寻优方法总结:最速下降法,牛顿下降法,阻尼牛顿法,拟牛顿法DFP/BFGS
机器学习的一个重要组成部分是如何寻找最优参数解。本文就常见寻优方法进行总结,并给出简单python2.7实现,可能文章有点长,大家耐心些。
寻找最优参数解,就是在一块参数区域上,去找到满足约束条件的那组参数。形象描述,比如代价函数是个碗状的,那我们就是去找最底部(代价最小)的那个地方的对应的参数值作为最优解。那么,如何找到那个底部的最优参数解呢,如何由一个初始值,一步一步地接近该最优解呢。寻优方法,提供了靠近最优解的方法,其中涉及到的核心点,无外乎两点:靠近最优解的方向和步幅(每步的长度)。
最优化,分为线性最优化理论和非线性最优化理论。其中线性最优化又称线性规划。目标函数和约束条件的表达是线性的, Y=aX ;非线性最优化理论,是非线性的。其中包括梯度法,牛顿法,拟牛顿法(DFP/BFGS),约束变尺度(SQP),Lagrange乘子法,信赖域法等。
算法原理及简单推导
最速下降法(梯度下降法)
借助梯度,找到下降最快的方向,大小为最大变化率。
θnew=θold−α∗Gradient
梯度:是方向导数中,变化最大的那个方向导数。
梯度方向:标量场中增长最快的方向。
梯度大小:最大变化率。
更新:沿着梯度的负向,更新参数(靠近最优解)。
*********************************************
Algorithm:GradientDescent
Input:x−Data;y−Label;α−调节步幅;θ0;Iternum;
Output:θoptimal
Process:
1. Initial θ=θ0
2. While Loop<Iternum
H=f(x,θ);模型函数H
Compute Gradient According to f(x,θ)
Update θ:=θ−α∗Gradient
Loop=Loop+1
3. Return θ
*********************************************
梯度下降法
优点:方便直观,便于理解。
缺点:下降速度慢,有时参数会震荡在最优解附近无法终止。
牛顿下降法
牛顿下降法,是通过泰勒展开到二阶,推到出参数更新公式的。
f(x+Δ(x))≈f(x)+f′(x)∗Δ(x)+12∗f′′(x)∗Δ2(x)
上式等价于 f′(x)+f′′(x)∗Δ=0
从而得到更新公式:
xnew−xold=−f′(x)f′′(x)=−[f′′(x)]−1∗f′(x)
调整了参数更新的方向和大小(牛顿方向)。
*********************************************
Algorithm:Newton Descent
Input:x−Data;y−label;θ0;ϵ−终止条件;
Ouput:θoptimal
Process:
1. Initial θ=θ0
2. Compute f′(x,θ)
if|f′(x),θ)|⩽ϵ
return θoptimal=θ
else
Compute H=f′′(x,θ)
Dk=−[H]−1∗f′(x,θ)
Update θ:=θ+Dk
3. Return step 2
*********************************************
牛顿下降法
优点:对于正定二次函数,迭代一次,就可以得到极小值点。下降的目的性更强。
缺点:要求二阶可微分;收敛性对初始点的选取依赖性很大;每次迭代都要计算Hessian矩阵,计算量大;计算Dk时,方程组有时奇异或者病态,无法求解Dk或者Dk不是下降方向。
阻尼牛顿法
这是对牛顿法的改进,在求新的迭代点时,以Dk作为搜索方向,进行一维搜索,求步长控制量 α ,使得 α=argminθ[f(θ+α∗Dk)] ,找到 f 下降的 α ,且是 f 下降最大的 α ,然后令 θ=θ+α∗Dk 。克服了牛顿法的奇异和病态方程无解, Dk 非下降的缺点。
*********************************************
Algorithm:Damped Newton Descent
Input:x−Data;y−label;θ0;ϵ
Output:θoptimal
Process:
1. Initial θ=θ0
2. Compute f′(x,θ)
if|f′(x,θ)|⩽ϵ
Return θoptimal=θ
else
Compute H=f′′(x,θ)
Dk=−[H]−1∗f′(x,θ)
Compute α According to:
α=argminθ[f(θ+α∗Dk)]
Update θ:=θ+α∗Dk
3. Return step 2
*********************************************
阻尼牛顿法
优点:修改了下降方向,使得始终朝着下降的方向迭代。
缺点:与牛顿法一样。
一维搜索方法简介
一维无约束优化问题 minF(α) ,求解 F(α) 的极小值和极大值的数值迭代方法,即为一维搜索方法。常用的方法包括:试探法(黄金分割法,fibonacci方法,平分法,格点法);插值法(牛顿法,抛物线法)。
(1)确定最优解所在区间[a,b] (进退法)
思想:从初始点 α0 开始,以步长 h 前进或者后退,试出三个点 f(α0+h),f(α0),f(α0−h) ,满足大,小,大规律。
*********************************************
Process:
1. Initial α1=α0;α2=α0+h;
f1=f(α1;f2=f(α2)
2. if f1>f2
forward,h=2h
else
backward,h=−h;
swqp(α1,α2);
swap(f1,f2);
3. Getthe third point, α3=α2+h;f3=f(α3)
if f3>f2
a=min(α1,α3)
b=max(α1,α3)
Return [a,b]
if f3<f2 :move the point
α1=α2;f1=f2;
α2=α3;f2=f3;
4. Return step 2
*********************************************
(2)在[a, b]内,找到极小值(黄金分割法和平分法)
*********************************************
Process:黄金分割法
1. Initial check point
α1=a+0.382∗(b−a);
α2=a+0.618∗(b−a);
f1=f(α1);
f2=f(α2);
2. Change the edge
if f1>f2
a=α1;b=b;
else
a=a;b=α2
3. Stop condation
if |a−b|⩽ϵ
Return α=(b+a)/2
else
Return step 1
Process:平分法(需要求导数)
1. Initial check point
α=(b+a)/2
2. Compute gradient f′=f′(α)
if f′=0,or |f′|<ϵ
Return α
if f′>0 a=a;b=α;
if f′<0 a=α;b=b;
Return step 1
*********************************************
思考:如何在实际应用中,选择[a, b],函数 f 是什么样子的?这些问题需要讨论。整个优化的目标是:找到最优 θ ,使得代价 CostJ 最小。故此, f=CostJ 。
拟牛顿法 - DFP法
由于牛顿法计算二阶导数,计算量大,故此用其他方法(一阶导数)估计Hessian矩阵的逆。 f(x) 在 Xk+1 处,展开成二阶泰勒级数。
f(x)≈f(xk+1)+f′(xk+1)∗(x−xk+1)+12∗f′′(xk+1)∗(x−xk+1)2
f(x)−f(xk+1)≈f′(xk+1)∗(x−xk+1)+f′′(xk+1)∗(x−xk+1)2
两侧同时除以 x−xk+1 则得到:
f′(x)=f′(xk+1)+f′′(xk+1)∗(x−xk+1)
f′(xk+1)−f′(xk)≈f′′(xk+1)∗(xk+1−x)
令 sk=xk+1−xk;yk=f′(xk+1)−f′(xk);
则 yk=f′′(xk+1)∗sk
且 sk=[f′′(xk+1)]−1∗yk
用上式来估计Hessian的逆。设 H=[f′′(xk+1)]−1
根据H的构造函数不同,分为不同的拟牛顿方法,下面为DFP方法:
Hk+1=Hk+DH
DH=sk∗sk′sk′∗yk−Hk∗yk∗yk′∗Hkyk′∗Hk∗yk
*********************************************
Algorithm:DFP Quasi−Newton Method
Input:x−Data;y−Label;θ0;ϵ
Output:θoptimal
Process:
1. Initial paraments
θ=θ0; H=I; Dk=−f′(xk,θ)
2. if |f′(xk,θ)|⩽ϵ
Returnθoptimal=θ
else
Compute α according to:
α=argminθ[f(θ+α∗Dk)]
Update θ:=θ+α∗Dk
Update H as follow:
sk=θk+1−θk
yk=f′(xk+1)−f′(xk)
DH=sk∗sk′sk′∗yk−H∗yk∗yk′∗Hyk′∗H∗yk
H:=H+DH
Dk=−H∗f′(xk,θ)
3. Return step 2
*********************************************
拟牛顿法DFP:
优点:减少了二阶计算,运算量大大降低。
拟牛顿法 - BFGS法
若构造函数如下,则为BFGS法。
Hk+1=Hk+DH
DH=[1+yk′∗Hk∗yksk′∗yk]∗sk∗sk′sk′∗yk−sk∗yk′∗Hksk′∗yk
*********************************************
Algorithm: BFGS Quasi−Newton Method
Input:x−Data;y−Label;θ0;ϵ
Output:θoptimal
Process:
1. Initial paraments
θ=θ0;H=I;Dk=−f′(xk,θ);
2. if |f′(xk,θ)|⩽ϵ
Return θoptimal=θ
else
Compute α according to:
α=argminα[f(θ+α∗Dk)]
Update θ:=θ+α∗Dk
Update H as follow:
sk=θk+1−θk
yk=f′(xk+1)−f′(xk)
DH=[1+yk′∗H∗yksk′∗yk]∗sk∗sk′sk′∗yk−sk∗yk′∗Hsk′∗yk
H:=H+DH
Dk=−H∗f′(xk,θ)
3. Return step 2
*********************************************
拟牛顿法是无约束最优化方法中最有效的一类算法。
算法的Python实现代码
Python2.7需要安装pandas, numpy, scipy, matplotlib。
下面给出Windows7下exe方式按照上面模块的简单方法。
numpy–http://sourceforge.net/projects/numpy/files/ –这里面也可以找到较新的scipy –
scipy–http://download.csdn.net/detail/caanyee/8241305
pandas-https://pypi.python.org/packages/2.7/p/pandas/pandas-0.12.0.win32-py2.7.exe#md5=80b0b9b891842ef4bdf451ac07b368e5
test.py
# coding = utf-8
'''
time: 2015.06.03
author: yujianmin
objection: BGD / SGD / mini-batch GD / QNGD / DFP / BFGS
实现了批量梯度下降、单个梯度下降; 最速下降法、牛顿下降法、阻尼牛顿法、拟牛顿DFP和BFGS
'''
import pandas as pd
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
data = pd.read_csv("C:\\Users\\yujianmin\\Desktop\\python\\arraydataR.csv")
print(data.ix[1:5, :])
dataArray = np.array(data)
'''
x = dataArray[:, 0]
y = dataArray[:, 1]
plt.plot(x, y, 'o')
plt.title('data is like this')
plt.xlabel('x feature')
plt.ylabel('y label')
plt.show()
'''
def Myfunction_BGD(data, alpha, numIter, eplise):
''' Batch Gradient Descent
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
#eplise = 0.4
while i < numIter:
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
if np.sum(np.fabs(Gradient))<= eplise:
return theta, costJ
else:
## update
theta = theta + alpha * Gradient
i = i + 1
return theta, costJ
def Myfunction_SGD(data, alpha, numIter, eplise):
''' Stochastic Gradient Descent
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
Loop = 0
costJ = []
while Loop 2)/(2*nRow)
print('Itering %d ;cost is:%f' %(Loop+1,J))
costJ.append(J)
i = 0
while i 1, 1)
theta = theta + alpha * Gradient
i = i + 1
#eplise = 0.4
Gradient = (np.dot(np.transpose(y-H),x))/nRow
if np.sum(np.fabs(Gradient))<= eplise:
return theta, costJ
Loop = Loop + 1
return theta, costJ
def Myfunction_NGD1(data, alpha, numIter, eplise):
''' Newton Gradient Descent -- theta := theta - alpha*[f'']^(-1)*f'
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://www.doc88.com/p-145660070193.html
:hessian = transpos(x) * x
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
while i < numIter:
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
#eplise = 0.4
if np.sum(np.fabs(Gradient))<=eplise:
return theta, costJ
Hessian = np.dot(np.transpose(x), x)/nRow
theta = theta + alpha * np.dot(np.linalg.inv(Hessian), Gradient)
#theta = theta + np.dot(np.linalg.inv(Hessian), Gradient)
i = i + 1
return theta, costJ
def Myfunction_NGD2(data, alpha, numIter, eplise):
''' Newton Gradient Descent -- theta := theta - [f'']^(-1)*f'
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://www.doc88.com/p-145660070193.html
:hessian = transpos(x) * x
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
while i < numIter:
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
#eplise = 0.4
if np.sum(np.fabs(Gradient)) <= eplise:
return theta, costJ
Hessian = np.dot(np.transpose(x), x)/nRow
theta = theta + np.dot(np.linalg.inv(Hessian), Gradient)
i = i + 1
return theta, costJ
def Myfunction_QNGD(data, alpha, numIter, eplise):
''' Newton Gradient Descent -- theta := theta - alpha* [f'']^(-1)*f'--
alpha is search by ForwardAndBack method and huang jin fen ge
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://www.doc88.com/p-145660070193.html
:hessian = transpos(x) * x
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
#eplise = 0.4
while i < numIter:
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
if np.sum(np.fabs(Gradient))<= eplise:
return theta, costJ
else:
Hessian = np.dot(np.transpose(x), x)/nRow
Dk = - np.dot(np.linalg.inv(Hessian), Gradient)
## find optimal [a,b] which contain optimal alpha
## optimal alpha lead to min{f(theta + alpha*DK)}
alpha0 = 0
h = np.random.random(1)
alpha1 = alpha0
alpha2 = alpha0 + h
theta1 = theta + alpha1 * Dk
theta2 = theta + alpha2 * Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
Loop = 1
a = 0
b = 0
while Loop >0:
print(' find [a,b] loop is %d' %Loop)
Loop = Loop + 1
if f1 > f2:
h = 2*h
else:
h = -h
(alpha1, alpha2) = (alpha2, alpha1)
(f1, f2) = (f2, f1)
alpha3 = alpha2 + h
theta3 = theta + alpha3 * Dk
f3 = (np.sum((y-np.dot(x, theta3))**2))/(2*nRow)
print('f3 - f2 is %f' %(f3-f2))
if f3 > f2:
a = min(alpha1, alpha3)
b = max(alpha1, alpha3)
break
if f3 <= f2:
alpha1 = alpha2
alpha2 = alpha3
f1 = f2
f2 = f3
## find optiaml alpha in [a,b] using huang jin fen ge fa
e = 0.01
while Loop >0:
alpha1 = a + 0.382 * (b - a)
alpha2 = a + 0.618 * (b - a)
theta1 = theta + alpha1* Dk
theta2 = theta + alpha2* Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
if f1 > f2:
a = alpha1
if f1< f2:
b = alpha2
if np.fabs(a-b) <= e:
alpha = (a+b)/2
break
print('optimal alpha is %f' % alpha)
theta = theta + alpha * Dk
i = i + 1
return theta, costJ
def Myfunction_DFP2(data, alpha, numIter, eplise):
''' DFP -- theta := theta + alpha * Dk
--alpha is searched by huangjin method
--satisfied argmin{f(theta+alpha*Dk)}##
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://blog.pfan.cn/miaowei/52925.html
:reference:http://max.book118.com/html/2012/1025/3119007.shtm ## important ##
:hessian is estimated by DFP method.
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
Hessian = np.eye(nCol+1)
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
#costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
Dk = - Gradient
#eplise = 0.4
while i < numIter:
if(np.sum(np.fabs(Dk)) <= eplise ): ## stop condition ##
return theta, costJ
else:
## find alpha that min f(thetaK + alpha * Dk)
## find optimal [a,b] which contain optimal alpha
## optimal alpha lead to min{f(theta + alpha*DK)}
alpha0 = 0
h = np.random.random(1)
alpha1 = alpha0
alpha2 = alpha0 + h
theta1 = theta + alpha1 * Dk
theta2 = theta + alpha2 * Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
Loop = 1
a = 0
b = 0
while Loop >0:
print(' find [a,b] loop is %d' %Loop)
Loop = Loop + 1
if f1 > f2:
h = 2*h
else:
h = -h
(alpha1, alpha2) = (alpha2, alpha1)
(f1, f2) = (f2, f1)
alpha3 = alpha2 + h
theta3 = theta + alpha3 * Dk
f3 = (np.sum((y-np.dot(x, theta3))**2))/(2*nRow)
print('f3 - f2 is %f' %(f3-f2))
if f3 > f2:
a = min(alpha1, alpha3)
b = max(alpha1, alpha3)
break
if f3 <= f2:
alpha1 = alpha2
alpha2 = alpha3
f1 = f2
f2 = f3
## find optiaml alpha in [a,b] using huang jin fen ge fa
e = 0.01
while Loop >0:
alpha1 = a + 0.382 * (b - a)
alpha2 = a + 0.618 * (b - a)
theta1 = theta + alpha1* Dk
theta2 = theta + alpha2* Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
if f1 > f2:
a = alpha1
if f1< f2:
b = alpha2
if np.fabs(a-b) <= e:
alpha = (a+b)/2
break
print('optimal alpha is %f' % alpha)
theta_old = theta
theta = theta + alpha * Dk
## update the Hessian matrix ##
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
# here to estimate Hessian'inv #
# sk = ThetaNew - ThetaOld = alpha * inv(H) * Gradient
sk = theta - theta_old
#yk = DelX(k+1) - DelX(k)
DelXK = - (np.dot(np.transpose(y-np.dot(x, theta)),x))/nRow
DelXk = - (np.dot(np.transpose(y-np.dot(x, theta_old)),x))/nRow
yk = (DelXK - DelXk).reshape(nCol+1, 1)
#z1 = (sk * sk') # a matrix
#z2 = (sk' * yk) # a value
z1 = sk * np.transpose(sk)
z2 = np.dot(np.transpose(sk),yk)
#z3 = (H * yk * yk' * H) # a matrix
#z4 = (yk' * H * yk) # a value
z3 = np.dot(np.dot(np.dot(Hessian, yk), np.transpose(yk)), Hessian)
z4 = np.dot(np.dot(np.transpose(yk), Hessian),yk)
DHessian = z1/z2 - z3/z4
Hessian = Hessian + DHessian
Dk = - np.dot(Hessian, DelXK.reshape(nCol+1,1))
i = i + 1
return theta, costJ
def Myfunction_DFP1(data, alpha, numIter, eplise):
''' DFP -- theta := theta + alpha * Dk
alpha is fixed ##
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://blog.pfan.cn/miaowei/52925.html
:reference:http://max.book118.com/html/2012/1025/3119007.shtm ## important ##
:hessian is estimated by DFP method.
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
Hessian = np.eye(nCol+1)
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
#costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
Dk = - Gradient
#eplise = 0.4
while i < numIter:
if(np.sum(np.fabs(Dk)) <= eplise ): ## stop condition ##
return theta, costJ
else:
## find alpha that min f(thetaK + alpha * Dk)
## here for simple alpha is parameter 'alpha'
alpha = alpha
theta_old = theta
theta = theta + alpha * Dk
## update the Hessian matrix ##
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
# here to estimate Hessian'inv #
# sk = ThetaNew - ThetaOld = alpha * inv(H) * Gradient
sk = theta - theta_old
#yk = DelX(k+1) - DelX(k)
DelXK = - (np.dot(np.transpose(y-np.dot(x, theta)),x))/nRow
DelXk = - (np.dot(np.transpose(y-np.dot(x, theta_old)),x))/nRow
yk = (DelXK - DelXk).reshape(nCol+1, 1)
#z1 = (sk * sk') # a matrix
#z2 = (sk' * yk) # a value
z1 = sk * np.transpose(sk)
z2 = np.dot(np.transpose(sk),yk)
#z3 = (H * yk * yk' * H) # a matrix
#z4 = (yk' * H * yk) # a value
z3 = np.dot(np.dot(np.dot(Hessian, yk), np.transpose(yk)), Hessian)
z4 = np.dot(np.dot(np.transpose(yk), Hessian),yk)
DHessian = z1/z2 - z3/z4
Hessian = Hessian + DHessian
Dk = - np.dot(Hessian, DelXK.reshape(nCol+1,1))
i = i + 1
return theta, costJ
def Myfunction_BFGS1(data, alpha, numIter, eplise):
''' BFGS
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://blog.pfan.cn/miaowei/52925.html
:reference:http://max.book118.com/html/2012/1025/3119007.shtm ## important ##
:hessian is estimated by BFGS method.
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
Hessian = np.eye(nCol+1)
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
#costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
Dk = - Gradient
#eplise = 0.4
while i < numIter:
if(np.sum(np.fabs(Dk)) <= eplise ): ## stop condition ##
return theta, costJ
else:
## find alpha that min J(thetaK + alpha * Dk)
## here for simple alpha is parameter 'alpha'
alpha = alpha
theta_old = theta
theta = theta + alpha * Dk
## update the Hessian matrix ##
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
# here to estimate Hessian #
# sk = ThetaNew - ThetaOld = alpha * inv(H) * Gradient
sk = theta - theta_old
#yk = DelX(k+1) - DelX(k)
DelXK = - (np.dot(np.transpose(y-np.dot(x, theta)),x))/nRow
DelXk = - (np.dot(np.transpose(y-np.dot(x, theta_old)),x))/nRow
yk = (DelXK - DelXk).reshape(nCol+1, 1)
#z1 = yk' * H * yk # a value
#z2 = (sk' * yk) # a value
z1 = np.dot(np.dot(np.transpose(yk), Hessian), yk)
z2 = np.dot(np.transpose(sk),yk)
#z3 = sk * sk' # a matrix
#z4 = sk * yk' * H # a matrix
z3 = np.dot(sk, np.transpose(sk))
z4 = np.dot(np.dot(sk, np.transpose(yk)), Hessian)
DHessian = (1+z1/z2) * (z3/z2) - z4/z2
Hessian = Hessian + DHessian
Dk = - np.dot(Hessian, DelXK.reshape(nCol+1,1))
i = i + 1
return theta, costJ
def Myfunction_BFGS2(data, alpha, numIter, eplise):
''' BFGS
:type data: array
:param data: contain x and y(label)
:type step: int/float numeric
:param step: length of step when update the theta
:reference:http://blog.pfan.cn/miaowei/52925.html
:reference:http://max.book118.com/html/2012/1025/3119007.shtm ## important ##
:hessian is estimated by BFGS method.
'''
nCol = data.shape[1]-1
nRow = data.shape[0]
print nCol
print nRow
x = data[:, :nCol]
print x[1:5, :]
z = np.ones(nRow).reshape(nRow, 1)
x = np.hstack((z, x)) ## vstack merge like rbind in R; hstack like cbind in R;
y = data[:, (nCol)].reshape(nRow, 1)
#theta = np.random.random(nCol+1).reshape(nCol+1, 1)
theta = np.ones(nCol+1).reshape(nCol+1, 1)
i = 0
costJ = []
Hessian = np.eye(nCol+1)
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
#costJ.append(J)
Gradient = (np.dot(np.transpose(y-H),x))/nRow
Gradient = Gradient.reshape(nCol+1, 1)
Dk = - Gradient
#eplise = 0.4
while i < numIter:
if(np.sum(np.fabs(Dk)) <= eplise ): ## stop condition ##
return theta, costJ
else:
## find alpha that min J(thetaK + alpha * Dk)
alpha = alpha
## find optimal [a,b] which contain optimal alpha
## optimal alpha lead to min{f(theta + alpha*DK)}
'''
alpha0 = 0
h = np.random.random(1)
alpha1 = alpha0
alpha2 = alpha0 + h
theta1 = theta + alpha1 * Dk
theta2 = theta + alpha2 * Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
Loop = 1
a = 0
b = 0
while Loop >0:
print(' find [a,b] loop is %d' %Loop)
Loop = Loop + 1
if f1 > f2:
h = 2*h
else:
h = -h
(alpha1, alpha2) = (alpha2, alpha1)
(f1, f2) = (f2, f1)
alpha3 = alpha2 + h
theta3 = theta + alpha3 * Dk
f3 = (np.sum((y-np.dot(x, theta3))**2))/(2*nRow)
print('f3 - f2 is %f' %(f3-f2))
if f3 > f2:
a = min(alpha1, alpha3)
b = max(alpha1, alpha3)
break
if f3 <= f2:
alpha1 = alpha2
alpha2 = alpha3
f1 = f2
f2 = f3
## find optiaml alpha in [a,b] using huang jin fen ge fa
e = 0.01
while Loop >0:
alpha1 = a + 0.382 * (b - a)
alpha2 = a + 0.618 * (b - a)
theta1 = theta + alpha1* Dk
theta2 = theta + alpha2* Dk
f1 = (np.sum((y-np.dot(x, theta1))**2))/(2*nRow)
f2 = (np.sum((y-np.dot(x, theta2))**2))/(2*nRow)
if f1 > f2:
a = alpha1
if f1< f2:
b = alpha2
if np.fabs(a-b) <= e:
alpha = (a+b)/2
break
print('optimal alpha is %f' % alpha)
'''
## Get Dk and update Hessian
theta_old = theta
theta = theta + alpha * Dk
## update the Hessian matrix ##
H = np.dot(x,theta)
J = (np.sum((y-H)**2))/(2*nRow)
## update
print('Itering %d ;cost is:%f' %(i+1,J))
costJ.append(J)
# here to estimate Hessian #
# sk = ThetaNew - ThetaOld = alpha * inv(H) * Gradient
sk = theta - theta_old
#yk = DelX(k+1) - DelX(k)
DelXK = - (np.dot(np.transpose(y-np.dot(x, theta)),x))/nRow
DelXk = - (np.dot(np.transpose(y-np.dot(x, theta_old)),x))/nRow
yk = (DelXK - DelXk).reshape(nCol+1, 1)
#z1 = yk' * H * yk # a value
#z2 = (sk' * yk) # a value
z1 = np.dot(np.dot(np.transpose(yk), Hessian), yk)
z2 = np.dot(np.transpose(sk),yk)
#z3 = sk * sk' # a matrix
#z4 = sk * yk' * H # a matrix
z3 = np.dot(sk, np.transpose(sk))
z4 = np.dot(np.dot(sk, np.transpose(yk)), Hessian)
DHessian = (1+z1/z2) * (z3/z2) - z4/z2
Hessian = Hessian + DHessian
Dk = - np.dot(Hessian, DelXK.reshape(nCol+1,1))
i = i + 1
return theta, costJ
## test ##
num = 10000
#theta, costJ = Myfunction_BGD(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ##
#theta, costJ = Myfunction_SGD(dataArray, alpha=0.00005, numIter=num, eplise=0.4)
#theta, costJ = Myfunction_NGD1(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is fixed ##
#theta, costJ = Myfunction_NGD2(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is 1 ##
#theta, costJ = Myfunction_QNGD(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is searched ##
#theta, costJ = Myfunction_DFP1(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is fixed ##
#theta, costJ = Myfunction_DFP2(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is searched ##
theta, costJ = Myfunction_BFGS1(dataArray, alpha=0.0005, numIter=num, eplise=0.4) ## alpha is fxied ##
print theta
klen = len(costJ)
leng = np.linspace(1, klen, klen)
plt.plot(leng, costJ)
plt.show() 实验数据和结果展示
数据csv格式
0 28.22401669
1 33.24921693
2 35.82084277
3 36.87096878
4 30.98488531
5 38.78221296
6 38.46753324
7 41.96065845
8 36.82656413
9 35.5081121
10 35.74647181
11 36.17110987
12 37.51165999
13 41.27109257
14 44.03842677
15 48.03001705
16 45.50401843
17 45.02635608
18 51.70574034
19 46.76359881
20 52.6487595
21 48.81383593
22 50.69451254
23 55.54200403
24 54.55639586
25 53.19036223
26 58.89269091
27 54.78884251
28 57.9033951
29 62.21114967
30 64.51025468
31 62.20710537
32 62.94736304
33 60.30447933
34 65.32044406
35 65.82903452
36 66.37872216
37 69.75640553
38 66.02112594
39 65.87119039
40 74.27209751
41 67.57661628
42 73.19444088
43 69.4533117
44 74.91129817
45 71.21187609
46 77.0962545
47 81.95066837
48 78.04636838
49 83.42842526
50 80.40217563
51 78.68650206
52 82.91395215
53 85.09663115
54 88.71540907
55 87.73955
56 89.18654776
57 91.09337441
58 83.95614422
59 93.30683179
60 93.27618596
61 88.07859238
62 89.10667856
63 95.61443666
64 93.39899106
65 94.38258758
66 96.87641802
67 96.87896946
68 97.0094412
69 100.076115
70 104.7619905
71 100.7917093
72 99.85523362
73 106.9018494
74 103.6061063
75 103.4105058
76 106.4304576
77 110.7357249
78 107.0420455
79 107.2834221
80 113.9299496
81 111.2187627
82 116.4100596
83 108.0237256
84 112.7773592
85 117.3464957
86 117.1976807
87 120.0538521
88 114.4584964
89 122.2860022结果展示
横轴是迭代次数,纵轴是代价
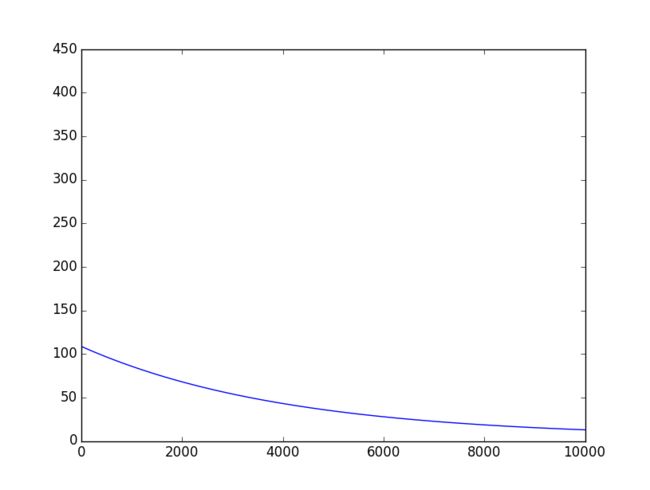


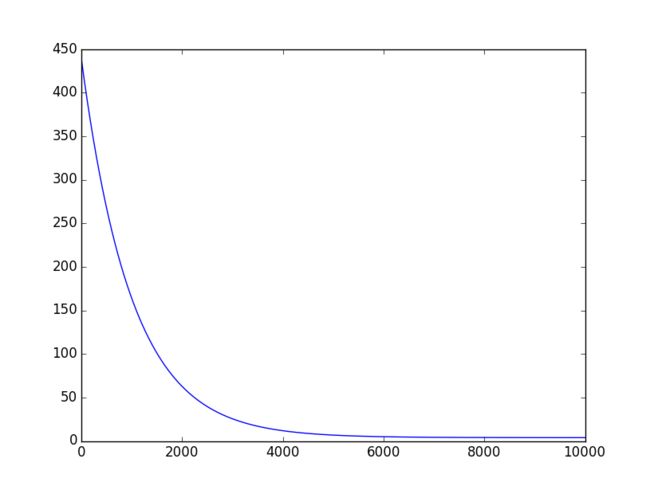
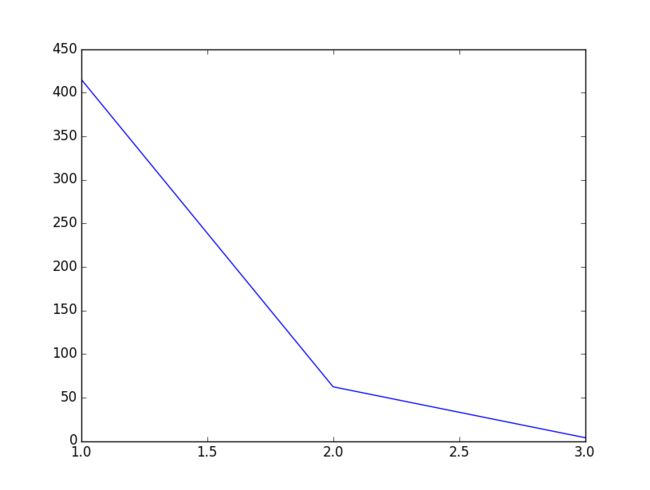
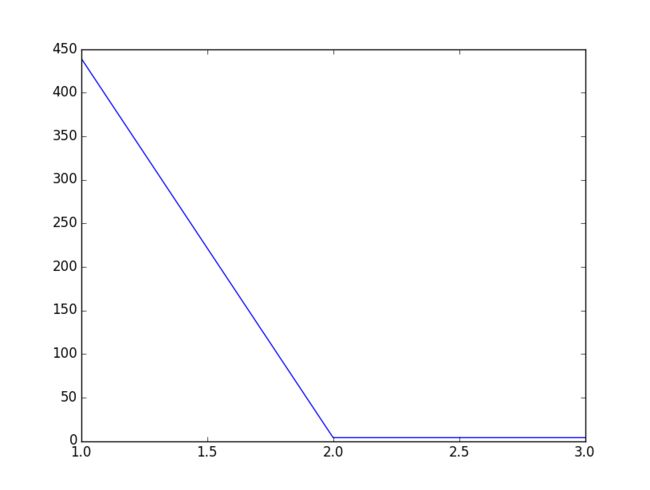
总结
不管什么最优化方法,都是试图去寻找代价下降最快的方向和合适的步幅。