-- 作者:阿哲
-- 发布时间:2007-7-27 13:32:52
--
petshop4.0 详解之四(PetShop之ASP.NET缓存) 如 果对微型计算机硬件系统有足够的了解,那么我们对于Cache这个名词一定是耳熟能详的。在CPU以及主板的芯片中,都引入了这种名为高速缓冲存储器 (Cache)的技术。因为Cache的存取速度比内存快,因而引入Cache能够有效的解决CPU与内存之间的速度不匹配问题。硬件系统可以利用 Cache存储CPU访问概率高的那些数据,当CPU需要访问这些数据时,可以直接从Cache中读取,而不必访问存取速度相对较慢的内存,从而提高了 CPU的工作效率。软件设计借鉴了硬件设计中引入缓存的机制以改善整个系统的性能,尤其是对于一个数据库驱动的Web应用程序而言,缓存的利用是不可或缺 的,毕竟,数据库查询可能是整个Web站点中调用最频繁但同时又是执行最缓慢的操作之一,我们不能被它老迈的双腿拖缓我们前进的征程。缓存机制正是解决这 一缺陷的加速器。 4.1 ASP.NET缓存概述 作为.Net框架下开发Web应用程序的主打产品, ASP.NET充分考虑了缓存机制。通过某种方法,将系统需要的数据对象、Web页面存储在内存中,使得Web站点在需要获取这些数据时,不需要经过繁琐 的数据库连接、查询和复杂的逻辑运算,就可以“触手可及”,如“探囊取物”般容易而快速,从而提高整个Web系统的性能。 ASP.NET提供了两种基本的缓存机制来提供缓存功能。一种是应用程序缓存,它允许开发者将程序生成的数据或报表业务对象放入缓存中。另外一种缓存机制是页输出缓存,利用它,可以直接获取存放在缓存中的页面,而不需要经过繁杂的对该页面的再次处理。 应用程序缓存其实现原理说来平淡无奇,仅仅是通过ASP.NET管理内存中的缓存空间。放入缓存中的应用程序数据对象,以键/值对的方式存储,这便于用户在访问缓存中的数据项时,可以根据key值判断该项是否存在缓存中。 放 入在缓存中的数据对象其生命周期是受到限制的,即使在整个应用程序的生命周期里,也不能保证该数据对象一直有效。ASP.NET可以对应用程序缓存进行管 理,例如当数据项无效、过期或内存不足时移除它们。此外,调用者还可以通过CacheItemRemovedCallback委托,定义回调方法使得数据 项被移除时能够通知用户。 在.Net Framework中,应用程序缓存通过System.Web.Caching.Cache类实现。它是一个密封类,不能被继承。对于每一个应用程序域, 都要创建一个Cache类的实例,其生命周期与应用程序域的生命周期保持一致。我们可以利用Add或Insert方法,将数据项添加到应用程序缓存中,如 下所示:
Cache["First"] = "First Item";
Cache.Insert("Second", "Second Item"); 我们还可以为应用程序缓存添加依赖项,使得依赖项发生更改时,该数据项能够从缓存中移除:
string[] dependencies = {"Second"};
Cache.Insert("Third", "Third Item",
new System.Web.Caching.CacheDependency(null, dependencies)); 与之对应的是缓存中数据项的移除。前面提到ASP.NET可以自动管理缓存中项的移除,但我们也可以通过代码编写的方式显式的移除相关的数据项:
Cache.Remove("First"); 相 对于应用程序缓存而言,页输出缓存的应用更为广泛。它可以通过内存将处理后的ASP.NET页面存储起来,当客户端再一次访问该页面时,可以省去页面处理 的过程,从而提高页面访问的性能,以及Web服务器的吞吐量。例如,在一个电子商务网站里,用户需要经常查询商品信息,这个过程会涉及到数据库访问以及搜 索条件的匹配,在数据量较大的情况下,如此的搜索过程是较为耗时的。此时,利用页输出缓存就可以将第一次搜索得到的查询结果页存储在缓存中。当用户第二次 查询时,就可以省去数据查询的过程,减少页面的响应时间。 页输出缓存分为整页缓存和部分页缓存。我们可以通过@OutputCache指令 完成对Web页面的输出缓存。它主要包含两个参数:Duration和VaryByParam。Duration参数用于设置页面或控件进行缓存的时间, 其单位为秒。如下的设置表示缓存在60秒内有效:
<%@ OutputCache Duration=“60“ VaryByParam=“none“ %> 只要没有超过Duration设置的期限值,当用户访问相同的页面或控件时,就可以直接在缓存中获取。
使用VaryByParam参数可以根据设置的参数值建立不同的缓存。例如在一个输出天气预报结果的页面中,如果需要为一个ID为txtCity的TextBox控件建立缓存,其值将显示某城市的气温,那么我们可以进行如下的设置:
<%@ OutputCache Duration=”60” VaryByParam=”txtCity” %> 如此一来,ASP.NET会对txtCity控件的值进行判断,只有输入的值与缓存值相同,才从缓存中取出相应的值。这就有效地避免了因为值的不同而导致输出错误的数据。 利用缓存的机制对性能的提升非常明显。通过ACT(Application Center Test)的测试,可以发现设置缓存后执行的性能比未设置缓存时的性能足足提高三倍多。 引 入缓存看来是提高性能的“完美”解决方案,然而“金无足赤,人无完人”,缓存机制也有缺点,那就是数据过期的问题。一旦应用程序数据或者页面结果值发生的 改变,那么在缓存有效期范围内,你所获得的结果将是过期的、不准确的数据。我们可以想一想股票系统利用缓存所带来的灾难,当你利用错误过期的数据去分析股 市的风云变幻时,你会发现获得的结果真可以说是“失之毫厘,谬以千里”,看似大好的局面就会像美丽的泡沫一样,用针一戳,转眼就消失得无影无踪。 那 么我们是否应该为了追求高性能,而不顾所谓“数据过期”所带来的隐患呢?显然,在类似于股票系统这种数据更新频繁的特定场景下,数据过期的糟糕表现甚至比 低效的性能更让人难以接受。故而,我们需要在性能与数据正确性间作出权衡。所幸的是,.Net Framework 2.0引入了一种新的缓存机制,它为我们的“鱼与熊掌兼得”带来了技术上的可行性。 .Net 2.0引入的自定义缓存依赖项,特别是基于MS-SQL Server的SqlCacheDependency特性,使得我们可以避免“数据过期”的问题,它能够根据数据库中相应数据的变化,通知缓存,并移除那 些过期的数据。事实上,在PetShop 4.0中,就充分地利用了SqlCacheDependency特性。 4.2 SqlCacheDependency特性 SqlCacheDependency 特性实际上是通过System.Web.Caching.SqlCacheDependency类来体现的。通过该类,可以在所有支持的SQL Server版本(7.0,2000,2005)上监视特定的SQL Server数据库表,并创建依赖于该表以及表中数据行的缓存项。当数据表或表中特定行的数据发生更改时,具有依赖项的数据项就会失效,并自动从 Cache中删除该项,从而保证了缓存中不再保留过期的数据。
由于版本的原因,SQL Server 2005完全支持SqlCacheDependency特性,但对于SQL Server 7.0和SQL Server 2000而言,就没有如此幸运了。毕竟这些产品出现在.Net Framework 2.0之前,因此它并没有实现自动监视数据表数据变化,通知ASP.NET的功能。解决的办法就是利用轮询机制,通过ASP.NET进程内的一个线程以指 定的时间间隔轮询SQL Server数据库,以跟踪数据的变化情况。 要使得7.0或者2000版本的SQL Server支持SqlCacheDependency特性,需要对数据库服务器执行相关的配置步骤。有两种方法配置SQL Server:使用aspnet_regsql命令行工具,或者使用SqlCacheDependencyAdmin类。 4.2.1 利用aspnet_regsql工具 aspnet_regsql工具位于Windows//Microsoft.NET//Framework//[版本]文件夹中。如果直接双击该工具的执行文件,会弹出一个向导对话框,提示我们完成相应的操作: 
图4-1 aspnet_regsql工具
如 图4-1所示中的提示信息,说明该向导主要用于配置SQL Server数据库,如membership,profiles等信息,如果要配置SqlCacheDependency,则需要以命令行的方式执行。以 PetShop 4.0为例,数据库名为MSPetShop4,则命令为:
aspnet_regsql -S localhost -E -d MSPetShop4 -ed 以下是该工具的命令参数说明:
-? 显示该工具的帮助功能;
-S 后接的参数为数据库服务器的名称或者IP地址;
-U 后接的参数为数据库的登陆用户名;
-P 后接的参数为数据库的登陆密码;
-E 当使用windows集成验证时,使用该功能;
-d 后接参数为对哪一个数据库采用SqlCacheDependency功能;
-t 后接参数为对哪一个表采用SqlCacheDependency功能;
-ed 允许对数据库使用SqlCacheDependency功能;
-dd 禁止对数据库采用SqlCacheDependency功能;
-et 允许对数据表采用SqlCacheDependency功能;
-dt 禁止对数据表采用SqlCacheDependency功能;
-lt 列出当前数据库中有哪些表已经采用sqlcachedependency功能。 以上面的命令为例,说明将对名为MSPetShop4的数据库采用SqlCacheDependency功能,且SQL Server采用了windows集成验证方式。我们还可以对相关的数据表执行aspnet_regsql命令,如:
aspnet_regsql -S localhost -E -d MSPetShop4 -t Item -et
aspnet_regsql -S localhost -E -d MSPetShop4 -t Product -et
aspnet_regsql -S localhost -E -d MSPetShop4 -t Category -et 当 执行上述的四条命令后,aspnet_regsql工具会在MSPetShop4数据库中建立一个名为 AspNet_SqlCacheTablesForChangeNotification的新数据库表。该数据表包含三个字段。字段tableName记 录要追踪的数据表的名称,例如在PetShop 4.0中,要记录的数据表就包括Category、Item和Product。notificationCreated字段记录开始追踪的时间。 changeId作为一个类型为int的字段,用于记录数据表数据发生变化的次数。如图4-2所示: 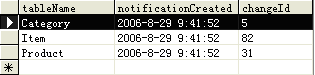
图4-2 AspNet_SqlCacheTablesForChangeNotification数据表
除 此之外,执行该命令还会为MSPetShop4数据库添加一组存储过程,为ASP.NET提供查询追踪的数据表的情况,同时还将为使用了 SqlCacheDependency的表添加触发器,分别对应Insert、Update、Delete等与数据更改相关的操作。例如Product数 据表的触发器:
Create TRIGGER dbo.[Product_AspNet_SqlCacheNotification_Trigger] ON [Product]
FOR Insert, Update, Delete AS BEGIN
SET NOCOUNT ON
EXEC dbo.AspNet_SqlCacheUpdateChangeIdStoredProcedure N/'Product/'
END 其 中,AspNet_SqlCacheUpdateChangeIdStoredProcedure即是工具添加的一组存储过程中的一个。当对 Product数据表执行Insert、Update或Delete等操作时,就会激活触发器,然后执行 AspNet_SqlCacheUpdateChangeIdStoredProcedure存储过程。其执行的过程就是修改 AspNet_SqlCacheTablesForChangeNotification数据表的changeId字段值:
Create PROCEDURE dbo.AspNet_SqlCacheUpdateChangeIdStoredProcedure
@tableName NVARCHAR(450)
AS
BEGIN
Update dbo.AspNet_SqlCacheTablesForChangeNotification WITH (ROWLOCK) SET changeId = changeId + 1
Where tableName = @tableName
END
GO 4.2.2 利用SqlCacheDependencyAdmin类 我们也可以利用编程的方式来来管理数据库对SqlCacheDependency特性的使用。该类包含了五个重要的方法:
DisableNotifications
|
为特定数据库禁用 SqlCacheDependency对象更改通知
|
DisableTableForNotifications
|
为数据库中的特定表禁用SqlCacheDependency对象更改通知
|
EnableNotifications
|
为特定数据库启用SqlCacheDependency对象更改通知
|
EnableTableForNotifications
|
为数据库中的特定表启用SqlCacheDependency对象更改通知
|
GetTablesEnabledForNotifications
|
返回启用了SqlCacheDependency对象更改通知的所有表的列表
|
表4-1 SqlCacheDependencyAdmin类的主要方法 假设我们定义了如下的数据库连接字符串:
const string connectionStr = "Server=localhost;Database=MSPetShop4"; 那么为数据库MSPetShop4启用SqlCacheDependency对象更改通知的实现为:
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
SqlCacheDependencyAdmin.EnableNotifications(connectionStr);
}
} 为数据表Product启用SqlCacheDependency对象更改通知的实现则为:
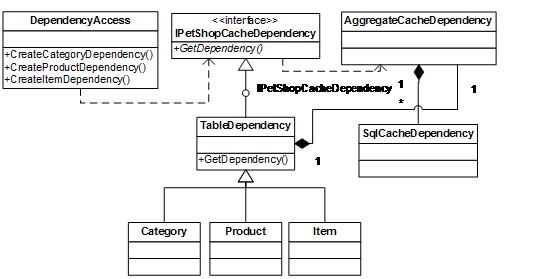
SqlCacheDependencyAdmin.EnableTableForNotifications(connectionStr, "Product"); 如果要调用表4-1中所示的相关方法,需要注意的是访问SQL Server数据库的帐户必须具有创建表和存储过程的权限。如果要调用EnableTableForNotifications方法,还需要具有在该表上创建SQL Server触发器的权限。 虽 然说编程方式赋予了程序员更大的灵活性,但aspnet_regsql工具却提供了更简单的方法实现对SqlCacheDependency的配置与管 理。PetShop 4.0采用的正是aspnet_regsql工具的办法,它编写了一个文件名为InstallDatabases.cmd的批处理文件,其中包含了对 aspnet_regsql工具的执行,并通过安装程序去调用该文件,实现对SQL Server的配置。 4.3 在PetShop 4.0中ASP.NET缓存的实现 PetShop 作为一个B2C的宠物网上商店,需要充分考虑访客的用户体验,如果因为数据量大而导致Web服务器的响应不及时,页面和查询数据迟迟得不到结果,会因此而 破坏客户访问网站的心情,在耗尽耐心的等待后,可能会失去这一部分客户。无疑,这是非常糟糕的结果。因而在对其进行体系架构设计时,整个系统的性能就显得 殊为重要。然而,我们不能因噎废食,因为专注于性能而忽略数据的正确性。在PetShop 3.0版本以及之前的版本,因为ASP.NET缓存的局限性,这一问题并没有得到很好的解决。PetShop 4.0则引入了SqlCacheDependency特性,使得系统对缓存的处理较之以前大为改观。 4.3.1 CacheDependency接口 PetShop 4.0引入了SqlCacheDependency特性,对Category、Product和Item数据表对应的缓存实施了SQL Cache Invalidation技术。当对应的数据表数据发生更改后,该技术能够将相关项从缓存中移除。实现这一技术的核心是 SqlCacheDependency类,它继承了CacheDependency类。然而为了保证整个架构的可扩展性,我们也允许设计者建立自定义的 CacheDependency类,用以扩展缓存依赖。这就有必要为CacheDependency建立抽象接口,并在web.config文件中进行配 置。 在PetShop 4.0的命名空间PetShop.ICacheDependency中,定义了名为IPetShopCacheDependency接口,它仅包含了一个接口方法:
public interface IPetShopCacheDependency
{
AggregateCacheDependency GetDependency();
} AggregateCacheDependency是.Net Framework 2.0新增的一个类,它负责监视依赖项对象的集合。当这个集合中的任意一个依赖项对象发生改变时,该依赖项对象对应的缓存对象都将被自动移除。
AggregateCacheDependency 类起到了组合CacheDependency对象的作用,它可以将多个CacheDependency对象甚至于不同类型的 CacheDependency对象与缓存项建立关联。由于PetShop需要为Category、Product和Item数据表建立依赖项,因而 IPetShopCacheDependency的接口方法GetDependency()其目的就是返回建立了这些依赖项的 AggregateCacheDependency对象。 4.3.2 CacheDependency实现 CacheDependency的实现正是为Category、Product和Item数据表建立了对应的SqlCacheDependency类型的依赖项,如代码所示:
public abstract class TableDependency : IPetShopCacheDependency
{
// This is the separator that/'s used in web.config
protected char[] configurationSeparator = new char[] { /',/' }; protected AggregateCacheDependency dependency = new AggregateCacheDependency();
protected TableDependency(string configKey)
{
string dbName = ConfigurationManager.AppSettings["CacheDatabaseName"];
string tableConfig = ConfigurationManager.AppSettings[configKey];
string[] tables = tableConfig.Split(configurationSeparator); foreach (string tableName in tables)
dependency.Add(new SqlCacheDependency(dbName, tableName));
}
public AggregateCacheDependency GetDependency()
{
return dependency;
}
} 需要建立依赖项的数据库与数据表都配置在web.config文件中,其设置如下:
根 据各个数据表间的依赖关系,因而不同的数据表需要建立的依赖项也是不相同的,从配置文件中的value值可以看出。然而不管建立依赖项的多寡,其创建的行 为逻辑都是相似的,因而在设计时,抽象了一个共同的类TableDependency,并通过建立带参数的构造函数,完成对依赖项的建立。由于接口方法 GetDependency()的实现中,返回的对象dependency是在受保护的构造函数创建的,因此这里的实现方式也可以看作是Template Method模式的灵活运用。例如TableDependency的子类Product,就是利用父类的构造函数建立了Product、Category 数据表的SqlCacheDependency依赖:
public class Product : TableDependency
{
public Product() : base("ProductTableDependency") { }
} 如 果需要自定义CacheDependency,那么创建依赖项的方式又有不同。然而不管是创建SqlCacheDependency对象,还是自定义的 CacheDependency对象,都是将这些依赖项添加到AggregateCacheDependency类中,因而我们也可以为自定义 CacheDependency建立专门的类,只要实现IPetShopCacheDependency接口即可。
|











 <%@ Page AutoEventWireup="true" Language="C#" MasterPageFile="~/MasterPage.master" Title="Products" Inherits="PetShop.Web.Products" CodeFile="~/Products.aspx.cs" %>
<%@ Page AutoEventWireup="true" Language="C#" MasterPageFile="~/MasterPage.master" Title="Products" Inherits="PetShop.Web.Products" CodeFile="~/Products.aspx.cs" %>


 {
{
 void ProcessRequest(HttpContext context);
void ProcessRequest(HttpContext context);

 bool IsReusable
bool IsReusable
 }
}
 }
}