用商汤的mmdetection 学习目标检测中的 Recalls, Precisions, AP, mAP 算法 Part2
还没看part1 的请移步 用商汤的mmdetection 学习目标检测中的 Recalls, Precisions, AP, mAP 算法 Part1
好的,在part1 中·我们已经求的了TP 以及 FP, 也就是检测出的所有可能(无论是对的还是错的)
我们先整理一下求到的值, 一共是两类 label1 和 label2 人和汽车类
第一类 label 1 : 人
还记得我们对于第一类总共检测到了11个值对吧? 所以一共会tp+fp一共会有11个值, 0就表示tp 和 fp 互补的值, 这个不用在意, 同理label2 也是一样的 检测到了9个
#图1
tp: [[1. 1. 0. 1. 1.]]
fp: [[0. 0. 1. 0. 0.]]
#图2
tp: [[0. 0. 0. 0. 0. 0.]]
fp: [[1. 1. 1. 1. 1. 1.]]
第二类 label2 : 汽车
#图1
tp: [[0. 0. 0. 0.]]
fp: [[1. 1. 1. 1.]]
#图2
tp: [[1. 1. 0. 1. 0.]]
fp: [[0. 0. 1. 0. 1.]]
将同一类的整理在一起, tp和tp一起 fp和fp一起
这样很清楚的只有两类
tp (array([[1., 1., 0., 1., 1.]], dtype=float32), array([[0., 0., 0., 0., 0., 0.]], dtype=float32))
fp (array([[0., 0., 1., 0., 0.]], dtype=float32), array([[1., 1., 1., 1., 1., 1.]], dtype=float32))
现在我们需要将label1 label2 的tp fp 集合在一起, 并且按照confidence score排序
等等? 什么是confidence score刚刚没说也没出现啊?
其实这个就是confidence score就是最后基于所有label1 和 label2 利用softmax所计算出来的概率, 透过计算出来的数值来获得检测的类别
这里附上一张Faster rcnn的流程, 是我基于chenyun大神simple-faster rcnn绘制的flowchart

红框处可见最终要预测类别时用的是softmax
所以confidence score的值会介于[0, 1]之间
那么模型检测出来的值, 除了坐标之外, 最后一个column也包含score
det_results1_1 = np.array([[359, 289, 499, 388, 0.97], # ok
[346, 415, 515, 560, 0.85], # ok
[367, 109, 468, 179, 0.75], #ok
[190, 78, 324, 152, 0.75], #ok
[430, 172, 588, 253, 0.83]], dtype=np.float32)#ok
det_results1_2 = np.array([[259, 189, 399, 288, 0.79], #not ok
[236, 315, 415, 440, 0.75], #not ok
[267, 9, 368, 79, 0.23], #not ok
[290, 178, 424, 252, 0.53]], dtype=np.float32) #not ok
det_results2_1 = np.array([[359, 289, 499, 388, 0.01], #not ok
[346, 415, 515, 560, 0.02], #not ok
[367, 109, 468, 179, 0.09], #not ok
[190, 78, 324, 152, 0.08], #not ok
[430, 172, 588, 253, 0.04], #not ok
[230, 72, 388, 53, 0.12]], dtype=np.float32) #not ok
# det_results2_1 = np.array([[359, 289, 499, 388, 0.99], #not ok
# [346, 415, 515, 560, 0.99], #not ok
# [367, 109, 468, 179, 0.87], #not ok
# [190, 78, 324, 152, 0.97], #not ok
# [430, 172, 588, 253, 0.84], #not ok
# [230, 72, 388, 53, 0.72]], dtype=np.float32) #not ok
det_results2_2 = np.array([[259, 189, 399, 288, 0.85], #ok
[236, 315, 415, 440, 0.67], #ok
[267, 9, 368, 79, 0.23], #not ok gt=label 1
[290, 178, 424, 252, 0.78],#ok
[159, 89, 299, 188, 0.89]], dtype=np.float32) #not ok
现在有了score之后, 现在可以回到本章一开始说的
我们将tp和fp 集合起来并且依照score排序
# sort all det bboxes by score, also sort tp and fp
cls_dets = np.vstack(cls_dets)
num_dets = cls_dets.shape[0]
sort_inds = np.argsort(-cls_dets[:, -1]) #由检测到score 由大到小取出index
tp = np.hstack(tp)[:, sort_inds] #将tp集合起来
fp = np.hstack(fp)[:, sort_inds] #将fp集合起来
就会得到
集合起来并且依照score 大到小排序之后
label 1
tp [[1. 1. 1. 0. 1. 0. 0. 0. 0. 0. 0.]]
fp [[0. 0. 0. 1. 0. 1. 1. 1. 1. 1. 1.]]
label 2
tp [[0. 1. 0. 1. 0. 1. 0. 0. 0.]]
fp [[1. 0. 1. 0. 1. 0. 1. 1. 1.]]
可以确认一下还是label 1 还是11个值, label2 还是9个值
Accumulated TP and FP
好了TP和FP明确了 这样就能计算recalls and precisions了吗?
还差一步
就是我们要将tp 和 fp进行逐元素累加
tp = np.cumsum(tp, axis=1)
fp = np.cumsum(fp, axis=1)
label 1
tp [[1. 2. 3. 3. 4. 4. 4. 4. 4. 4. 4.]]
fp [[0. 0. 0. 1. 1. 2. 3. 4. 5. 6. 7.]]
label 2
tp [[0. 1. 1. 2. 2. 3. 3. 3. 3.]]
fp [[1. 1. 2. 2. 3. 3. 4. 5. 6.]]
解释一下为什么需要cumsum, 因为这边的tp和fp都是逐单个目标来判别是TP 还是 FP
这样并不具备计算出recalls 和 precisions,
回顾一下公式
recalls = T P T P + F N \frac{TP}{TP+FN} TP+FNTP ,还记得TP+FN 是该类别所有ground truth对吧?
那么如果不进行累加, 我们来看第一个label1 的没有进行累加前的值
tp 的第6个元素为0
该类别图1+图2一共出现5个ground truth
那么TP / all ground truth = 0 / 5 = 0, 这个0完全没办法表达模型随着阈值的不同, 所预测的召回率,
这样很明显的一点意义也没有, 所以前面统计出来的TP FP都要进行累加,
然后根据累加的TP 和 FP 计算出precision 和 recalls
如何计算就依照前面的公式就行, 这部分初中生数学就不一一解释
Calculate Precision and recalls
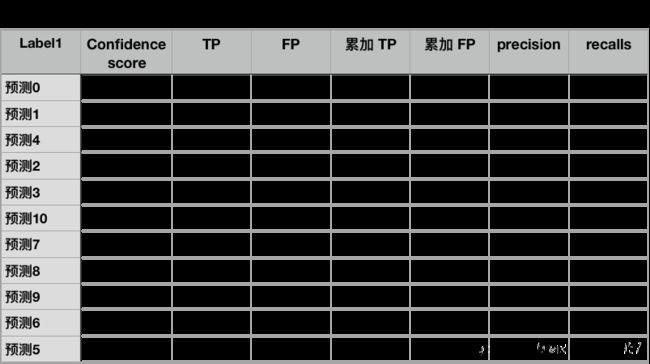
好了 求得所有的recalls 和 precisions 算是完成任务的一半了
再来我们用得到的点plot出图
PR curve
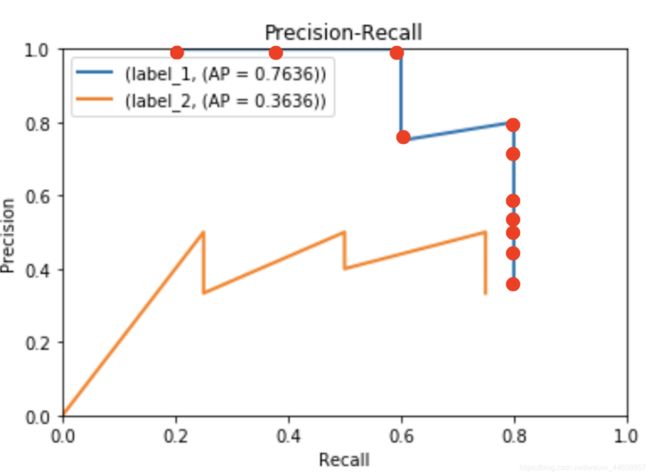
很清楚 label1 是蓝线
红点就是我们recalls对照precisions的值
如此就能绘制出一个也是很重要的 PR curves
有了recalls 和 precisions 计算AP 平均精度就不是难事了
AP的计算依照VOC有两种 大家应该都晓得的2007 和 2010的评测方式
2010 VOC Area method
07的是11points method 记在心里就可
主要讲解2010的 “area” 方法
2010的方法是透过算PR curve下的面积所得到
让我老套的把公式搬出

p ( r ) p(r) p(r) 就是在 r e c a l l ( r ) recall (r) recall(r)时候的precision
那在这个插值法中, 取的是最大precision值对应到recall值大于或是等于r + 1,老实说我看这段话也是一脸懵逼, 你只要知道
我们是尽可能的在每一个recalls取最大的precisions, 画出面积就如下图
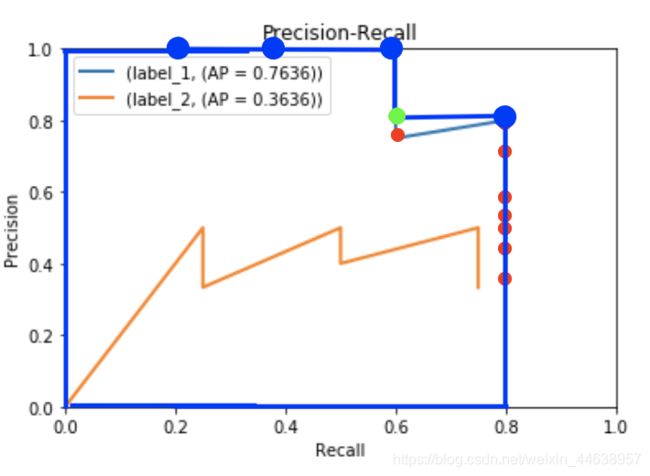
可以看到明明recall 0.6的地方对应到的是0.75 红点, 但是却取了后面一个recalls的precision, 也就是绿色的点 0.8, 这不就对应到了公式的r+1吗? 我们要取的是最大的, 那么后一个值是0.8 大于原来红色的0.75, 所以我们取0.8
这个就是area method 的不同之处, 如此一来你所计算的面积可以想象成你的PR curve中最向右上方扩张最大的面积, 把斜线都拉成水平直线
最终我们只要把面积算出来就取得AP值了
Calculate AP every class
老样子还是要搬出mmdetection的代码来核实一下证明我不是在乱盖
ap = average_precision(recalls, precisions, mode)
#函数中内容就不讲了, 看完下面你就能明白
蓝色的 面积就很好计算了
分成两块矩形
- 左半部的 0.6 ∗ 1.0 = 0.6 0.6 * 1.0 = 0.6 0.6∗1.0=0.6
- 右半部的 ( 0.8 − 0.6 ) ∗ 0.8 = 0.16 (0.8 - 0.6) * 0.8 = 0.16 (0.8−0.6)∗0.8=0.16
- 两个相加 0.6 + 0.16 = 0.76 0.6 + 0.16 = 0.76 0.6+0.16=0.76
就得到了Label 1的AP值为0.76 !
聪明的你一定早就知道 Label2 该怎么算AP了
我就不算了(累)
这个年代有计算机的嘛 干嘛不用?
图表上已经计算出Label2 AP= 0.36了
如今我们已经取得了所有武器, 最后的mAP大魔王也不是对手了
mean Average precision 就是将所有的类别加起来之后除以类别总数不就是均值了吗?
0.76 + 0.36 2 \frac{0.76+0.36}{2} 20.76+0.36 = 0.56
最终帮助我们取得战胜大魔头取得 mAP = 0.56
感人 撒花
最后搬出一个自己写的mmdetection visualize图表助手
PR curve F1 measure 目前只针对VOC dataset能算出
COCO有时间再来弄一下
参考
Object_Detection_Metrics 非常有帮助
FasterRCNN-FlowChart 自己画的FasterRCNN FlowChart 基于chenyun版本