积部分的in_channels=out_channels如果输入的通道很少的话,逐深度卷积只能在低维度上工作,这样带来的后果ReLU会告诉你。所以要用逐点卷积(1*1卷积)来“扩张”通道。在逐深度卷积之前使用逐点卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征:

- Inverted residuals: 使用shortcut网络结构(作者命名为Inverted residuals)跟Resnet的网络差不多是相反的:

- ResNet 是先降维 (0.25倍)、卷积、再升维
- MobileNetV2 是先升维 (6倍)、卷积、再降维
4.3 V1和V2的block对比

看上图的(b)(d)对比:
-
(b)是v1的block,没有Shortcut并且带最后的ReLU6;
-
(d)是v2的加入了1×1升维,引入Shortcut并且去掉了最后的ReLU,改为Linear。
(1)步长为1时,经过升维,提取特征,再降维。最后将input与output相加,形成残差结构。
(2)步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构,其余都是一样的。
import torch
import torch.nn as nn
class Bottleneck(nn.Module):
def __init__(self, x):
super().__init__()
self.cfg = x
# 逐点卷积(先升维)
self.conv1x1_1 = nn.Sequential(
nn.Conv2d(self.cfg[0], self.cfg[1], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(self.cfg[1]),
nn.ReLU6()
)
# 逐深度卷积(add1)
self.conv3x3 = nn.Sequential(
nn.Conv2d(self.cfg[2], self.cfg[3], kernel_size=3, padding=1, stride=self.cfg[6]),
nn.BatchNorm2d(self.cfg[3]),
nn.ReLU6()
)
# 逐点卷积
self.conv1x1_2 = nn.Sequential(
nn.Conv2d(self.cfg[4], self.cfg[5], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(self.cfg[5]),
nn.ReLU6()
)
# Inverted residuals(shortcut网络)
def forward(self, x):
if self.cfg[7] == 1:
residual = x
output = self.conv1x1_1(x)
output = self.conv3x3(output)
output = self.conv1x1_2(output)
if self.cfg[7] == 1: # stride=1进行相加操作
output += residual
return output
class MobileNetV2(nn.Module):
cfg = [
# in-out-in-out-in-out-stride-residual
(32, 32, 32, 32, 32, 16, 1, 0),
(16, 96, 96, 96, 96, 24, 2, 0),
(24, 144, 144, 144, 144, 24, 1, 1), # add1
(24, 144, 144, 144, 144, 32, 2, 0),
(32, 192, 192, 192, 192, 32, 1, 1), # add2
(32, 192, 192, 192, 192, 32, 1, 1), # add3
(32, 192, 192, 192, 192, 64, 1, 0),
(64, 384, 384, 384, 384, 64, 1, 1), # add4
(64, 384, 384, 384, 384, 64, 1, 1), # add5
(64, 384, 384, 384, 384, 64, 1, 1), # add6
(64, 384, 384, 384, 384, 96, 2, 0),
(96, 576, 576, 576, 576, 96, 1, 1), # add7
(96, 576, 576, 576, 576, 96, 1, 1), # add8
(96, 576, 576, 576, 576, 160, 2, 0),
(160, 960, 960, 960, 960, 160, 1, 1), # add9
(160, 960, 960, 960, 960, 160, 1, 1), # add10
(160, 960, 960, 960, 960, 320, 1, 0), # add11
]
def __init__(self, in_channel=3, NUM_CLASSES=10):
super().__init__()
# 首先一个普通卷积
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, 32, kernel_size=3, padding=1, stride=2),
nn.BatchNorm2d(32),
nn.ReLU6()
)
# 深度卷积可分离+Inverted residuals
self.layers = self._make_layers()
# 将逐点卷积
self.conv2 = nn.Sequential(
nn.Conv2d(320, 1280, kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(1280),
nn.ReLU6()
)
# 全局平均池化,将图像变成1x1大小
self.pool = nn.AvgPool2d(kernel_size=7)
# 最后为全连接
self.linear = nn.Sequential(
nn.Linear(1280, NUM_CLASSES)
)
def _make_layers(self):
layers = []
for x in self.cfg:
layers.append(Bottleneck(x))
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.layers(output)
output = self.conv2(output)
output = self.pool(output)
output = output.view(output.size(0), -1)
output = self.linear(output)
return output
def test():
net = MobileNetV2()
x = torch.randn(1, 3, 224, 224) # 输入一组数据,通道数为3,高度为224,宽度为224
y = net(x)
print(y.size())
test()
net = MobileNetV2()
print(net)
结果:
torch.Size([1, 10])
5. 总结
MobileNet系列
-
MobileNet_V1
创新点:
-
提出了MobileNet架构,使用深度可分离卷积(depthwise separable convolutions)替代传统卷积
-
在MobileNet网络中还引入了两个收缩超参数(shrinking hyperparameters):宽度乘子(width multiplier)和分辨率乘子(resolution multiplier)
存在的问题:
Depthwise Convolution存在潜在问题,训练后部分信息丢失,导致部分kernel的权值为0。
-
MobileNet_V2
创新点:
-
修改最后一层RELU6,引入Linear Bottleneck
-
引入Inverted Residual Blocks,想像Resnet一样复用我们的特征,所以我们引入了shortcut结构
存在的问题:
MobileNetV2 网络端部最后阶段的计算量很大
- MobileNetV3已经在2019年发布了,用神经结构搜索(NAS):

创新点:
- 针对V2的问题,提出了新的损失swish x能够有效的改进网络精度:
由于计算量,对它做的改进:
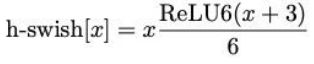
关于激活函数Swish:[https://blog.csdn.net/qq_36330643/article/details/78474141]