MapR设计分析
一、简介
MapR
的设计初衷是提供99.999%高可用性的Hadoop解决方案,其中包括支持滚动升级,自我修复和自动故障转移。
MapR
无 NameNode的HA架构避免了系统内部的单点故障,并且确保集群可以没有瓶颈的扩展。JobTracker的HA功能使得JobTracker故障不 必等待JobTracker的重启才能执行MapReduce任务,而且还能保证正在运行的Job继续执行,而不需要重新提交Job。
目前社区版本中的Hadoop都存在单点故障,虽然社区有各种各样的解决方案,比如主从架构、Federation架构等,都难以避免类似的问题。
MapR将元数据分散存储于众多节点,同时元数据也是冗余存储于多个不同的节点,那么即使节点失效,也不会导致集群的不可用,数据和元数据都能快速的恢复到配置的备份数量,数据丢失的风险也是微乎其微。
1、NameNode HA
在整体架构上MapR与社区Hadoop的对比:

上图中Active-Standby模式是当下主流的HA方案,并不能完全解决Hadoop的单点问题,Standby节点替换Active的时间间隔可能较长,即使控制在分钟以内,对于处理在线业务也可能是不能容忍的。
MapR 的设计图中很明显的看出,MetaData是分散存储于所有节点,比如A所存储的元数据,分散存储在第一列的三个节点上,这个是将冗余份数设置为3份的情 况。分散存储的好处在于当有节点不可服务的时候,比如某个节点的宕机,存储了元数据备份的另外两个节点可以继续提供服务。元数据以及块的恢复由调度节点控 制。
2、JobTracker HA
MapR的 JobTracker HA改善了JT的恢复时间,并且提供了有自我修复功能的JobTracker集群。在JobTracker失败时,MapR会在其他的节点自动启动一个 JobTracker,TaskTracker自动暂停,然后重现连接到新的JobTracker节点,当前所有正在运行的作业或者任务继续运行而不会失 败或者丢失。
在整体架构上MapR与社区Hadoop的对比:

Hadoop开源发行版,JobTracker只运行在 一个单独的节点(暂不考虑Yarn的解决方案),JobTracker单点故障影响整个集群,如果JobTracker失败,所有正在运行的作业都会失 败,并且是不可恢复的,只能重新提交作业,而且JobTracker失败以后,管理员必须去检测到JobTracker失败了,然后去重新启动 JobTracker。
MapR中JobTracker失败,自动启动一个新的JobTracker,TaskTracker重新连接到新的JobTracker,所有任务和作业继续执行。
二、MapR与Federation对比
1、Federation机制:
为 了水平扩展命名服务的规模,federation 使用多个Namenode和命名空间代替过去的单个Namenode的模式。多个Namenode被联合在一起提供服务,但是每个Namenode又是独 立的,且每个Namenode不需要与其他Namenode协调工作。而Datenode的存储方式还是和过去一样使用块来存储,但每个Datenode 需要注册到集群中所有的Namenode上。Datanode周期性的发布心跳、块操作的报告和从Namenode发送来的操作命令的响应。
2、分布式Namenode:
当前支持分布式NameNode机制的有MapR Hadoop,可动态扩展NameNode数量,支持上万DataNode节点,1万亿文件数量等。
|
Federation NameNode
|
Distributed NameNode
|
|
|
NameNode
扩展性
|
通过增加在集群中的
namenode
数量来扩展
namespace
有利于大量的调度任务或者调度大量的小文件,
namenode
可以水平扩展
|
增加集群中的namenode
水平扩展集群,同样有利于大量的调度任务或者调度大量的小文件
|
|
性能
|
为集群增加
namenode
增加了文件系统的读写操作的吞吐量。
Namenode
支持的并发及吞吐量理论上随着
namenode
数量的增加呈线性增长。
|
为集群增加
namenode
增加了文件系统的读写操作的吞吐量。
Namenode
支持的并发及吞吐量理论上随着
namenode
数量的增加呈线性增长。
|
|
Namespace
|
独立。Federation namenode
采用多namespace
的结构,每个namenode
(或者每一组active-standby
)是独立的命名空间,每个namespace
对应一个块池,共享DataNode
|
非独立。
采用统一命名空间
|
|
隔离性
|
由于Federation namenode
中每一个namespace
是独立的,那么可以很好的做到不同namespace
之间的数据隔离。不同用户,甚至不同应用可以完全数据隔离
|
采用统一命名空间,无法通过namespace
做到数据隔离
|
|
NameNode
故障在namenode
集群中的影响
|
单个Namespace
下的namenode
发生故障不会对其他namespace
的服务产生影响
|
Namenode
故障不会对整个集群造成影响
|
|
单个Namespace
下NameNode
单点问题
|
对于单个Namespace
中namenode
故障会影响此Namespace
的对外服务,即使使用NameNode HA
技术也无法保证完全高可用。如果应用仅使用单个Namespace
服务, NameNode
单点问题导致其管理的文件不可访问,同样会导致应用中断。
|
可以做到完全高可用
|
|
负载均衡
|
在负载均衡上,Federation
更多的需要人工介入去控制多个Namespace
之间的均衡
|
自动均衡
|
|
扩展对Client
造成的影响
|
对于Client
使用多Namespace
的应用,在NameNode
进行扩展的时候,相应的应用也必须跟随NameNode
的扩展而发生改动,在使用上比较繁琐,至于会不会中断应用,需要看应用本身部署方案是不是高可用的
|
扩展NameNode
数量从理论上来讲不会对Client
端的应用造成影响,只需底层扩展,不需要修改Client
应用
|
|
业界方案
|
已在当前开源版本中提供Federation NameNode
扩展功能
|
MapR Hadoop
,未开源
|
|
使用
|
FaceBook
、雅虎等(Federation
由雅虎提供)
|
MapR
公司,商用,宣称支持1
万亿级文件量
|
|
适用场景
|
更多的适用于不同应用数据隔离,不同用户的数据隔离等场景,单应用使用须由客户端控制写入的Namespace
,根据services
名区分。单namespace
(32G
)大概支持1.2
亿文件量,非确定数据。
|
不做数据隔离,适合于海量文件存储等。
|
三、MapR设计实现

MapR整体结构中除去客户端、Zookeepr集群以外,主要有两种角色,分别是cldb和fileserver,其中的进程分别为CLDB进程和WardenMain进程。
2
、MapR中各组件介绍:
Container:MapR 中Container相当于HDFS中的NameNode,是元数据的最小分块,它维护集群中的一部分元数据,与NameNode不同之处在 于,Container不仅维护File MetaData,还维护Block映射。其中不同类型的Container的作用也是不相同的。一个FileServer可能有许许多多的 Container。
CLDB:Container Location DataBase。CLDB进程保存了由FileServer汇报上来的Container到节点node地址的映射,以及每个Container的 Summary信息,比如该Container所维护的文件数量、文件总大小等信息。CLDB的高可用是主从实现的,CLDB并非是完全高可用,失效时需 要由Slave CLDB代替Master CLDB继续工作,由于客户端缓存的问题,在客户端已初始化完成的情况,CLDB的短暂切换不会影响到整个集群的可用性,当然此时新创建客户端是会失败 的。MapR中引入了Volume的概念,RootDir(“/”)为默认的Volume,可以在RootDir甚至是RootDir下面不同层级的目录 下创建Volume,每一个Container必然是属于其中的一个Volume。CLDB中还维护了Volume到Container的映射信 息,Volume到Container的映射信息不是Volume到这个Volume下所有Container的信息,而是存在一个Volume到 Root Container(Container类型为S)的映射信息。

FileServer:FileServer启动加载元数据信息,一个FileServer存有很多不 同的Container,每一个Container有全局唯一的编号,为全局自增的ID,加载元数据是分别加载每一个Container保存的元数据。 FileServer负责将所有Container Summary信息汇报给CLDB,FileServer维护了ContainerID到磁盘的映射关系,从实现上来分析,一个Container对应一 块磁盘,(而不会是一个Container对应多个磁盘),一个磁盘可以由多个Container,这样实现的好处在于,文件的真实数据随整个 Container的移动而移动,单个Container移动的时候不会影响其他磁盘,初步分析。FileServer包含的Container有两种类 型,分别是Super和Common,Super类型的Container维护该Volume下面的所有元数据信息,同时维护文件大小小于64K的块信 息,Common Container维护文件大小大于64K的文件的块信息,在设计上一个文件的多个块的元数据信息必然不会由同一个Container维护。

3
、元数据和Block的组织方式
Container 是MapR中存储元数据的最小组件,分有两种类型,分别是S和C,两种类型的Container的功能不相同。S类型的Container包含了当前 Volume下所有文件元数据信息,这个元数据信息和NameNode中的元数据类似,包含目录树相关的信息和文件Block到Container的映射 信息,与NameNode不同之处在于,S类型的Container同时还保存文件大小小于64K的文件的Block详细信息,这个详细信息包含这个 Block到磁盘中数据的映射。C类型的Container保存的信息文件大小大于64K的文件的Block详细信息。
64K作为将Block详细信息保存在不同类型Container的映射中是有一定意义的,对于小于64K的文件,客户端直接与根据Volume映射找出的FileServer通信,返回文件的数据,比HDFS中通信次数少,而对于大于64K的文件,则需要多次通信。
MapR 与HDFS在元数据和Block的组织方式的区别在于,MapR将NameNode与DataNode基本上融合在了一起作为一个服务进程,减少了 DataNode向NameNode汇报Block的信息量,同时MapR将元数据Container分散于所有节点,增加Volume也可以增加类似于 NameNode的S类型Container,具备强大的横向扩展能力。

4
、客户端访问
1
、read
读取一个文件有如下过程:
a、 从CLDB拉取到Volume和S Container的映射信息和Container到节点的映射信息;
b、 根据文件路径找到对应的Volume;
c、 根据Volume找到S Container及其对应node;
d、 根据node信息与FileServer通信,取回文件元数据或者文件内容;
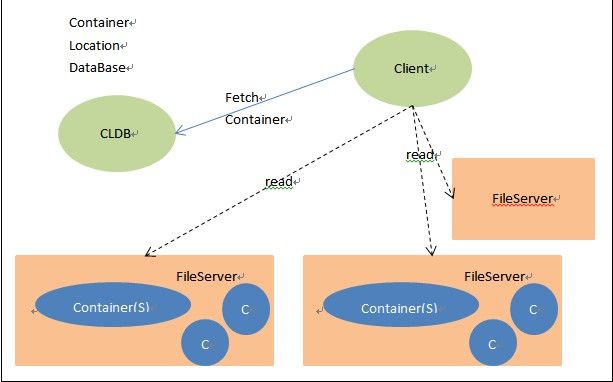
Client 在第一获取到Container Location信息和Volume Map信息后,会将这些信息缓存在客户端,后续的读取操作Fetch Container不需要从CLDB获取这些信息,Client与FileServer通信后,同时也会将该文件的元数据信息缓存在客户端,Client 第二次读取该文件的时候不要重新获取元数据信息,Client与FileServer的通信也会将与该文件相同目录下的文件元数据缓存在客户 端,Client读取该目录下文件相当于对同一个文件进行二次读。
2
、write
写入一个文件有如下过程:
a、 从CLDB拉取到Volume和S Container的映射信息和Container到节点的映射信息;
b、 根据文件路径找到对应的Volume;
c、 根据Volume找到S Container及其对应node;
d、 根据node信息与FileServer通信,请求分配Block,如果是小于64K的文件,即客户端一次发送即可完成文件写入,Block信息存 入S Container中;如果文件大小大于64K,则有FileServer分配块到C Container中,S Container保存了Block到CContainer的映射;
e、 Client将数据写入到FileServer中;

Client 在第一获取到Container Location信息和Volume Map信息后,会将这些信息缓存在客户端,后续的读取操作Fetch Container不需要从CLDB获取这些信息,Client与其中一个FileServer通信有FileServer在S Container中创建元数据并分配Block,包含这个Block存储的Container,这个Container可能是S类型的,可能是C类型 的,根据文件大小区分。
MapR
的互为冗余的多个Container都是可写的,那么用户写的时候就有可能操作两个或者多个Container,这里就涉及到处理分布式事务的问题。