Java - 并行数据处理和性能
Java - 并行数据处理和性能
- 并行流
- 配置并行流使用的线程池
- 测量流的性能
- 使用更专业的方法
- 正确使用并行流
- fork/join框架
- RecursiveTask
- 使用fork/join的最佳实践
- 偷工作
- Spliterator
- 分割过程
- Spliterator特征
- 实现自己的Spliterator
- 使用函数式实现
- 并行的实现
并行流
并行流是一个把元素分成多个块的流,每个块用不同的线程处理。可以自动分区,让所有的处理器都忙起来。
假设要写一个方法,接受一个数量n做参数,计算1-n的和。可以这样实现:
public long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.reduce(0L, Long::sum);
}
也许可以使用parallel方法,简单地使用并行计算,提高程序性能:
public long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);
}
这样,流可能在内部被分成多个块,导致reduction操作可以在不同的块上互不依赖地并行地各自工作。最后,reduction操作组合每个子流的并行reductions的返回值,返回的结果就是整个流的结果。见下面的示意图
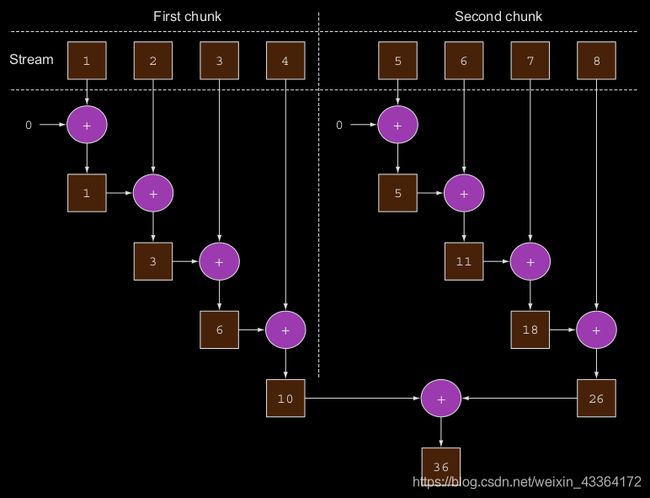
实际上,调用parallel方法,流自身不会有任何变化。在内部,设置一个布尔类型的标记,标明你想在并行模式执行操作,接下来的操作都是并行的。
类似地,你也可以使用sequential方法,把并行流转成串行的。你也许认为可以组合这两个方法:
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();
但是,最后一次调用parallel或者sequential才会全局地影响管道。上面的例子,管道将被并行地执行。
配置并行流使用的线程池
并行流内部使用ForkJoinPool。默认地,线程数量等于处理器数量(Runtime.getRuntime().availableProcessors())。但是,可以修改系统属性java.util.concurrent.ForkJoinPool.common.parallelism,配置线程数量。
这是全局配置,所以,除非你认为对性能有帮助,否则不要修改。
测量流的性能
我们声称并行加法应该比串行的或者自己的迭代方法快。我们可以使用JMH测量一下。这是一个工具,使用基于注解的方法,可以为JVM程序增加
可靠的microbenchmarks。如果使用maven,可以这样引入:
<dependency>
<groupId>org.openjdk.jmhgroupId>
<artifactId>jmh-coreartifactId>
<version>1.21version>
dependency>
<dependency>
<groupId>org.openjdk.jmhgroupId>
<artifactId>jmh-generator-annprocessartifactId>
<version>1.21version>
dependency>
第一个库是核心实现,第二个包含一个注解处理器,帮助生成JAR文件,通过它可以方便地运行你的benchmark。maven配置里还应该有下面的plugin:
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<finalName>benchmarksfinalName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.MainmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
程序代码如下
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.TearDown;
import java.util.concurrent.TimeUnit;
import java.util.stream.Stream;
//测量平均时间
@BenchmarkMode(Mode.AverageTime)
//以毫秒为单位,打印benchmark结果
@OutputTimeUnit(TimeUnit.MILLISECONDS)
//执行两次,增加可靠性。堆空间是4Gb
@Fork(value = 2, jvmArgs = {"-Xms4G", "-Xmx4G"})
@State(Scope.Benchmark)
public class ParallelStreamBenchmark {
private static final long N = 10_000_000L;
@Benchmark
public long sequentialSum() {
return Stream.iterate(1L, i -> i + 1).limit(N)
.reduce(0L, Long::sum);
}
//每次执行benchmark后,执行GC
@TearDown(Level.Invocation)
public void tearDown() {
System.gc();
}
}
使用大内存,和每次迭代以后试着GC都是为了尽量减少GC的影响。尽管如此,结果应该再加一些盐。很多因素会影响执行时间,比如你的机器有多少核。
默认地,JMH一般先执行5次热身迭代,这样可以让HotSpot优化代码,然后再执行5次迭代用来计算最终的结果。你可以使用-w和-i命令行参数修改这些配置。
在我的机器上,使用JDK 1.8.0_121, Java HotSpot™ 64-Bit Server VM,执行结果是
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.sequentialSum avgt 10 83.565 ± 1.841 ms/op
你应该期望,使用经典的for循环的迭代版本运行得更快,因为它在更低层(level)工作,而且,更重要的是,它不需要执行原始类型的装箱和拆箱操作。我们测试一下这个方法:
@Benchmark
public long iterativeSum() {
long result = 0;
for (long i = 1L; i <= N; i++) {
result += i;
}
return result;
}
执行结果是
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.iterativeSum avgt 10 6.877 ± 0.068 ms/op
证实了我们的期望:迭代版本比串行流快了10倍。让我们使用并行流试一试:
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.parallelSum avgt 10 110.157 ± 1.882 ms/op
非常令人失望:并行版本的求和一点都没有发挥多核的优势,比串行版还要慢。为什么会这样?有两个问题混在一起:
- 迭代生成了装箱对象,它们在做加法前,必须拆箱成数字
- 迭代很难划分独立的块来并行地执行
第二点是特别有趣的,不是所有的流都是适合并行处理的。特别是,迭代的流就很难,这是因为,函数的输入依赖上一个函数的结果。见下图:
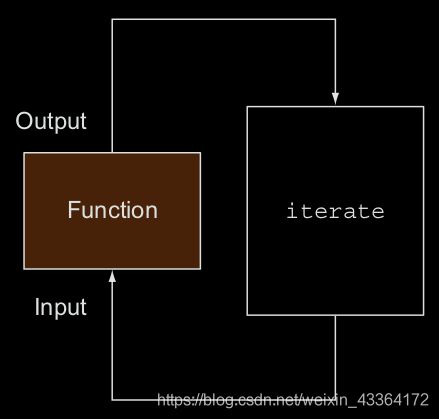
这意味着,reduction过程并没有像第一张图里所表示的那样执行。reduction开始的时候,还没有整个数字列表,所以没法分块。把流标记为并行的,反而增加了在不同线程上执行的求和要被串行处理的负担。
使用更专业的方法
LongStream.rangeClosed方法使用的是原始long类型,所以不用装箱和拆箱。而且,它生产的数的范围,可以很容易地分成不依赖的块。比如,范围1-20可以被分成1-5、6-10、11-15和16-20。
@Benchmark
public long rangedSum() {
return LongStream.rangeClosed(1, N)
.reduce(0L, Long::sum);
}
输出是
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.rangedSum avgt 10 7.660 ± 1.643 ms/op
可以看出来,比并行流快了很多,仅比经典的for循环慢了一点。LongStream支持并行:
@Benchmark
public long parallelRangedSum() {
return LongStream.rangeClosed(1, N)
.parallel()
.reduce(0L, Long::sum);
}
输出是
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.parallelRangedSum avgt 10 4.790 ± 5.142 ms/op
可以发现,并行生效了。甚至比for循环还快了1/3。
正确使用并行流
滥用并行流产生错误的主要原因是使用了改变共享状态的算法。下面是一个通过改变共享的累加器来实现前n个自然数求和的例子:
public long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).forEach(accumulator::add);
return accumulator.total;
}
public class Accumulator {
public long total = 0;
public void add(long value) {
total += value;
}
}
这种代码很常见,特别对熟悉命令式编程范式的开发者而言。当你迭代数字列表时,经常这样做:初始化一个累加器,遍历元素,使用累加器相加。
这代码有什么错?它是串行的,失去了并行性。让我们试着使用并行流:
public long sideEffectParallelSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).parallel().forEach(accumulator::add);
return accumulator.total;
}
多执行几次,你会发现,每次返回的结果都不一样,而且都不是正确的50000005000000。这是因为多线程累加的时候,total += value并不是原子操作。那么怎样才能写出并行情况下,正确的代码呢?
- 如果有怀疑,就做测试
- 注意装箱问题。Java提供的原始类型流(IntStream、LongStream和DoubleStream)可以避免类似的问题,尽量使用他们
- 有些操作使用并行流性能更差。尤其是像limit和findFirst这种依赖元素顺序的操作,使用并行是非常昂贵的。比如,findAny就比findFirst性能好,因为它跟顺序无关。调用unordered方法,可以把一个有顺序的流变成无顺序的流。比如,如果你需要流的N个元素,而你对前M个感兴趣,在一个无顺序的流上调用limit比有顺序的高效
- 如果数据量不大,不要选择并行流
- 要考虑流的底层数据结构的可分解程度。比如,ArrayList比LinkedList分解起来更高效,因为不遍历就可以分割。使用range工厂增加的原始类型流也很容易分割。可以通过实现自己的Spliterator分割流
- 流的特征,以及中间操作如何修改流的元素,会改变分解过程的性能。比如,一个SIZED流可以被分解成两个相等的部分,并且每个部分可以高效得并行处理,但是,filter会过滤掉任何不满足条件的元素,导致流的size成了未知的
- 考虑结束操作是廉价的还是昂贵的merge步骤(比如,Collector的combiner方法)。如果是昂贵的,组合并行结果的代价会比并行流带来的好处还要高
下面的表格,总结一些流在可分解性方面的并行友好性
| 源 | 可分解性 |
|---|---|
| ArrayList | 优秀 |
| LinkedList | 差 |
| IntStream.range | 优秀 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
fork/join框架
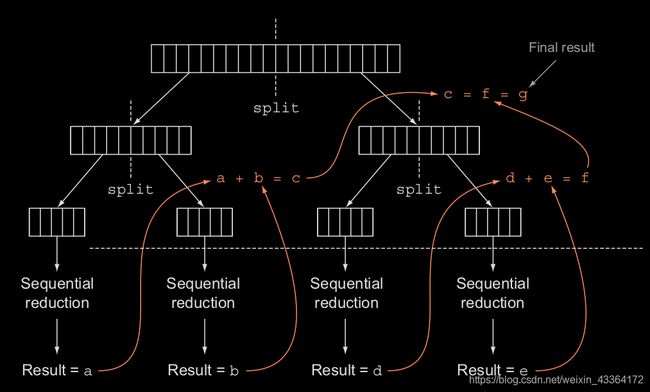
fork/join框架用来递归地把可并行的任务分解成小任务,然后组合每个子任务的结果,以生成总的结果。它实现了ExecutorService接口,这样所有的子任务都在一个线程池(ForkJoinPool)内工作。
RecursiveTask
要向ForkJoinPool提交任务,你不得不增加RecursiveTask的子类-R是并行任务(以及每个子任务)的返回类型,或者
增加RecursiveAction的子类-当没有返回值的时候。要定义RecursiveTask,需要实现它唯一的抽象方法:
protected abstract R compute();
该方法定义分割任务和不能继续被分割时处理一个子任务的算法的逻辑。该方法的实现,经常像下面的伪代码:
if (任务足够小,不再被分) {
顺序执行任务
} else {
把任务分成两个子任务
递归地调用本方法,尽量分割每个子任务
等待所有子任务的完成
组合每个子任务的结果
}
可以发现,这是分治算法的并行实现。我们继续求和的例子,演示怎么使用fork/join框架。首先需要扩展RecursiveTask类:
import java.util.concurrent.RecursiveTask;
/**
* Created by leishu on 18-12-11.
*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//分割任务的阈值
public static final long THRESHOLD = 10_000;
//要被求和的数组
private final long[] numbers;
private final int start;
private final int end;
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
//生成子任务的私有构造器
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//子任务的大小
int length = end - start;
if (length <= THRESHOLD) {
return computeSequentially();//小于阈值,不分割
}
//增加第一个子任务
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length / 2);
//异步执行,新的子任务使用ForkJoinPool的另一个线程
leftTask.fork();
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length / 2, end);
//同步执行第二个子任务,允许递归
Long rightResult = rightTask.compute();
//读取第一个子任务的结果,如果没完成就等待
Long leftResult = leftTask.join();
//组合
return leftResult + rightResult;
}
//顺序执行
private long computeSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}
然后写一个方法,执行并行求和:
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
执行一下,输出如下
Benchmark Mode Cnt Score Error Units
ParallelStreamBenchmark.forkJoinSumB avgt 4 28.458 ± 0.602 ms/op
性能不够好,这是因为在ForkJoinSumCalculator使用的是一个long[]。
使用fork/join的最佳实践
- 调用任务的join方法,会阻塞调用者,直到返回结果。所以,要在两个子任务都启动以后在调用它
- 不要在RecursiveTask内使用ForkJoinPool的invoke方法
- 子任务的fork方法是用来做调度的。在两个子任务上直接调用它似乎是很自然的,但是,在其中一个上调用compute效率更高,因为这样能重用相同的线程
偷工作
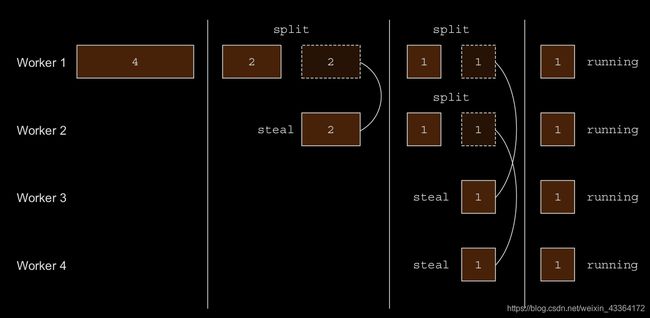
任务被分给ForkJoinPool里的线程。每个线程有一个保存任务的双端链表,顺序地执行链表中的任务。如果由于某种原因(比如I/O),一个线程完成了分配给他的全部任务,它会随机地从其他线程选择一个队列,从队列的尾部偷一个任务。这个过程会持续,直到所有的队列都空了为止。所以,要有大量的小任务,而不是几个大任务,这样可以更好地平衡线程的负荷。
Spliterator
Spliterator是Java 8 提供的新接口,意思是“splitable iterator”,用来并行地迭代源中的元素。也许你不用开发自己的Spliterator,但是,理解了它,也就明白了并行流是如何工作的。Java 8已经在Collections框架内提供了Spliterator的默认实现。Collection接口有一个default方法spliterator(),它就返回一个Spliterator对象。我们先看看Spliterator接口的定义:
public interface Spliterator<T> {
//用来按顺序消费Spliterator的元素,如果还有元素就返回true
boolean tryAdvance(Consumer<? super T> action);
//把一些元素分到一个新的Spliterator,以允许他们并行处理
Spliterator<T> trySplit();
//剩余的可被遍历的元素数量估值
long estimateSize();
int characteristics();
}
tryAdvance方法的行为类似于迭代器,用来按顺序消费Spliterator的元素,如果还有元素就返回true。trySplit方法
用来把一些元素分到一个新的Spliterator,以允许他们并行处理。
分割过程
把一个流分割成多个部分是一个递归过程,如下图所示。首先,在第一个Spliterator上调用trySplit生成一个新的。然后,在这两个Spliterator上调用trySplit,这样产生四个。一直进行下去,直到该方法返回null,标志着不能再被分割。最后,当所有的trySplit都返回null时,递归过程结束。
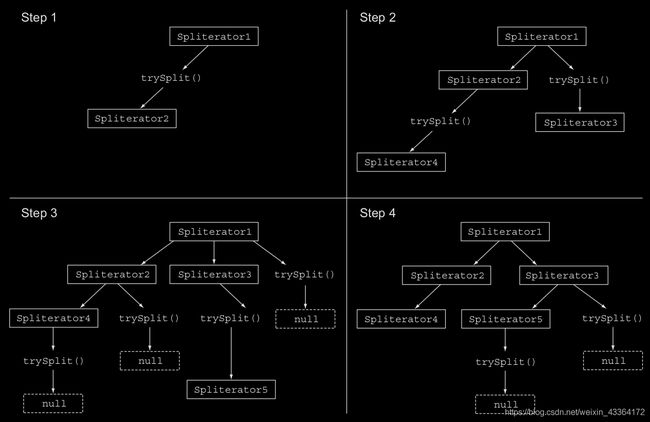
分割过程也会受到Spliterator的特征(由characteristics方法声明)的影响。
Spliterator特征
characteristics方法返回一个整数,用来更好地控制和优化Spliterator的用法。
| Characteristic | 描述 |
|---|---|
| ORDERED | 元素是有顺序的(比如List),所以Spliterator使用该顺序做遍历和分区 |
| DISTINCT | 对于每对遍历的元素x和y,x.equals(y)返回false |
| SORTED | 遍历的元素遵循预定义的排序顺序 |
| SIZED | 源的size是已知的(比如set),所以estimatedSize()返回的值是精确的 |
| NON-NULL | 元素不会为空 |
| IMMUTABLE | 源是不可变的,说明遍历的时候,元素不会被增加、修改和删除 |
| CONCURRENT | 源是并发安全的,并发修改的时候,不用任何同步 |
| SUBSIZED | Spliterator和接下来产生的Spliterator都是SIZED |
实现自己的Spliterator
我们开发一个简单的方法,用来计算字符串中的单词数。
public int countWordsIteratively(String s) {
int counter = 0;
boolean lastSpace = true;
for (char c : s.toCharArray()) {
if (Character.isWhitespace(c)) {
lastSpace = true;
} else {
if (lastSpace) counter++;
lastSpace = false;
}
}
return counter;
}
要计算的字符串是但丁的“地域”的第一句
public static final String SENTENCE =
" Nel mezzo del cammin di nostra vita "
+ "mi ritrovai in una selva oscura"
+ " che la dritta via era smarrita ";
System.out.println("Found " + countWordsIteratively(SENTENCE) + " words");
注意,两个单词间的空格数是随机的。执行结果
Found 19 words
使用函数式实现
首先需要把字符串转换成一个流。原始类型int、long和double才有原始的的流,所以,我们使用Stream:
Stream<Character> stream = IntStream.range(0, SENTENCE.length())
.mapToObj(SENTENCE::charAt);
可以使用reduction计算单词数量。当reduce的时候,你不得不携带由两个变量组成的状态:整数型的总数和布尔型的字符是否是空格。因为Java没有tuples,你得增加一个新类-WordCounter-封装状态:
class WordCounter {
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter, boolean lastSpace) {
this.counter = counter;
this.lastSpace = lastSpace;
}
//遍历,累加
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c)) {
return lastSpace ? this : new WordCounter(counter, true);
} else {
//如果上一个字符是空格,而当前的不是,就加1
return lastSpace ? new WordCounter(counter + 1, false) : this;
}
}
//组合,求和
public WordCounter combine(WordCounter wordCounter) {
return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace);
}
public int getCounter() {
return counter;
}
}
下面是遍历一个新字符时,WordCounter的状态图
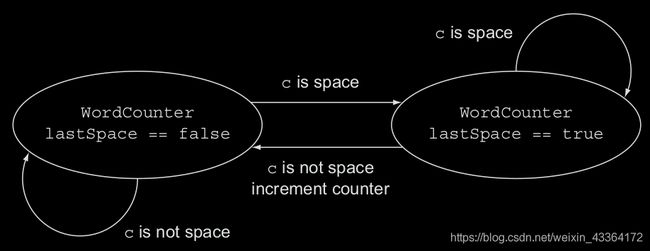
然后,我们就可以使用流的reduce方法了
private int countWords(Stream<Character> stream) {
WordCounter wordCounter = stream.reduce(new WordCounter(0, true),
WordCounter::accumulate,
WordCounter::combine);
return wordCounter.getCounter();
}
我们做一下测试
Stream<Character> stream = IntStream.range(0, SENTENCE.length())
.mapToObj(SENTENCE::charAt);
System.out.println("Found " + countWords(stream) + " words");
执行结果是正确的。
并行的实现
我们修改一下代码
System.out.println("Found " + countWords(stream.parallel()) + " words");
执行结果不是找到19个单词了。因为源字符串在随意的位置被分割,一个字符被多次分割。要解决这个问题,就需要实现自己的Spliterator。
class WordCounterSpliterator implements Spliterator<Character> {
private final String string;
private int currentChar = 0;
private WordCounterSpliterator(String string) {
this.string = string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
//消费当前字符
action.accept(string.charAt(currentChar++));
//如果还有字符可被消费,返回true
return currentChar < string.length();
}
@Override
public Spliterator<Character> trySplit() {
int currentSize = string.length() - currentChar;
//小于阈值,不再分割
if (currentSize < 10) {
return null;
}
//候选的分割位置是字符串的一半长度
for (int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++) {
//如果是空格,才分割
if (Character.isWhitespace(string.charAt(splitPos))) {
Spliterator<Character> spliterator = new WordCounterSpliterator(string.substring(currentChar, splitPos));
//当前位置修改为分割位置
currentChar = splitPos;
return spliterator;
}
}
return null;
}
@Override
public long estimateSize() {
return string.length() - currentChar;
}
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}
然后,我们做测试
Spliterator<Character> spliterator = new WordCounterSpliterator(SENTENCE);
Stream<Character> stream = StreamSupport.stream(spliterator, true);
System.out.println("Found " + countWords(stream) + " words");
这回没问题了。