计算高斯混合模型的可分性和重叠度(Overlap Rate, OLR)
文章目录
- 简介
- OLR计算
- 算法实现
简介
本文章实现了Haojun Sun提出的一种计算高斯混合模型(GMM)重叠率的方法(论文:Measuring the component overlapping in the Gaussian mixture model)。这篇文论提出的方法可以计算任意两个混合高斯分布之间的重叠度。该方法可以用来评价GMM模型的好坏,我在我的论文中使用了这个算法,用来评价高斯混合模型聚类的可分性。
关于高斯混合模型(GMM)的相关概念可以参考另一篇博文:高斯混合模型及其EM算法的理解
使用GMM聚类或分析两个高斯混合分布的数据时,我们有时会希望两个高斯分布离得越远越好,这样表示数据才有可分性。但很多情况下两个高斯分布会有重叠。一维和二维的重叠情况如下所示(图片取自作者论文)。
我们可以计算一些指标来间接反映两个高斯分布的重叠情况。比如可以计算Mahalanobis距离,Bhattacharyya距离或Kullback-Leibler (KL)距离,可以衡量两个高斯分布的相似性。但是Mahalanobis距离预设两个分布具有相同的协方差,Bhattacharyya距离和KL距离都考虑了协方差,但却没有考虑高斯混合分布的混合系数(mixing coefficient)。而且KL距离对高维的正态分布没有解析解,计算复杂。
这篇论文提出的计算OLR的方法考虑了高斯混合分布中的所有参数,包括均值,协方差和混合系数。
OLR计算
假设有 n n n个 d d d维的样本 X = { X 1 , . . . , X n } \boldsymbol{X} = \{X_1,..., X_n\} X={X1,...,Xn}. 其中 X i X_i Xi是一个 d d d维向量。一个混合高斯模型的pdf可以表示为:
p ( X ) = ∑ i = 1 k α i G i ( X , μ i , Σ i ) (1) p(X) = \sum_{i=1}^k \alpha_iG_i(X, \mu_i, \Sigma_i) \tag{1} p(X)=i=1∑kαiGi(X,μi,Σi)(1)
其中 α i \alpha_i αi是混合系数,满足 α i > 0 \alpha_i > 0 αi>0且 ∑ i = 1 k α i = 1 \sum_{i=1}^k\alpha_i=1 ∑i=1kαi=1.
G i ( X ) G_i(X) Gi(X)是一个 d d d维高斯分布,可以表示为下面的形式:
G i ( X ) = 1 ( 2 π ) d / 2 ∣ Σ i ∣ 1 / 2 exp ( 1 2 ( X − μ i ) T Σ i − 1 ( X − μ i ) ) (2) G_i(X) = \frac{1}{(2\pi)^{d/2} |\Sigma_i|^{1/2}} \exp \left( \frac{1}{2} (X-\mu_i)^T \Sigma_i^{-1}(X-\mu_i)\right) \tag{2} Gi(X)=(2π)d/2∣Σi∣1/21exp(21(X−μi)TΣi−1(X−μi))(2)
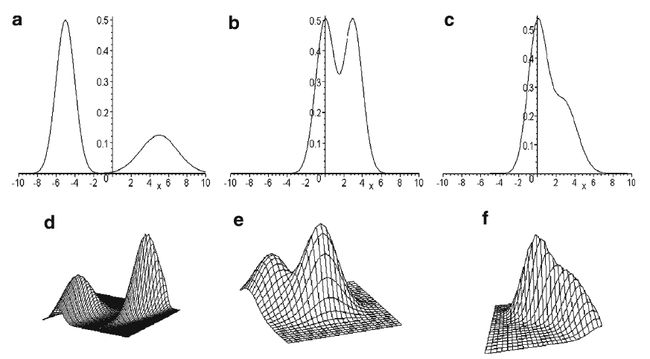
以二维高斯分布为例。当两个高斯分布有重叠时,会形成鞍状。如上图的d和e,二维高斯分布混合时会出现两个峰和一个鞍部;当两个分布几乎完全混合时,鞍部可能消失,但峰还在,此时明显的峰只有一个,如上图中的f。
论文中的两个高斯分布的OLR定义如下:
O L R ( G 1 , G 2 ) = { 1 if p ( X ) has one peak p ( X s a d d l e ) p ( X s u b m a x ) if p ( X ) has two peaks (3) OLR(G_1, G_2) = \begin{cases} 1 &\text{if $p(X)$ has one peak} \\ \frac{p(X_{saddle})}{p(X_{submax})} &\text{if $p(X)$ has two peaks} \end{cases} \tag{3} OLR(G1,G2)={1p(Xsubmax)p(Xsaddle)if p(X) has one peakif p(X) has two peaks(3)
其中 X s a d d l e X_{saddle} Xsaddle是pdf中的鞍点(saddle point), X s u b m a x X_{submax} Xsubmax是pdf中的较低的峰(lower peak point)。OLR的示意图如下图所示。OLR计算的是鞍点的pdf与较低峰的pdf的比值。这么做是因为鞍点的pdf与混合系数 α i \alpha_i αi有关。注意到OLR并不是落在重叠区域内数据的比例,因此跟数据量无关,只跟数据的分布有关。定义中的 p ( X s u b m a x ) p(X_{submax}) p(Xsubmax)容易求,只需将两个均值带入(1)式,取较小的值即可。但是 p ( X s a d d l e ) p(X_{saddle}) p(Xsaddle)不容直接求得。下面介绍如何计算 p ( X s a d d l e ) p(X_{saddle}) p(Xsaddle)。

注意到两个峰点和鞍点在整个曲面上都应该是极值点。因此 X s a d d l e X_{saddle} Xsaddle和 X s u b m a x X_{submax} Xsubmax应该满足下式:
{ ∂ p ∂ x 1 = A x 1 α 1 G 1 + B x 1 α 2 G 2 ∂ p ∂ x 2 = A x 2 α 1 G 1 + B x 2 α 2 G 2 (4) \begin{cases} \frac{\partial p}{\partial x_1} = A_{x_1}\alpha_1G_1 + B_{x_1}\alpha_2 G_2 \\ \frac{\partial p}{\partial x_2} = A_{x_2}\alpha_1G_1 + B_{x_2}\alpha_2 G_2 \end{cases} \tag{4} {∂x1∂p=Ax1α1G1+Bx1α2G2∂x2∂p=Ax2α1G1+Bx2α2G2(4)
其中,
( A x 1 A x 2 ) = ∇ ∣ ∣ X − μ 1 ∣ ∣ Σ 1 − 1 2 = − Σ 1 − 1 ( X − μ 1 ) ( B x 1 B x 2 ) = ∇ ∣ ∣ X − μ 2 ∣ ∣ Σ 1 − 1 2 = − Σ 1 − 1 ( X − μ 2 ) (5) \begin{aligned} \left( \begin{matrix} A_{x_1} \\ A_{x_2} \end{matrix} \right) = \nabla ||X-\mu_1||_{\Sigma_1^{-1}}^2 = -\Sigma_1^{-1}(X - \mu_1) \\ \left( \begin{matrix} B_{x_1} \\ B_{x_2} \end{matrix} \right) = \nabla ||X-\mu_2||_{\Sigma_1^{-1}}^2 = -\Sigma_1^{-1}(X - \mu_2) \end{aligned} \tag{5} (Ax1Ax2)=∇∣∣X−μ1∣∣Σ1−12=−Σ1−1(X−μ1)(Bx1Bx2)=∇∣∣X−μ2∣∣Σ1−12=−Σ1−1(X−μ2)(5)
(4)式式一条曲线。如果 X X X已知,(5)式可求出。论文接下来证明,峰点和鞍点会在同一条曲线上,曲线方程如下:
A x 1 B x 2 − B x 1 A x 2 = 0 (6) A_{x_1} B_{x_2} - B_{x_1} A_{x_2} = 0 \tag{6} Ax1Bx2−Bx1Ax2=0(6)
而且,鞍点会在以两个峰点(均值处的pdf)之间的曲线段上。因此只要从第一个均值开始,沿着曲线(4)一直找到另一个均值,这个过程中的极小值点就是鞍点。得到鞍点的坐标,带入(1)式,就可以求得鞍点的pdf值。(6)式中的曲线称为Ridge Curve (RC).
OLR的算法如下:
- 输入混合高斯分布的参数 ( μ 1 , μ 2 , Σ 1 , Σ 2 , α 1 , α 2 ) (\mu_1, \mu_2, \Sigma_1, \Sigma_2, \alpha_1, \alpha_2) (μ1,μ2,Σ1,Σ2,α1,α2)
- 计算RC: A x 1 B x 2 − B x 1 A x 2 = 0 A_{x_1} B_{x_2} - B_{x_1} A_{x_2} = 0 Ax1Bx2−Bx1Ax2=0
- 沿着RC,从 μ 1 \mu_1 μ1到 μ 2 \mu_2 μ2按步长 δ \delta δ找到RC中 p ( X ) p(X) p(X)取得最大值和最小值的点
3.1 令 X 0 = μ 1 X_0 = \mu_1 X0=μ1, X 0 X_0 X0的下一个点 X i + 1 X_{i+1} Xi+1的第一维(x坐标) X i + 1 1 = { X i + δ ( μ 1 − μ 2 ) } 1 X_{i+1}^1 = \{X_i + \delta(\mu_1-\mu_2)\}^1 Xi+11={Xi+δ(μ1−μ2)}1.
3.2 将 X i + 1 1 X_{i+1}^1 Xi+11带入RC方程(6),求得 X i + 1 X_{i+1} Xi+1的第二维(y坐标) X i + 1 2 X_{i+1}^2 Xi+12
3.3 根据(1)式计算 p ( X i ) p(X_i) p(Xi)
3.4 if p ( X i ) − p ( X i − 1 ) > 0 p(X_i) - p(X_{i-1}) > 0 p(Xi)−p(Xi−1)>0 and p ( X i ) − p ( X i + 1 ) > 0 p(X_i) - p(X_{i+1}) > 0 p(Xi)−p(Xi+1)>0, X i X_i Xi is maximum point (peak)
3.5 if p ( X i ) − p ( X i − 1 ) < 0 p(X_i) - p(X_{i-1}) < 0 p(Xi)−p(Xi−1)<0 and p ( X i ) − p ( X i + 1 ) < 0 p(X_i) - p(X_{i+1}) < 0 p(Xi)−p(Xi+1)<0, X i X_i Xi is minimum point - 根据(3)式计算OLR
上述算法 δ \delta δ可以取 δ = ∣ ∣ μ 1 − μ 2 ∣ ∣ / 1000 \delta = ||\mu_1 - \mu_2|| / 1000 δ=∣∣μ1−μ2∣∣/1000. 作者认为当OLR小于0.6时,两个类别可分性良好(visually well separated),当OLR大于0.8时,两个类别严重重叠(strongly overlapping)。
如果是有多个类别的情况,可以计算所有任意两个类别的重叠度,最后对所有重叠度求均值作为整体的重叠度。
算法实现
求 p ( X i ) p(X_i) p(Xi)可以用python第三方统计包scipy.stats中的multivariate_normal计算。输入两个高斯分布的参数可以求出pdf值。
完整代码可以参考GMM Overlap Rate。论文中给出的算法有一些问题。
import math
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import inv
from scipy.stats import multivariate_normal
class BiGauss(object):
"""docstring for BiGauss"""
def __init__(self, mu1, mu2, Sigma1, Sigma2, pi1, pi2, steps = 100):
super(BiGauss, self).__init__()
self.mu1 = mu1
self.mu2 = mu2
self.Sigma1 = Sigma1
self.Sigma2 = Sigma2
self.pi1 = pi1
self.pi2 = pi2
self.biGauss1 = multivariate_normal(mean = self.mu1, cov = self.Sigma1, allow_singular = True)
self.biGauss2 = multivariate_normal(mean = self.mu2, cov = self.Sigma2, allow_singular = True)
self.steps = steps
self.inv_Sig1 = -inv(self.Sigma1)
self.inv_Sig2 = -inv(self.Sigma2)
# variables to calculate RC
self.A_1 = self.inv_Sig1[0][0]
self.B_1 = self.inv_Sig1[0][1]
self.C_1 = self.inv_Sig1[1][0]
self.D_1 = self.inv_Sig1[1][1]
self.A_2 = self.inv_Sig2[0][0]
self.B_2 = self.inv_Sig2[0][1]
self.C_2 = self.inv_Sig2[1][0]
self.D_2 = self.inv_Sig2[1][1]
计算pdf
def pdf(self, x):
return self.pi1 * self.biGauss1.pdf(x) + self.pi2 * self.biGauss2.pdf(x)
根据 x x x求出 y y y,使得 ( x , y ) (x,y) (x,y)在RC上
def RC(self, x):
E = self.A_1 * (x - self.mu1[0])
F = self.C_1 * (x - self.mu1[0])
G = self.A_2 * (x - self.mu2[0])
H = self.C_2 * (x - self.mu2[0])
I = E * self.D_2 - F * self.B_2
J = H * self.B_1 - G * self.D_1
K = self.B_1 * self.D_2 - self.B_2 * self.D_1
M = F * G - E * H
P = K
Q = I + J - K * (self.mu2[1] + self.mu1[1])
S = -(M + I * self.mu2[1] + J * self.mu1[1])
if Q**2 - 4*P*S < 0:
return None
y = max((-Q + math.sqrt(Q**2 - 4*P*S)) / (2*P), (-Q - math.sqrt(Q**2 - 4*P*S)) / (2*P))
return y
求OLR
def OLR(self):
e = math.sqrt((self.mu1[0] - self.mu2[0])**2 + (self.mu1[1] - self.mu2[1])**2) / float(self.steps)
x_step = e*(self.mu1[0]-self.mu2[0]) # each step for x
y_step = e*(self.mu1[1]-self.mu2[1]) # each step for y
p_x = self.mu1[0] - x_step
while self.RC(p_x) == None:
p_x = p_x - x_step
p_y = self.RC(p_x)
p = [p_x, p_y]
p_pre = self.mu1
p_min = min(self.pdf(p), self.pdf(p_pre))
p_max = max(self.pdf(p), self.pdf(p_pre))
index = 0
while index < self.steps:
if self.RC(p[0] - x_step) != None:
p_next = [p[0] - x_step, self.RC(p[0] - x_step)] # next point on ridge curve
if self.pdf(p) > self.pdf(p_pre) and self.pdf(p) > self.pdf(p_next):
p_max = self.pdf(p)
if self.pdf(p) < self.pdf(p_pre) and self.pdf(p) < self.pdf(p_next):
p_min = self.pdf(p)
p_pre = p
p = p_next
index += 1
pdf_mu1 = self.pdf(self.mu1)
pdf_mu2 = self.pdf(self.mu2)
return p_min / min(pdf_mu1, pdf_mu2) if p_min < min(pdf_mu1, pdf_mu2) else 1.0
上述代码有时会计算出OLR大于1的情况,还没有分析原因,因为草稿丢了,不知道代码中的A~S变量代表什么意思……因此代码中做了限制,如果求出的OLR大于1,那么只会返回1.
论文中探讨了混合系数、均值间距离和协方差对OLR的影响。论文中给出了一个例子,如下。当 α 1 = 0.46 \alpha_1 = 0.46 α1=0.46时该例子可以取到最小的OLR r m i n r_{min} rmin. 论文没有给出 r m i n r_{min} rmin的具体数值,但是给出了OLR随 α 1 \alpha_1 α1取值变化的曲线图。上述代码算出来的结果是 r m i n = 0.660 r_{min} = 0.660 rmin=0.660,也确实在 α 1 = 0.46 \alpha_1 = 0.46 α1=0.46处取得。与曲线图中的位置吻合。论文中提到当 α 1 = 0.3 \alpha_1 = 0.3 α1=0.3时,ORL等于0.7288,上述代码给出的结果是0.7270.
示例代码中也画出了OLR随 α 1 \alpha_1 α1变化的曲线图和OLR随两个均值之间距离变化的曲线图。曲线走势与论文中的图示一致,但具体数值有些差别。
这个示例代码只能计算二维混合高斯模型,更高维的无法计算,但是理论上,这个算法是适用于任何维度的GMM的。