Spark 1.6.2 + Hadoop 2.7.2 集群搭建
版本信息:Centos7 + Hadoop 2.7.2 + Spark 1.6.2 + Scala 2.11.8
Hadoop + Spark 集群搭建系列文章,建议按顺序参考:
Hadoop & Spark 集群搭建 理念思想
Hadoop 2.7.2 集群搭建-预备工作
Hadoop 2.7.2 集群搭建
Spark 1.6.2 + Hadoop 2.7.2 集群搭建 (不用点了,就是本文)
预备工作
JDK 安装配置
请参考 Hadoop 2.7.2 集群搭建-预备工作中 JDK 的安装和配置。
Scala 安装配置
1.下载后解压至合适目录
[liuyao@master ~]$ cd 03Software/04BigData/
[liuyao@master 04BigData]$ tar -xzvf scala-2.11.8.tgz --directory=/home/liuyao/00Hadoop/
scala-2.11.8/
scala-2.11.8/man/
scala-2.11.8/man/man1/
……2.配置环境变量,在 /etc/profile 中添加如下内容
export SCALA_HOME=/home/liuyao/00Hadoop/scala-2.11.8
export PATH=$PATH:${SCALA_HOME}/bin3.使 /etc/profile 文件更新生效
[liuyao@master ~]$ source /etc/profile4.在 master 主机上配置完毕后,把Scala整个文件夹分发到slave各节点,并配置环境变量
SSH配置
主要是配置 SSH 以实现集群各节点间免密码登录(公钥登录),请参考 Hadoop 2.7.2 集群搭建-预备工作中 SSH 的安装和配置。
Hadoop安装配置
此部分所有步骤一一列出,但部分步骤省略操作细节,详情请参考 Hadoop 2.7.2 集群搭建 一文中的内容。
1.下载后解压至合适目录
2.配置 Hadoop 环境变量
3.编辑配置文件
(1) 配置hadoop-env.sh文件
(2) 配置core-site.xml文件
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/liuyao/00Hadoop/hadoop-2.7.2/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.proxyuser.hduser.hostsname> #Hadoop全分布模式里,此处是spark而非hduser?下同
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hduser.groupsname>
<value>*value>
property>
configuration>(3) 配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value> #Hadoop全分布模式里,此处为8035而非8031?
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
configuration>(4) 配置mapred-site.xml文件,完全同Hadoop全分布模式
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>(5) 配置hdfs-site.xml文件,完全同Hadoop全分布模式
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>(6) 配置slaves文件,完全同 Hadoop 全分布模式
101.X.XX.XX1
101.X.XX.XX2(7) 将以上配置文件分发到各个节点,实际上应该直接把整个 Hadoop 目录分发过去(若从节点没安装Hadoop的话)
4.格式化namenode,启动并测试 Hadoop
Spark 安装配置
下载安装并配置环境
1.从官网上下载后解压至合适目录
选择的版本是
spark-1.6.2-bin-hadoop2.6.tgz,虽然Hadoop是2.7.2的,之前下载的是without-hadoop版本,运行出错。
[liuyao@master 04BigData]$ tar -xzvf spark-1.6.2-bin-hadoop2.6.tgz --directory=/home/liuyao/00Hadoop/
spark-1.6.2-bin-hadoop2.6/
spark-1.6.2-bin-hadoop2.6/NOTICE
spark-1.6.2-bin-hadoop2.6/CHANGES.txt
……2.配置 Spark 环境变量,在 /etc/profie 里添加如下两行
export SPARK_HOME=/home/liuyao/00Hadoop/spark-1.6.2-bin-hadoop2.6
export PATH=$PATH:${SPARK_HOME}/bin编辑配置文件
1.配置spark-env.sh文件,加入下面内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.91-0.b14.el7_2.x86_64
export SCALA_HOME=/home/liuyao/00Hadoop/scala-2.11.8
export SPARK_WORKER_MEMORY=4g
export SPARK_MASTER_IP=101.X.XX.XX0
export MASTER=spark://101.X.XX.XX0:7077
export HADOOP_CONF_DIR=/home/liuyao/00Hadoop/hadoop-2.7.2/etc/hadoop2.配置slaves文件,加入下面内容
101.X.XX.XX1
101.X.XX.XX23.将以上配置文件分发到各个节点,实际上应该直接把整个 Spark 目录分发过去(若从节点没安装 Spark 的话)
启动集群
1.启动 Hadoop
# master节点
[liuyao@master hadoop-2.7.2]$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to ……
101.X.XX.XX2: starting datanode, logging to ……
101.X.XX.XX1: starting datanode, logging to ……
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to ……
[liuyao@master hadoop-2.7.2]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to ……
101.X.XX.XX2: starting nodemanager, logging to ……
101.X.XX.XX1: starting nodemanager, logging to ……
[liuyao@master hadoop-2.7.2]$ jps
6441 Jps
5755 SecondaryNameNode
5373 NameNode
6126 ResourceManager# slave1节点,slave2节点与之一样
[liuyao@slave1 hadoop-2.7.2]$ jps
5328 DataNode
5958 Jps
5661 NodeManager2.启动 Spark
# master节点,可以看到,成功启动了Master进程
[liuyao@master spark-1.6.2-bin-hadoop2.6]$ ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to ……
101.X.XX.XX2: starting org.apache.spark.deploy.worker.Worker, logging to ……
101.X.XX.XX1: starting org.apache.spark.deploy.worker.Worker, logging to ……
[liuyao@master spark-1.6.2-bin-hadoop2.6]$ jps
6485 Master
6584 Jps
5755 SecondaryNameNode
5373 NameNode
6126 ResourceManager# slave1节点,可以看到,成功启动了Worker进程,slave2节点与之一样
[liuyao@slave1 hadoop-2.7.2]$ jps
5328 DataNode
6090 Worker
6282 Jps
5661 NodeManager集群测试
Spark支持两种方式运行样例: run-example 方式和 Spark Shell 方式
1.run-example 方式
(1) 输入代码
[liuyao@master spark-1.6.2-bin-hadoop2.6]$ ./bin/run-example org.apache.spark.examples.SparkPi
16/07/16 22:39:22 INFO spark.SparkContext: Running Spark version 1.6.2
16/07/16 22:39:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
……(2) 通过Web UI 查看集群状态
浏览器中输入http://master:8080,可以观察集群整个状态,如下图所示

2.Spark Shell 方式
(1) 上传文件至HDFS
[liuyao@master hadoop-2.7.2]$ hdfs dfs -ls /
Found 1 items
drwx-wx-wx - liuyao supergroup 0 2016-07-16 23:33 /tmp
[liuyao@master hadoop-2.7.2]$ hdfs dfs -put README.txt /tmp/
[liuyao@master hadoop-2.7.2]$ hdfs dfs -ls /tmp/
Found 2 items
-rw-r--r-- 2 liuyao supergroup 1366 2016-07-16 23:45 /tmp/README.txt
drwx-wx-wx - liuyao supergroup 0 2016-07-16 23:33 /tmp/hive(2) 启动Spark-shell
[liuyao@master bin]$ spark-shell
16/07/16 23:33:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
……
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.2
/_/
Using Scala version 2.10.5 (OpenJDK 64-Bit Server VM, Java 1.8.0_91)
……
16/07/16 23:33:30 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
……
16/07/16 23:34:07 INFO repl.SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.(3) 交互式操作
scala> val readmeFile = sc.textFile("hdfs://master:9000/tmp/README.txt")
16/07/16 23:46:21 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 62.4 KB, free 62.4 KB)
……
readmeFile: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/tmp/README.txt MapPartitionsRDD[1] at textFile at : 27
scala> var theCount = readmeFile.filter(line=>line.contains("The"))
theCount: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at : 29
scala> theCount.count
16/07/16 23:47:19 INFO mapred.FileInputFormat: Total input paths to process : 1
……
16/07/16 23:47:21 INFO scheduler.DAGScheduler: Job 0 finished: count at :32, took 1.251228 s
res0: Long = 4
scala> val wordCount = readmeFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
wordCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[5] at reduceByKey at : 29
scala> wordCount.collect
16/07/16 23:48:49 INFO spark.SparkContext: Starting job: collect at :32
……
16/07/16 23:48:49 INFO scheduler.DAGScheduler: Job 1 finished: collect at :32, took 0.222501 s
res1: Array[(String, Int)] = Array((under,1), (this,3), (distribution,2), (Technology,1), (country,1), (is,1), (Jetty,1), (currently,1), (permitted.,1), (check,1), (have,1), (Security,1), (U.S.,1), (with,1), (BIS,1), (This,1), (mortbay.org.,1), ((ECCN),1), (using,2), (security,1), (Department,1), (export,1), (reside,1), (any,1), (algorithms.,1), (from,1), (re-export,2), (has,1), (SSL,1), (Industry,1), (Administration,1), (details,1), (provides,1), (http://hadoop.apache.org/core/,1), (country's,1), (Unrestricted,1), (740.13),1), (policies,1), (country,,1), (concerning,1), (uses,1), (Apache,1), (possession,,2), (information,2), (our,2), (as,1), ("",18), (Bureau,1), (wiki,,1), (please,2), (form,1), (information.,1), (ENC,1), (Export,2), (included,1), (asymmetric,1), (Commodity,1), (Softwar... (4) 通过Web UI 查看集群状态
Spark - Job 界面:http://master:4040/jobs/
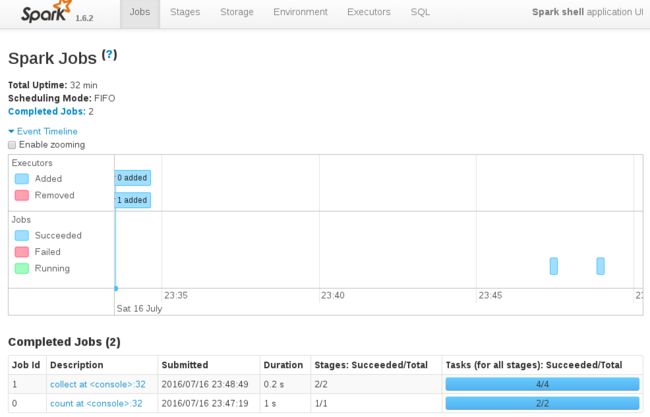
Spark - Stage 界面:http://master:4040/stages/

Spark - Master & Workers 界面:http://master:8080/
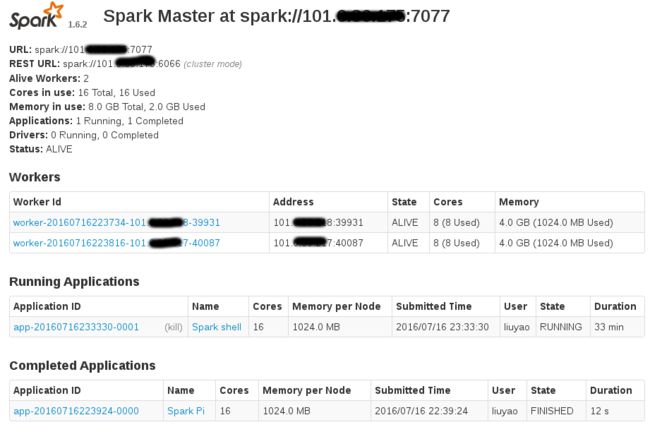
参考资料
http://www.cnblogs.com/tonylp/p/5233369.html
http://www.open-open.com/lib/view/open1419490748562.html
http://blog.csdn.net/stark_summer/article/details/42458081