新手初试python爬取51job(前程无忧)的职位信息
目标:
搜索关键字:数据分析
地点: 北上广深
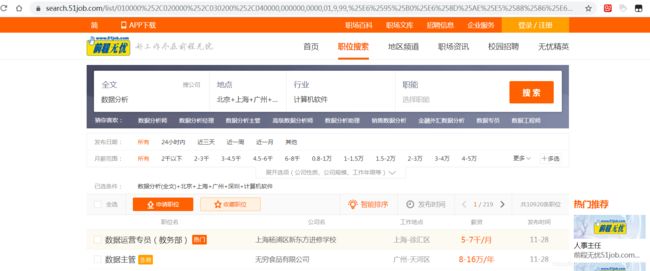
URL:https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,01,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
有用部分为‘?’之前的,即:https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,01,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html
想要获取的信息为: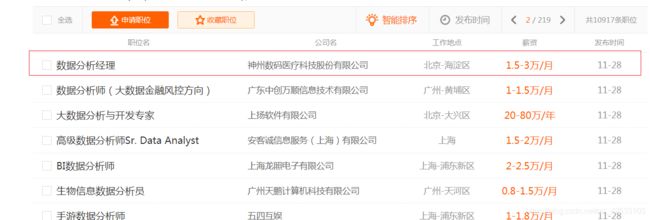
以及点击职位名进入详细信息中的:
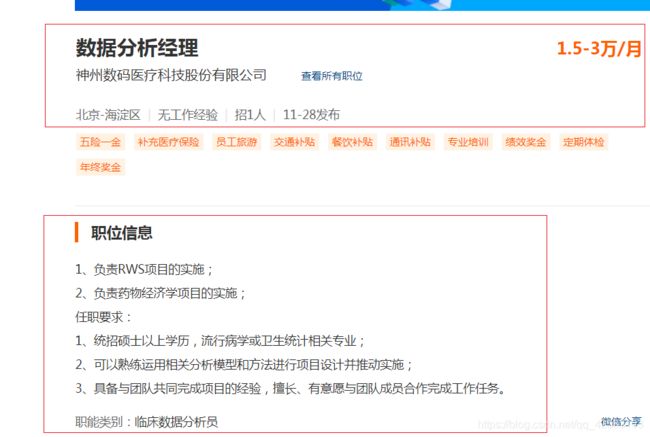
这些数据并写入csv文件中。
分析:
1、url
‘https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,01,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html’
中‘%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590’为关键字转码后的编码。
‘010000%252C020000%252C030200%252C040000’应为‘北上广深’地理位置的转码。
‘1.html’为页数。
2、请求request
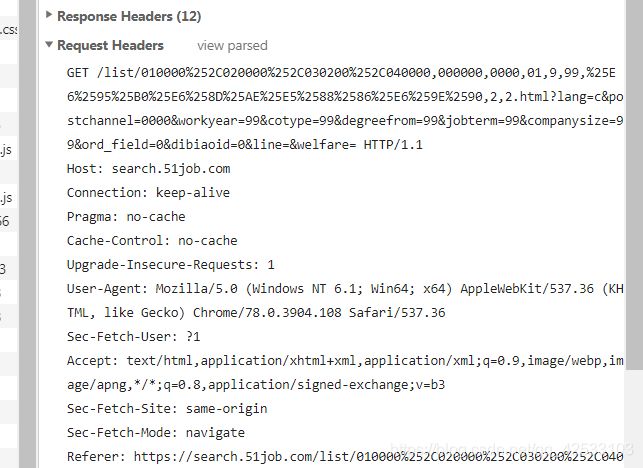
3、查看目标数据的html结构为:
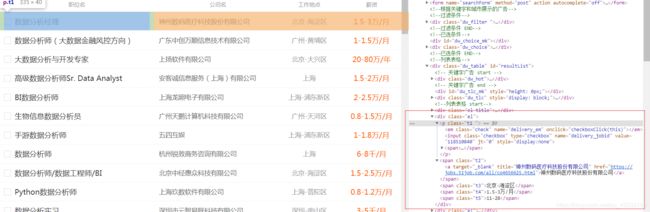


码代码
1、导包:
from bs4 import BeautifulSoup # 解析html
import urllib.parse # 调整关键字编码
import requests # 请求所用的包
import csv # 内置csv包,读写csv文件时使用
import time # time延迟操作,防止爬取数据过快导致限制ID访问——不知道是否有用!!!2、url头部处理和关键字编码:
# 关键字
key = '数据分析'
# 编码调整,如将“数据分析师”编码成%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588
key = urllib.parse.quote(urllib.parse.quote(key))
# 代理
User_Agent = r'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
headers = {'User-Agent': User_Agent,
'Host': 'search.51job.com',
'Upgrade-Insecure-Requests': '1'}3、构造获取html的方法:
# 获取jd列表页面的html
def getListHtml(page):
print('开始获取html')
url = 'https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,01,9,99,' + \
key + ',2,' + str(page) + '.html' # 构造url
r = requests.get(url, headers, timeout=10) # 使用requests发送请求
r.encoding = 'gbk'
time.sleep(1) # 延迟1秒
return r.text # 返回html
# 获取jd详情页面的html
def getDetailsHtml(url):
print('开始岗位详情html')
r = requests.get(url, headers, timeout=10) # 使用requests发送请求
r.encoding = 'gbk'
time.sleep(0.5) # 延迟0.5秒
return r.text # 返回html4、解析html
(1)解析职位列表
# 获取html
html = getListHtml(page) # 此代码中page未定义
# 使用BeautifulSoup解析html
soup = BeautifulSoup(html, 'html.parser')
# 根据网页html结构 查找出div的class包含‘el’的所有节点
all_link = soup.find_all('div', class_='el')
# 遍历所有节点
for link in all_link:
# 判断节点下是否有p标签
if link.p:
# 判断p标签下是否有a标签
if link.p.a:
# 以上判断是基于网页的dom结构分析得出
# 获取职位名称,get_text()的参数可以不带,具体说明查看BeautifulSoup文档!
jd_name = link.p.a.get_text("|", strip=True) # 职位名
# 获取职位详情的url,为获取第二部分数据做准备
jd_url = link.p.a['href'] # 职位详情url
company_name = link.find('span', class_='t2').string # 公司名
workplace = link.find('span', class_='t3').string # 工作地点
salary = link.find('span', class_='t4').string # 薪资
issue_time = link.find('span', class_='t5').string # 发布时间以上代码是根据网页结构(如下)自行分析得出的(因为本人第一次写爬虫,仅以自己经验得出,望见谅):
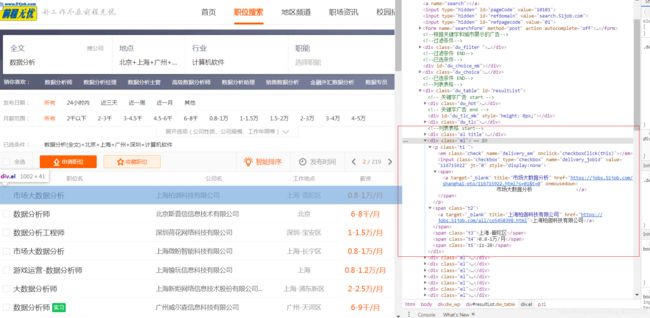
(2)解析职位详情
# 获取html
html = getDetailsHtml(jd_url)
# 解析html
soup = BeautifulSoup(html, 'html.parser')
# 判断div的class中是否含有‘cn’的节点,为什么要判断呢?因为有少数职位详情页面的url并非51job的详情页面,而是某些企业官网的招聘url,所有页面结构不一样,这种数据我自动舍弃了。
if soup.find('div', class_='cn'):
# 找到包含数据信息的节点,并获取信息。但这些信息是糅杂在一起的,需要二次解析。
result = soup.find('div', class_='cn').find('p', class_='msg').get_text(" ", strip=True)
# 拆分糅杂数据,并不完全准确,有些企业的招聘信息没有经验要求等导致
experience = result.split('|')[1] # 经验要求
education = result.split('|')[2] # 学历要求
people = result.split('|')[3] # 招聘人数
# 将岗位描述、要求板块的所有文字拿下来了。
describe = soup.find('div', attrs='bmsg job_msg inbox').get_text(' ', strip=True) # 岗位职责要求
以上代码是根据网页结构(如下)自行分析得出的:

北京-海淀区 | 无工作经验 | 招1人 | 11-28发布
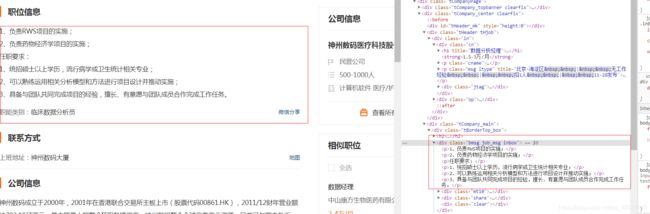
5、写入csv文件:
# 打开csv文件 ——'a+'-'追加'
csvFile = open("51job数据分析.csv", 'a+', newline='')
writer = csv.writer(csvFile)
# 写表头
writer.writerow(('职位名',
'职位详情url',
'公司名',
'工作地点',
'薪资',
'发布时间',
'经验要求',
'学历要求',
'招聘人数',
'职位信息'))
# 写入数据——值的注意的一点就是岗位描述中可能会出现编码错误,要忽略才可以不然会报错。
writer.writerow((jd_name, jd_url, company_name, workplace, salary, issue_time, experience, education, people, describe.encode("gbk", 'ignore').decode("gbk", "ignore")))
# 关闭写入文件
csvFile.close()最终代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: 51job
Description :
Author : Mr.Zhang
date: 2019/11/27 0027
-------------------------------------------------
Change Activity:
2019/11/27 0027:
-------------------------------------------------
"""
__author__ = 'Mr.Zhang'
from bs4 import BeautifulSoup # 解析html
import urllib.parse # 调整关键字编码
import requests # 请求所用的包
import csv # 内置csv包,读写csv文件时使用
import time # time延迟操作,防止爬取数据过快导致限制ID访问——不知道是否有用!!!
# 关键字
key = '数据分析'
# 编码调整,如将“数据分析师”编码成%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588
key = urllib.parse.quote(urllib.parse.quote(key))
# 代理
User_Agent = r'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
headers = {'User-Agent': User_Agent,
'Host': 'search.51job.com',
'Upgrade-Insecure-Requests': '1'}
# 获取jd列表页面的html
def getListHtml(page):
print('获取jd列表')
url = 'https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,01,9,99,' + \
key + ',2,' + str(page) + '.html' # 构造url
r = requests.get(url, headers, timeout=10) # 使用requests发送请求
r.encoding = 'gbk'
time.sleep(1)
return r.text # 返回html
# 获取jd详情页面的html
def getDetailsHtml(url):
print('获取jd详情')
r = requests.get(url, headers, timeout=10)
r.encoding = 'gbk'
time.sleep(0.5)
return r.text # 返回html
# 打开csv文件
csvFile = open("51job数据分析.csv", 'a+', newline='')
writer = csv.writer(csvFile)
writer.writerow(('职位名',
'职位详情url',
'公司名',
'工作地点',
'薪资',
'发布时间',
'经验要求',
'学历要求',
'招聘人数',
'职位信息'))
try:
# 51job每页有50个岗位,一共有220页
for page in range(1, 220):
# 获取html
html = getListHtml(page)
# 使用BeautifulSoup解析html
soup = BeautifulSoup(html, 'html.parser')
# 根据网页html结构 查找出div的class包含‘el’的所有节点
all_link = soup.find_all('div', class_='el')
# 遍历所有节点
for link in all_link:
# 判断节点下是否有p标签
if link.p:
# 判断p标签下是否有a标签
if link.p.a:
jd_name = link.p.a.get_text("|", strip=True) # 职位名
jd_url = link.p.a['href'] # 职位详情url
company_name = link.find('span', class_='t2').string # 公司名
workplace = link.find('span', class_='t3').string # 工作地点
salary = link.find('span', class_='t4').string # 薪资
issue_time = link.find('span', class_='t5').string # 发布时间
html = getDetailsHtml(jd_url)
soup = BeautifulSoup(html, 'html.parser')
if soup.find('div', class_='cn'):
result = soup.find('div', class_='cn').find('p', class_='msg').get_text(" ", strip=True)
experience = result.split('|')[1] # 经验要求
education = result.split('|')[2] # 学历要求
people = result.split('|')[3] # 招聘人数
describe = soup.find('div', attrs='bmsg job_msg inbox').get_text(' ', strip=True) # 岗位职责要求
print('写入数据:{}'.format(describe))
writer.writerow(
(jd_name, jd_url, company_name, workplace, salary, issue_time, experience, education, people, describe.encode("gbk", 'ignore').decode("gbk", "ignore")))
except Exception as e:
print(e)
finally:
# 关闭写入文件
csvFile.close()
最后提醒一下:
程序中每个岗位爬取延迟了0.5秒,所以1W数据跑了将近2小时。