Jemalloc 深入分析 之 配对堆Pairing Heap
为了更好的阅读效果,推荐下载pdf文档:
详细文章请参考:《jemalloc 深入分析》
https://github.com/everschen/tools/blob/master/DOC/Jemalloc.pdf
https://download.csdn.net/download/ip5108/10941278
2.1. 配对堆Pairing Heap
斐波那契堆主要有两个缺点:编程实现难度较大和实际效率没有理论的那么快(由于它的存储结构和四个指针)。Pairing Heap的提出就是弥补斐波那契堆的两个缺点——编程简单操作的时间复杂度和斐波那契堆一样。
Pairing Heap其实就是一个具有堆(最大堆或最小堆)性质的树,它的特性不是由它的结构决定的,而是由于它的操作(插入,合并,减小一个关键字等)决定的。
一个指针指向该节点的第一个孩子lchild,一个指向它的下个兄弟next,一个指向它的上个兄弟prev(对于最左边的兄弟则指向它的父亲),对于第一个孩子,prev属性表示该孩子的父结点;对于其他结点,prev属性表示该结点的左兄弟。
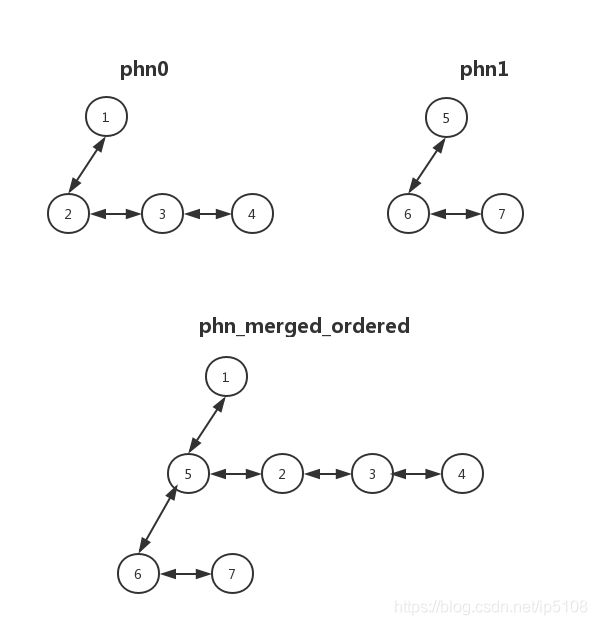
2.1.1. phn_merge_ordered
把大的作为小的树的最左孩子,插入配对树,小的树如果有孩子作为大的树的根节点的兄弟节点。
2.1.2. ph_merge_siblings
对兄弟节点两两进行merge,merge完后插入FIFO队尾(FIFO是单链表的),再进行后续节点的操作,直到只剩下一个元素为止。
由于一开始没有队尾节点,所以先进行一轮的merge操作,找到队尾和头,然后再进行循环的merge操作,直到只剩下一个节点为止。
排序后返回一个最小值的节点。

2.1.3. ph_merge_aux
对一个树作排序,找到一个最小值,作为树的root。
2.1.4. ph_merge_children
对孩子节点做排序操作,找到一个最小值。
2.1.5. a_prefix##first
对这个树作排序,找到一个最小值并返回。调用ph_merge_aux。
2.1.6. a_prefix##insert
如果树不为空,作为第一个兄弟节点。如果树为空作为root节点。
/* \
- Treat the root as an aux list during insertion, and lazily \
- merge during a_prefix##remove_first(). For elements that \
- are inserted, then removed via a_prefix##remove() before the \
- aux list is ever processed, this makes insert/remove \
- constant-time, whereas eager merging would make insert \
- O(log n). \
2.1.7. a_prefix##remove_first
对这个树作排序,找到一个最小值作为根节点,并且调用ph_merge_children,对孩子节点做排序操作,找到一个最小值作为树的新的根节点。返回原树的根节点。
2.1.8. a_prefix##remove
1)如果被删除的根节点,需要对树做merge。Merge后如果还是根节点,则需要对孩子节点做merge找到一个新的根节点。这样删除后树还是保持最小值在根节点。
2)如果被删除节点是最左孩子节点,则存在父节点。要不不存在父节点。
3)如果被删除节点是一个树,则可以对被删除节点所在的树的孩子节点进行merge,merge后从被删除节点所在的树找新的根节点,如果新的根节点存在,可以用这个节点代替被删除节点,如果该节点不存在,则直接删除这个节点。
2.1.9. 配对堆在jemalloc中的使用
主要用来管理arena_t的runs_avail,和arena_bin_t的runs。
Jemalloc 深入分析
Copyright 2013 Spreadtrum Communications Inc. 6
/* Generate pairing heap functions. */
ph_gen(static UNUSED, arena_run_heap_, arena_run_heap_t, arena_chunk_map_misc_t, ph_link, arena_snad_comp)
#define ph_gen(a_attr, a_prefix, a_ph_type, a_type, a_field, a_cmp)
a_attr void a_prefix##new(a_ph_type *ph)
a_attr bool a_prefix##empty(a_ph_type *ph)
a_attr a_type * a_prefix##first(a_ph_type *ph)
a_attr void a_prefix##insert(a_ph_type *ph, a_type *phn)
a_attr a_type * a_prefix##remove_first(a_ph_type *ph)
a_attr void a_prefix##remove(a_ph_type *ph, a_type *phn)
实际的定义函数如下:
static void arena_run_heap_new(arena_run_heap_t *ph)
static bool arena_run_heap_empty(arena_run_heap_t *ph)
static a_type * arena_run_heap_first(arena_run_heap_t *ph)
static void arena_run_heap_insert(arena_run_heap_t *ph, arena_chunk_map_misc_t *phn)
static a_type * arena_run_heap_remove_first(arena_run_heap_t *ph)
static void arena_run_heap_remove(arena_run_heap_t *ph, arena_chunk_map_misc_t phn)
/ Node structure. */
#define phn(a_type)
struct {
a_type *phn_prev;
a_type *phn_next;
a_type phn_lchild;
}
/ Root structure. */
#define ph(a_type)
struct {
a_type *ph_root;
}
typedef ph(arena_chunk_map_misc_t) arena_run_heap_t;
struct {
arena_chunk_map_misc_t ph_root;
};
struct arena_bin_s {
/
- All operations on runcur, runs, and stats require that lock be
- locked. Run allocation/deallocation are protected by the arena lock,
- which may be acquired while holding one or more bin locks, but not
- vise versa.
/
malloc_mutex_t lock;
/ - Current run being used to service allocations of this bin’s size
- class.
*/
arena_run_t runcur;
/ - Heap of non-full runs. This heap is used when looking for an
- existing run when runcur is no longer usable. We choose the
- non-full run that is lowest in memory; this policy tends to keep
- objects packed well, and it can also help reduce the number of
- almost-empty chunks.
/ arena_run_heap_t runs;
/ Bin statistics. /
malloc_bin_stats_t stats;
};
struct arena_s {
Jemalloc 深入分析
Copyright 2013 Spreadtrum Communications Inc. 8
/ This arena’s index within the arenas array. /
unsigned ind;
……
/ - Size-segregated address-ordered heaps of this arena’s available runs,
- used for first-best-fit run allocation. Runs are quantized, i.e.
- they reside in the last heap which corresponds to a size class less
- than or equal to the run size.
*/ arena_run_heap_t runs_avail[NPSIZES];
};
phn(arena_chunk_map_misc_t) ph_link;
struct {
arena_chunk_map_misc_t *phn_prev;
arena_chunk_map_misc_t *phn_next;
arena_chunk_map_misc_t phn_lchild;
}
/ - Each arena_chunk_map_misc_t corresponds to one page within the chunk, just
- like arena_chunk_map_bits_t. Two separate arrays are stored within each
- chunk header in order to improve cache locality.
/
struct arena_chunk_map_misc_s {
/ - Linkage for run heaps. There are two disjoint uses:
-
- arena_t’s runs_avail heaps.
-
- arena_bin_t conceptually uses this linkage for in-use non-full
- runs, rather than directly embedding linkage.
/ phn(arena_chunk_map_misc_t) ph_link;
union {
/ Linkage for list of dirty runs. /
arena_runs_dirty_link_t rd;
/ Profile counters, used for large object runs. */
union {
void *prof_tctx_pun;
prof_tctx_t prof_tctx;
};
/ Small region run metadata. */
arena_run_t run;
};
};
比较函数:arena_snad_comp,先比较arena_sn_comp,如果两个arena_chunk_map_misc_t 来自同一个chunk,则arena_sn_comp结果一样,再用arena_ad_comp直接比较两个地址。
详细文章请参考:《jemalloc 深入分析》
https://github.com/everschen/tools/blob/master/DOC/Jemalloc.pdf
https://download.csdn.net/download/ip5108/10941278