C++简单实现一个websocket服务器
最近想用C++实现一个websocket服务器,到网上找了一下,其实已经有一些实现好的开源库(比如WebSocketPP),尝试了一下,代码实现可以说是十分简单了,基本不到100行代码就搭好了,自己只要实现三个回调函数(OnOpen,OnClose,OnMessage,)即定义接收到来自客户端的websocket连接,关闭,以及收到消息要干什么,然后绑定到各自的handle,基本就可以实现服务器的基本功能了。
这里给出一个开源库websocketpp的源码例子: https://download.csdn.net/download/weixin_34196559/10750141
但是对于开源库的使用,虽然是十分容易实现,但是前期配置那个依赖库还是十分的烦人的,比如WebSocketPP,是需要依赖于boost(也就是说你还得先配置好boost...TAT),所以想着自己利用原生的socket实现以下websocket协议,以后要嵌入就不会太麻烦配置一堆依赖了0.0。
废话不多说,开始一步步搭建自己的websocket服务器吧。
(本文默认你已经基本懂得如何使用原生的socket,如果不懂还是先补一下吧,这里提供一篇自我感觉写的很好的博客,附上链接socket编程)
先说一下整体的实现步骤:
1、参照socket编程创建一个服务器监听(监听连接)
2、开始接收数据(可以使用recv()函数,当然了此处也踩了不少坑,后面会详细提到),这里首先是用来接收来自客户端的协议握手(因为刚开始建立的只是基础TCP连接),收到的报文大致是这样的:
GET / HTTP/1.1
Connection:Upgrade
Host:127.0.0.1:8088
Origin:null
Sec-WebSocket-Extensions:x-webkit-deflate-frame
Sec-WebSocket-Key:puVOuWb7rel6z2AVZBKnfw==
Sec-WebSocket-Version:13
Upgrade:websocket3、根据接收到的数据(就是上面的报文),可以先判断一下是不是握手协议(这里可以直接判断一下recv从缓冲区读到的数据是否包含“GET”,虽然这里我感觉不是特别严谨,但好像网上很多都是这么写的0.0),对这个报文进行解析,获取其中的Sec-WebSocket-Key(也就是这里的puVOuWb7rel6z2AVZBKnfw==)。然后服务端要对这个key(包含24个字符)进行解析,解析方法是:
首先加上一个"神奇"的字符串"258EAFA5-E914-47DA-95CA-C5AB0DC85B11"(这个是固定的),然后对其进行sha1解码跟base64编码,就可以得到一个“密码”,然后就把这个密码再次打包一下,然后发给客户端(因为客户端也是按照同样的方式处理他发出去的key的),如果服务器发给客户端的报文密码一致的话,此时就完成了协议握手,(emmmm。。。大概就是,暗号对上了,哈哈哈),然后现在就已经成功创建了一个基于webosket协议的连接了。
这里也给出一个服务端最后打包要发给客户端的报文示例:
HTTP/1.1 101 Switching Protocols
Connection:Upgrade
Server:beetle websocket server
Upgrade:WebSocket
Date:Mon, 26 Nov 2012 23:42:44 GMT
Access-Control-Allow-Credentials:true
Access-Control-Allow-Headers:content-type
Sec-WebSocket-Accept:FCKgUr8c7OsDsLFeJTWrJw6WO8Q=4、建立连接后,就可以愉快的发送数据跟接收数据了,但是!!!虽然接收数据采用的还是socket TCP的方式,但是现在客户端发送给服务器的数据就不是普通的数据了,而是websocket格式的数据,协议的格式如下:

关于这个协议的详细介绍,这里也给出一篇推荐的博客,websocket协议解析
可以明显看出,这个协议头是占用了两个字节的(16位)我简单说一下吧。
(1)、FIN是表示这个数据是不是接收完毕(如果缓冲区长度小于客户端发送的数据长度,那显然要多次接收才能得到完整的数据啦,FIN为1表示接收到的数据是完整的),
(2)、然后opcode,也就是第4-7位,表示的是数据类型,比如客户端发送的如果是一个要断开websocket连接的请求,就可以根据这个opcode判断出来,
(3)、第8位MASK是表示后面的数据是否经过掩码处理,(规定从客户端发送给服务器的数据都是需要通过掩码处理的,所以你直接用recv收到的数据肯定是乱码的啦!!!),而从服务端发给客户端的数据是不需要使用掩码加密的,但是是肯定需要加上协议头的啦(这个地方也有不少坑!!!当时也找了半天,后面再统一说一下)
(4)、后面的显然就是表示数据长度咯
关于客户端的测试工具,也没必要自己去写一个客户端啦,小白表示自己并不是特别会前端,而且要写的话还得去看一下js的websocket,比较麻烦,这里有一个websocket的在线测试网站,可以直接在这边测试就好啦
websocket测试: http://www.blue-zero.com/WebSocket/
自此,就可以愉快玩耍啦!
关于踩过的坑:
还是按照编程过程讲起吧!!!
1、首先是关于recv函数的,recv函数是非阻塞的,数据的发送和接收是独立的,并不是发送方执行一次send,接收方就执行以此recv。recv函数不管发送几次,都会从输入缓冲区尽可能多的获取数据。如果发送方发送了多次信息,接收方没来得及进行recv,则数据堆积在输入缓冲区中,取数据的时候会都取出来。这里借用一张图解:
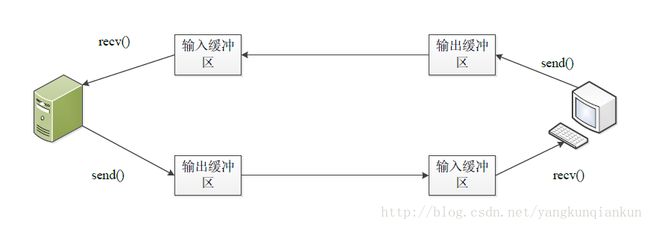
还有,recv函数返回的是一个接收到的数据(从缓冲区读出)的长度,这个数据时有可能包含有0x00(‘\0’),也就是终结符,绝对不能直接用直接把从缓冲区读出的数据直接转成string类型(比如string str = buffer),这种写法是会将数据从0x00处截断的,也不能使用strlen去获取数据长度,这个strlen函数的实现机制也是会从0x00处截断,也就是说获取到的数据长度也是错的!!!当然,一般来说在协议握手那一块接收到的数据一般是没有什么问题的(不会包含0x00),以上这个坑主要是在建立连接之后,有包含协议头的数据通讯中的!(因为数据经过了掩码处理,是有可能包含0x00的!!!)
所以如果这个地方出错的话,假设你将你要发送给客户端的数据在加上协议头的时候出错(也就是错误的协议头)的时候,利用send发送过去的话,是会导致直接断开连接的(因为websocket协议一旦你数据传输出现问题,便会断开连接(TCP连接还在))
好了,问题找出来了,那肯定就能找到解决方法啦!这里给出一种解决办法:利用memcpy函数,这个函数不同于strcpy的复制(差点忘了说,strcpy也是不行的,会截断!),用memcpy的一个内存复制机制就能解决问题了!!!
2、如果你用的是VS2017的话,可能还会出现一个问题,那就是控制台显示出来的数据是会中文乱码的!!这个我刚开始就遇到了(测试连接的时候就遇到了),但是 没去理他,TAT因为我转发回客户端显示并没有问题,但是终归不好看,看着不爽啊!后面查了查,其实只需要在主函数加上一个定义就好了:
system("chcp 65001");
最后源码我就不贴啦,这里就给出sha1跟base64吧,这两个我刚开始也是有点迷,找不到0.0
sha1.h
#pragma once
/*
* sha1.h
*
* Copyright (C) 1998, 2009
* Paul E. Jones
* All Rights Reserved.
*
*****************************************************************************
* $Id: sha1.h 12 2009-06-22 19:34:25Z paulej $
*****************************************************************************
*
* Description:
* This class implements the Secure Hashing Standard as defined
* in FIPS PUB 180-1 published April 17, 1995.
*
* Many of the variable names in this class, especially the single
* character names, were used because those were the names used
* in the publication.
*
* Please read the file sha1.cpp for more information.
*
*/
#ifndef _SHA1_H_
#define _SHA1_H_
class SHA1
{
public:
SHA1();
virtual ~SHA1();
/*
* Re-initialize the class
*/
void Reset();
/*
* Returns the message digest
*/
bool Result(unsigned *message_digest_array);
/*
* Provide input to SHA1
*/
void Input(const unsigned char *message_array,
unsigned length);
void Input(const char *message_array,
unsigned length);
void Input(unsigned char message_element);
void Input(char message_element);
SHA1& operator<<(const char *message_array);
SHA1& operator<<(const unsigned char *message_array);
SHA1& operator<<(const char message_element);
SHA1& operator<<(const unsigned char message_element);
private:
/*
* Process the next 512 bits of the message
*/
void ProcessMessageBlock();
/*
* Pads the current message block to 512 bits
*/
void PadMessage();
/*
* Performs a circular left shift operation
*/
inline unsigned CircularShift(int bits, unsigned word);
unsigned H[5]; // Message digest buffers
unsigned Length_Low; // Message length in bits
unsigned Length_High; // Message length in bits
unsigned char Message_Block[64]; // 512-bit message blocks
int Message_Block_Index; // Index into message block array
bool Computed; // Is the digest computed?
bool Corrupted; // Is the message digest corruped?
};
#endif
sha1.cpp
/*
* sha1.cpp
*
* Copyright (C) 1998, 2009
* Paul E. Jones
* All Rights Reserved.
*
*****************************************************************************
* $Id: sha1.cpp 12 2009-06-22 19:34:25Z paulej $
*****************************************************************************
*
* Description:
* This class implements the Secure Hashing Standard as defined
* in FIPS PUB 180-1 published April 17, 1995.
*
* The Secure Hashing Standard, which uses the Secure Hashing
* Algorithm (SHA), produces a 160-bit message digest for a
* given data stream. In theory, it is highly improbable that
* two messages will produce the same message digest. Therefore,
* this algorithm can serve as a means of providing a "fingerprint"
* for a message.
*
* Portability Issues:
* SHA-1 is defined in terms of 32-bit "words". This code was
* written with the expectation that the processor has at least
* a 32-bit machine word size. If the machine word size is larger,
* the code should still function properly. One caveat to that
* is that the input functions taking characters and character arrays
* assume that only 8 bits of information are stored in each character.
*
* Caveats:
* SHA-1 is designed to work with messages less than 2^64 bits long.
* Although SHA-1 allows a message digest to be generated for
* messages of any number of bits less than 2^64, this implementation
* only works with messages with a length that is a multiple of 8
* bits.
*
*/
#include "sha1.h"
/*
* SHA1
*
* Description:
* This is the constructor for the sha1 class.
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
SHA1::SHA1()
{
Reset();
}
/*
* ~SHA1
*
* Description:
* This is the destructor for the sha1 class
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
SHA1::~SHA1()
{
// The destructor does nothing
}
/*
* Reset
*
* Description:
* This function will initialize the sha1 class member variables
* in preparation for computing a new message digest.
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::Reset()
{
Length_Low = 0;
Length_High = 0;
Message_Block_Index = 0;
H[0] = 0x67452301;
H[1] = 0xEFCDAB89;
H[2] = 0x98BADCFE;
H[3] = 0x10325476;
H[4] = 0xC3D2E1F0;
Computed = false;
Corrupted = false;
}
/*
* Result
*
* Description:
* This function will return the 160-bit message digest into the
* array provided.
*
* Parameters:
* message_digest_array: [out]
* This is an array of five unsigned integers which will be filled
* with the message digest that has been computed.
*
* Returns:
* True if successful, false if it failed.
*
* Comments:
*
*/
bool SHA1::Result(unsigned *message_digest_array)
{
int i; // Counter
if (Corrupted)
{
return false;
}
if (!Computed)
{
PadMessage();
Computed = true;
}
for (i = 0; i < 5; i++)
{
message_digest_array[i] = H[i];
}
return true;
}
/*
* Input
*
* Description:
* This function accepts an array of octets as the next portion of
* the message.
*
* Parameters:
* message_array: [in]
* An array of characters representing the next portion of the
* message.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::Input(const unsigned char *message_array,
unsigned length)
{
if (!length)
{
return;
}
if (Computed || Corrupted)
{
Corrupted = true;
return;
}
while (length-- && !Corrupted)
{
Message_Block[Message_Block_Index++] = (*message_array & 0xFF);
Length_Low += 8;
Length_Low &= 0xFFFFFFFF; // Force it to 32 bits
if (Length_Low == 0)
{
Length_High++;
Length_High &= 0xFFFFFFFF; // Force it to 32 bits
if (Length_High == 0)
{
Corrupted = true; // Message is too long
}
}
if (Message_Block_Index == 64)
{
ProcessMessageBlock();
}
message_array++;
}
}
/*
* Input
*
* Description:
* This function accepts an array of octets as the next portion of
* the message.
*
* Parameters:
* message_array: [in]
* An array of characters representing the next portion of the
* message.
* length: [in]
* The length of the message_array
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::Input(const char *message_array,
unsigned length)
{
Input((unsigned char *)message_array, length);
}
/*
* Input
*
* Description:
* This function accepts a single octets as the next message element.
*
* Parameters:
* message_element: [in]
* The next octet in the message.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::Input(unsigned char message_element)
{
Input(&message_element, 1);
}
/*
* Input
*
* Description:
* This function accepts a single octet as the next message element.
*
* Parameters:
* message_element: [in]
* The next octet in the message.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::Input(char message_element)
{
Input((unsigned char *)&message_element, 1);
}
/*
* operator<<
*
* Description:
* This operator makes it convenient to provide character strings to
* the SHA1 object for processing.
*
* Parameters:
* message_array: [in]
* The character array to take as input.
*
* Returns:
* A reference to the SHA1 object.
*
* Comments:
* Each character is assumed to hold 8 bits of information.
*
*/
SHA1& SHA1::operator<<(const char *message_array)
{
const char *p = message_array;
while (*p)
{
Input(*p);
p++;
}
return *this;
}
/*
* operator<<
*
* Description:
* This operator makes it convenient to provide character strings to
* the SHA1 object for processing.
*
* Parameters:
* message_array: [in]
* The character array to take as input.
*
* Returns:
* A reference to the SHA1 object.
*
* Comments:
* Each character is assumed to hold 8 bits of information.
*
*/
SHA1& SHA1::operator<<(const unsigned char *message_array)
{
const unsigned char *p = message_array;
while (*p)
{
Input(*p);
p++;
}
return *this;
}
/*
* operator<<
*
* Description:
* This function provides the next octet in the message.
*
* Parameters:
* message_element: [in]
* The next octet in the message
*
* Returns:
* A reference to the SHA1 object.
*
* Comments:
* The character is assumed to hold 8 bits of information.
*
*/
SHA1& SHA1::operator<<(const char message_element)
{
Input((unsigned char *)&message_element, 1);
return *this;
}
/*
* operator<<
*
* Description:
* This function provides the next octet in the message.
*
* Parameters:
* message_element: [in]
* The next octet in the message
*
* Returns:
* A reference to the SHA1 object.
*
* Comments:
* The character is assumed to hold 8 bits of information.
*
*/
SHA1& SHA1::operator<<(const unsigned char message_element)
{
Input(&message_element, 1);
return *this;
}
/*
* ProcessMessageBlock
*
* Description:
* This function will process the next 512 bits of the message
* stored in the Message_Block array.
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
* Many of the variable names in this function, especially the single
* character names, were used because those were the names used
* in the publication.
*
*/
void SHA1::ProcessMessageBlock()
{
const unsigned K[] = { // Constants defined for SHA-1
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
int t; // Loop counter
unsigned temp; // Temporary word value
unsigned W[80]; // Word sequence
unsigned A, B, C, D, E; // Word buffers
/*
* Initialize the first 16 words in the array W
*/
for (t = 0; t < 16; t++)
{
W[t] = ((unsigned)Message_Block[t * 4]) << 24;
W[t] |= ((unsigned)Message_Block[t * 4 + 1]) << 16;
W[t] |= ((unsigned)Message_Block[t * 4 + 2]) << 8;
W[t] |= ((unsigned)Message_Block[t * 4 + 3]);
}
for (t = 16; t < 80; t++)
{
W[t] = CircularShift(1, W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16]);
}
A = H[0];
B = H[1];
C = H[2];
D = H[3];
E = H[4];
for (t = 0; t < 20; t++)
{
temp = CircularShift(5, A) + ((B & C) | ((~B) & D)) + E + W[t] + K[0];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = CircularShift(30, B);
B = A;
A = temp;
}
for (t = 20; t < 40; t++)
{
temp = CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[1];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = CircularShift(30, B);
B = A;
A = temp;
}
for (t = 40; t < 60; t++)
{
temp = CircularShift(5, A) +
((B & C) | (B & D) | (C & D)) + E + W[t] + K[2];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = CircularShift(30, B);
B = A;
A = temp;
}
for (t = 60; t < 80; t++)
{
temp = CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[3];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = CircularShift(30, B);
B = A;
A = temp;
}
H[0] = (H[0] + A) & 0xFFFFFFFF;
H[1] = (H[1] + B) & 0xFFFFFFFF;
H[2] = (H[2] + C) & 0xFFFFFFFF;
H[3] = (H[3] + D) & 0xFFFFFFFF;
H[4] = (H[4] + E) & 0xFFFFFFFF;
Message_Block_Index = 0;
}
/*
* PadMessage
*
* Description:
* According to the standard, the message must be padded to an even
* 512 bits. The first padding bit must be a '1'. The last 64 bits
* represent the length of the original message. All bits in between
* should be 0. This function will pad the message according to those
* rules by filling the message_block array accordingly. It will also
* call ProcessMessageBlock() appropriately. When it returns, it
* can be assumed that the message digest has been computed.
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
*
*/
void SHA1::PadMessage()
{
/*
* Check to see if the current message block is too small to hold
* the initial padding bits and length. If so, we will pad the
* block, process it, and then continue padding into a second block.
*/
if (Message_Block_Index > 55)
{
Message_Block[Message_Block_Index++] = 0x80;
while (Message_Block_Index < 64)
{
Message_Block[Message_Block_Index++] = 0;
}
ProcessMessageBlock();
while (Message_Block_Index < 56)
{
Message_Block[Message_Block_Index++] = 0;
}
}
else
{
Message_Block[Message_Block_Index++] = 0x80;
while (Message_Block_Index < 56)
{
Message_Block[Message_Block_Index++] = 0;
}
}
/*
* Store the message length as the last 8 octets
*/
Message_Block[56] = (Length_High >> 24) & 0xFF;
Message_Block[57] = (Length_High >> 16) & 0xFF;
Message_Block[58] = (Length_High >> 8) & 0xFF;
Message_Block[59] = (Length_High) & 0xFF;
Message_Block[60] = (Length_Low >> 24) & 0xFF;
Message_Block[61] = (Length_Low >> 16) & 0xFF;
Message_Block[62] = (Length_Low >> 8) & 0xFF;
Message_Block[63] = (Length_Low) & 0xFF;
ProcessMessageBlock();
}
/*
* CircularShift
*
* Description:
* This member function will perform a circular shifting operation.
*
* Parameters:
* bits: [in]
* The number of bits to shift (1-31)
* word: [in]
* The value to shift (assumes a 32-bit integer)
*
* Returns:
* The shifted value.
*
* Comments:
*
*/
unsigned SHA1::CircularShift(int bits, unsigned word)
{
return ((word << bits) & 0xFFFFFFFF) | ((word & 0xFFFFFFFF) >> (32 - bits));
}
base64.h
#pragma once
#ifndef BASE64_H
#define BASE64_H
#include
#include "sha1.h"
static const std::string base64_chars =
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789+/";
const std::string MAGICSTRING = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11";
class base64
{
public:
base64();
~base64();
std::string base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len);
private:
};
#endif //BASE64_H base64.cpp
#include "base64.h"
#include
base64::base64()
{
}
base64::~base64()
{
}
std::string base64::base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len) {
std::string ret;
int i = 0;
int j = 0;
unsigned char char_array_3[3];
unsigned char char_array_4[4];
while (in_len--) {
char_array_3[i++] = *(bytes_to_encode++);
if (i == 3) {
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for (i = 0; (i < 4); i++)
ret += base64_chars[char_array_4[i]];
i = 0;
}
}
if (i)
{
for (j = i; j < 3; j++)
char_array_3[j] = '\0';
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for (j = 0; (j < i + 1); j++)
ret += base64_chars[char_array_4[j]];
while ((i++ < 3))
ret += '=';
}
return ret;
}
以上都是自己的总结,有什么写的不对的地方欢迎指出!
因为有很多人找我要源码,我已经把源码上传的我的资源里了
源码下载地址:C++简单实现一个websocket服务器