linxu总结
@[toc]
#简介
http://man.linuxde.net/
1.通过命令解释器:shell可以实现于unix操作系统交互。
2.与dos和windows操作系统不同,unix操作系统可以让多个用户同时使用,每个用户都有自己的账号。
3.linux系统中断正在执行的程序,就要用Ctrl + c键组合而非[delete]键。
4.unix提供了多个多个shell程序(bourne shell, C shell, Korn shell,Bash shell)管理员在为用户创建账号时,就规定了用户所使用的shell程序
5.大多数的unix命令都以文件的形式保存在系统中。
6.不管是正确的命令还是错误的命令,命令结束时都会出现提示符一般为($或%,管理员为#),提示符的出现意味着先前的工作都已经结束,系统正准备接收下一个命令,
7.命令区分大小写,命令与参数之间要用空格符或者制表符分隔。把一组连续的空格符或者制表符称为空白字符串,系统规定命令中的各个部分之间至少要有一个或者多个空白字符分隔,shell程序可以把连续的多个空格符或者制表符压缩为一个空白符。参数可以是选项,表达式,指令或者文件名等。ctrl + s在xshell里面是锁死屏幕的意思ctrl+q是解锁。
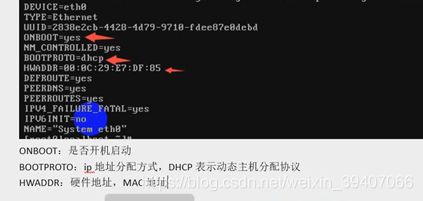
8.环境变量: linux是用:(冒号)隔开的,windows下环境变量是用;(分号)隔开的。
java -classpath lib\kutil.jar;lib\kdb.jar;lib/gs.jar ket.kdb.XX--cfg=db/xx.xml -i
java -classpath .:lib/kutil.jar:lib/kdb.jar:lib/gs.jar ket.kdb.XX--cfg=dst1223/xx.xml -i
9.Linux把文件分为三类:
普通文件:也称为标准文件,标准文件通常只保存字符流形式的数据
目录文件:通常意义,它指包含文件和其他目录的目录,但是严格地说,它只包含文件的名称及相应的数值代号。
设备文件:所有的设备和外设都可以表示为文件,从某个设备读取数据,或者向某个设备写入数据,用户只需对相应的文件执行读写操作。
在控制台运行环境的时候再命令后边加上&这个标志就可以了,加上&后Linux就可以在后台运行该任务。在后台运行任务,表示在前台的Console中可以执行其他任务。例如
![]()
后面写i3k。gmap。server是因为前面多个依赖包之间没有这个类的冲突.
10.Windows下编写的sh文件不能直接在linux上运行.如果sh脚本在Windows下编辑过,就有可能被转换成Windows下的dos文本格式了,这样的格式每一行的末尾都是以\r\n来标识,它的ASCII码分别是0x0D,0x0A。如果你将这个脚本文件直接放到Linux上执行就会报/bin/bash^M: bad interpreter错误提示。
:set ff?命令检查一下,看看是不是dos字样,如果是dos格式的,继续执行
:set ff=unix然后执行:qw保存退出即可
11.man命令:manual 手册 包含了linux中全部命令。语法: man【命令】 按q退出
12.查看linux是ubuntu还是centos
方式一:
radhat或centos存在: /etc/redhat-release 这个文件【 命令 cat /etc/redhat-release 】
ubuntu存在 : /etc/lsb-release 这个文件 【命令 cat etc/lsb-release 】
方式二:
看看安装指令,
有yum的就是Centos【yum -help】,
有apt-get的就是Ubuntu 【apt-get -help】。
#命令:
## data
显示日期,表示操作时间和日期的(读取和设置),CST 是指当地时间。date +%F(等价于date +“%Y-%m-%d”)输出形式:2019-05-29. date +"%F %T":输出格式:2019-05-29 12:15:09 单引号也可以,双引号表示两个为一个整体。等价于date +"%Y-%m-%d %H:%M:%S"。也可以获取之前或之后的时间,date -d "-1day" +"%Y-%m-%d %H:%M:%S".获取一天前的时间。date -d "-1year" +"%Y-%m-%d %H:%M:%S"。一年前的时间。减号表示之前,加好表示之后。month表示月。Date –u 显示GMT时间
获取一段时间内的每天
start=$1
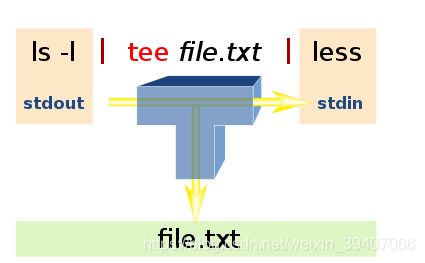
end=$2
##将输入的日期转为的时间戳格式
startDate=`date -d "${start}" +%s`
endDate=`date -d "${end}" +%s`
##计算两个时间戳的差值除于每天86400s即为天数差
stampDiff=`expr $endDate - $startDate`
dayDiff=`expr $stampDiff / 86400`
##根据天数差循环输出日期
for((i=0;i<$dayDiff;i++))
do
process_date=`date -d "${start} $i day" +'%Y%m%d'`
todo
echo $process_date
done
## 2.tput
清屏命令。为了使先前命令的输出结果或错误信息扰乱我们的注意力,可以使用,对于此命令,需要配合其他参数才能正常运行(有时可能不止一个),一般后面为 空格+ clear,执行后光标出现在左上角。
## 3.cal
日历命令,可以随时查看某个月的日历,或某年的日历,例如要看2006年7月的日历,需要输入年和月两个参数 cal 7 2006, cal -1 :表示输出当前月份日历。-3表示输出上一个月+ 当月+ 下一个月的日历。cal –y 2018 表示输出2018年的日历。-s 星期日在前,-m 星期一在前。
## 4.who
检查当前用户命令:检查有哪些用户也正在使用同一个系统 。如果登录时使用的名字是tomcat 那么系统就以这个名字与你交互,把你在计算机上的一切活动都与这个名字关联,如果你建立一个文件,系统就默认tomcat是这个文件的所有者,如果你运行一个程序,tomcat就是该程序相应进程的所有者,当给另一个用户发邮件时,这个邮件来自tomcat。用户可以从一个命令的输出数据中,抽取部分数据供下一个命令使用。whoami命令:显示当前登录的用户名。
## 5.ps
查看进程相关信息命令,ps输出的每一列都有一个表头,它详细的说明了CMD列进程的名称或者对应路径,当有多个程序运行时,ps就会输出多行,每个进程有一个唯一的编号PID称为进程标识符,只有当退出系统后,该进程才会消亡。选项:-e等价于-A 列出全部的进程,-f:显示全部的列。C列表示cpu的占用率。UID:执行该进程的用户id。PPID:该进程的父进程id。如果一个程序的父进程找不到,该程序的进程称之为僵尸进程。Stime:启动时间。TTY:该进程的终端设备识别号,“?”表示不是由终端发起。系统自动发起。Time:该进程的执行时间,ps -ef | grep 进程名称: 过滤进程
SZ表示使用掉的内存的大小。F 代表这个程序的旗标 (flag), 4 代表使用者为 super user;S 代表这个程序的状态 (STAT);ADDR 这个是 kernel function(内核),指出该程序在内存的那个部分。如果是个 running的程序,一般就是『 - 』的。-C 《指令名称》指定执行指令的名称并列出该指令的程序状况。ps -C java u
## 6. grep
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep “match_pattern” file_name在文件中搜索一个单词,命令会返回一个包含“match_pattern”的文本行,选项:输出除之外的所有行 -v 选项 grep “match_pattern” –v file_name, 使用正则表达式 -E 选项 grep –E “[1-9]+”, 统计文件或者文本中包含匹配字符串的行数 -c 选项, 大C 是匹配前后的行数,后面要跟数字(要显示的行数)。输出包含匹配字符串的行数 -n 选项。 在多级目录中对文本进行递归搜索目标匹配:–r 选项。-i :忽略大小写。egrep = grep –E 可以使用基本的正则表达外, 还可以用扩展表达式。fgrep 很简单就是固化表达式的搜索.如:fgrep "$name...[a-z]" file 就是在file里面找到和字符$name...[a-z]一样的行. 其中$和...等没有转义的意义.

![]()


① grep -E "word1|word2|word3" file.txt
满足任意条件(word1、word2和word3之一)将匹配。
② grep word1 file.txt | grep word2 |grep word3
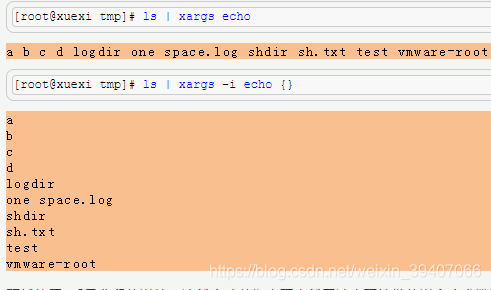
必须同时满足三个条件(word1、word2和word3)才匹配。
Grep 与 tail可以混合使用:tail -f log | grep xxx | grep yyy 管道 | 是全缓冲的,一般来说buffer_size为4096,有些是8192。不管具体值多少,只有buffer_size满了,才会看到输出。下面\|表示匹配“|”
grep -E '\|[6][0][0][0][6-9]\|' tlog.log.2020-05-* zgrep 可以grep 后缀为gz的文件
## 7.ls:
文件列表命令,可以列出当前工作目录下的所有文件夹和文件的名称,ls [路径]:列出指定目录下的文件夹和文件,相对路径中通常会用到2个符号:“。/”【表示当前目录下】, “。。/”表示上一级目录,“/”表示绝对路径。Ls【选项】【路径】:以指定格式列出指定路径下的文件夹和文件。unix有大量用于控制其运行的文件,用户也可以创建自己的程序文件,这些文件被存放在各个不同的文件夹里,在unix里统称为directory。Ls列出的文件顺序是按照字母顺序排列的,大写字母排在小写字母前,这种排序为ASCII码序。可以用“*”表示文件名类似的多个文件,比如 ls chap*(*:通配符,为元字符之一) chap01 chap02 chap03。如果显示文件名还不够,还需要更多文件信息,可以在ls命令与文件名之间加一个选项-l. 连字符:“-”,前面有连字符引导的参数表示是命令的可选项。可选参数改变了命令的默认执方式。所以加了-l(L的小写)后出了文件名还列出了文件的其他属性,-a列出包含隐藏文件的所有文件和文件夹。-l 后会有一个total + 数值,这个值的意思是:所列出的磁盘占用空间总和值,单位为kbytes。-l列出的内容的弟5列数值为该文件或目录的大小,在这里目录的大小并非是目录所包含的文件总大小,而仅仅是目录自身大小,单位为bytes。Linux里一切皆文件,有时列出的各个第五列总值加起来不等于total后的值,这是因为total值后面跟的是占用总值,文件系统中有block(块)概念,查看系统中block块大小:getconf PAGESIZE 命令, 结果为4096, 也就是4k,不足4k依然要多占用一个块(4k)。-l后信息第一列表示类型 d表示文件夹 – 表示文件, l表示link(另一个文件的链接 –>指向的是源路径)。Linux中隐藏文档一般以“.”开头。Ls –lh 以列表的形式并且在显示文档大小,以更高的可读性列出文件夹和文件。ll相当于 ls –lha 按大小排序ll -Sh 按时间排序 ll –rt
如果根据时间删除前30天的内容,可以用ls命令设置显示时间的格式
ls -l --time-style=xxx命令可以显示时间的格式,xxx:full-iso, long-iso, iso, locale, +FORMAT,
ls -l --time-style=full-iso 显示全部时间,包括毫秒在内如:
drwxr-xr-x 2 boco boco 4096 2013-10-16 14:49:57.000000000 +0800 Deskt
ls -l --time-style=long-iso 显示日期和时间(包括年),以长格式显示yyyy-mm-dd hh:mm:ss
drwxr-xr-x 2 boco boco 4096 2013-10-16 14:49 Desktop
ls -l --time-style=iso 显示日期和时间(不包括年)
drwxr-xr-x 2 boco boco 4096 10-16 14:49 Desktop
ls -l --time-style=locale 显示日期和时间(同上)
drwxr-xr-x 2 boco boco 4096 10-16 14:49 Desktop
ls -l --time-style '+%Y/%m/%d %H:%M:%S' 自定义显示格式
drwxr-xr-x 2 boco boco 4096 2013/10/16 14:49:57 Desktop
## 8.> :重定向符,ls > list 把执行结果保存在一个list文件里(没有会创建)。执行命令后屏幕不会显示任何内容,这是shell的重定向机制,它把本来输出到屏幕的内容重定向到一个磁盘文件里。它会覆盖原来的内容。,>>:追加输出:在原来的基础上追加。
##8.cat:
显示文件内容,与ls不同的在于:ls命令是列出目录中的文件,cat是显示文件的内容。Cat [文件路径],它还可以把文件合并,cat【路径1】 【路径2】…【路径n】>【合并之后的文件路径】,选项-n:表示打印行号,-v表示若输入文本时使用了一些非打印的ASCII字符时,则用-v可选项可以显示这些字符。nl 命令类似。>> 表示追加
关于cat >file,cat cat >file记录的是键盘输入,相当于从键盘创建文件,并且只能创建新文件,不能编辑已有文件.>是数据重导向,会将你输入的文本内容输出到file中。cat < ------>使用cat > file < /bin/mkdir -p /usr/local/nagios/etc cat > /usr/local/nagios/etc/nrpe.cfg << EOF ##9.wc: 统计文件的行数命令,比如统计list的文件有多少行。结果为x行 x个单词x个字符,-l表示行数,-w单词数,依照空格来判断单词数量。,-c字节数。 ##10.|: 管道符,必须配合别的命令使用(有输出的命令)。它可以连接两个命令,即把一个命令的输出通过管道导向到另一个命令的输入,这样我们可以把许多的unix命令组合起来,方便使用。一般用于“过滤”“特殊”“扩展处理”。ls | grep a :输出带a的文件或文件夹。grep:过滤命令。扩展处理: ls | wc –l :统计当前目录文件和文件夹数目。grep的选项 –v表示输出除含有给定参数外的所有行。 ##11.exit: 退出命令,暂停结束这次回话过程 并返回给定值,或者用ctrl +d,但不同的运行环境,组合键可能不会结束会话,但exit总是有效的。结束工作要退出,否则别人以你的账户操作。 ##12.echo $SHELL 查看正在用哪个shell。 ##13.命令本质上都有对应的程序文件,这些程序文件大部分是用C 语言编写的,放在某些目录下。type 命令:输出一个可执行程序的位置。但type命令只能在PATH环境变量设定的目录里查找命令文件。 ##14.printf 命令: printf命令可以用%s,%d,%f等做占位符, %s要被后面的$SHELL取代,参数个数要与占位符个数相匹配,并且还可以实现把整数转化成另一种形格式,printf为bash shell内置命令,内部命令的优先级高于外部命令。 ##15.pwd: print woking directory 打印当前工作目录 ##16.cd: 切换当前工作目录 cd 路径 “~”表示当前用户的家目录。 切换方式 cd ~ ##17.mv: 移动, 剪切 文件夹到新的位置 mv 【需要移动文件的路径】空格【目标位置】,也可以用它重命名,修改目标位置名字,可以直接移动目录,会覆盖目标路径文件。 ##18.rm: 移除,删除 rm 【选项】【目标路径】 删除时不带选项会提示是否删除,如果需要确认或取消则输入y/n。选项:-f表示force(强制)不会提示确认或取消。 删除一个目录时需要递归删除,选项-r表示递归, 可以用-rf表示不需要确认删除一个目录。也可以用“*”通配符来批量删除。后面跟多个路径也可以多个删除。 ##19.mkdir: 创建目录。mkdir[路径(文件夹名称或者路径)] 已经存在不能创建。蓝色表示文件夹,绿色表示拥有所有权限。mkdir –p [路径] 可以实现多层创建。比如一次性创建多层不存在的目录时候 添加-p会防止报错。mkdir 【路径】【路径】【路径】表示创建多个文件夹 ,mkdir –p /text/1/2/3/4 可以创建多级文件。 ##20.touch: 创建文件 touch【路径】也可以.用touch同时创建多个文件。 Touch –h在符号链接文件上更改访问和修改时间. ##21.cp: copy 复制文件/文件夹到指定位置。cp【被复制路径】【目标路径】当前目录可以直接写名字。复制过程中也可以重命名。当使用cp命令来复制一个文件夹时候需要添加-r。否则失败。 -a命令 复制文件的同时复制符号链接属性和递归、。当一次复制多个文件时,目标文件参数必须是一个已经存在的目录,否则将出现错误。会覆盖目标路径文件。 ##22.scp命令: 进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。Scp【选项】【参数】-r表示递归,参数:源文件,目标文件,此为从本地复制到远程,如果从远程复制到本地,参数顺序调换即可。-v : 显示进度,可以用来查看连接、认证或是配置错误, #scp /home/administrator/news.txt [email protected]:/etc/squid #scp [email protected]:/usr/local/sin.sh /home/administrator 如果服务器修改了ssh端口,scp则需要使用修改后的端口,如远程服务器ssh端口为2222,则需加-P参数: # scp -P 2222 /doiido/hello.sh [email protected]:/doiido 不同机房之间scp拷贝数据库文件,一定要加-l参数限速,否则游戏服务器外网整体带宽会飙升,影响业务会受影响,sz 发到本地不需要,因为咱们的本地网速不高,同机房也不需要服务商机房到机房之间走的是外网,速度没有限制,在不同机房之间传数据一定要小心,20M即可。 ##23.df指令: 查看磁盘空间 –h选项为跟ls 后跟-h一样道理,以可读性较高的形式显示 。-a表示查看全部文件系统。mounted on表示盘符挂载点。Filesystem 表示盘符, ##24.free –m 查看内存使用情况 –m是以M为单位查看,第二行free列包括了已经被分配的未被使用的内存。Swap用于临时内存,当系统内存不够用的时候可以临时使用硬盘空间开充当内存,实际内存的2-4倍。swapoff -a 关闭分区 ##25.head指令: 查看一个文件前n行。默认前10行。选项 –n。n代表查前几行。Head –n [文件路径] -c 选项表示指定显示头部内容的字符数。 ##26.tail 指令: 查看一个文件的末n行,默认后10行。选项 –n。n代表查后几行。可以用tail指令查看一个文件的动态变化(变化内容不能是用户手动增加的),tail –f 【文件路径】,该命令用于查看日志。 ##27.less命令: 查看文件,以较少的内容输出,按下辅助功能键查看更多,数字+回车(跳到指定行),空格键(翻页),上下方向键(上一行,下一行)。Less【文件路径】。。用PageUp键向上翻页,用PageDown键向下翻页。要退出less程序,应按Q键。/xxx为搜索对应文本.它可以输出ASCII里非打印控制字符中的字符,但打印出的是对应的ctrl+x。tail不能。 ##28.clear/ctrl + L命令: 清楚终端中已经存在命令和结果。该命令并不是真的清除之前的信息,而是把之前的信息隐藏到了最上面。通过滚动可以查看上面的信息。 ##29./dev/null : 属于字符特殊文件,它属于空设备,它会丢弃一切写入其中的数据,写入它的内容会永远消失,而且没有任何可以读的内容,所以我们一般会把/dev/null当成一个垃圾站,不要的东西丢进去。linux从左到右依次执行重定向的命令。用重定向绑定有一些好处。如果一个文件被打开了两次,两个文件描述符会抢占性的往文件中输出内容,会有不可预知的错误,并且所以整体IO效率不如>/dev/null 2>&1(重定向绑定)来得高。 https://blog.csdn.net/qq_31073871/article/details/80810306(输出输入重定向) 2>&1 < /dev/null 的意思就是将stderr重定向到stdout, 并将/dev/null作为stdin 注意: 1) 标准输入0、输出1、错误2需要分别重定向,一个重定向只能改变它们中的一个。 ##30.ssh语法: ssh【选项】【参数】–n 表示用/dev/null来当ssh的输入,阻止ssh读取本地的标准输入内容。ssh tomcat@主机ip + 命令 不登录主机,仅在主机执行一个命令 tomcat为我的用户,主机ip(局域网内或者远程)也可以是主机用户名,表示用tomcat用户在主机上执行了命令. 例如: ssh 47.74.236.242 './scpdb2hkjump.sh' 如果在脚本里可以写成 ` ssh 47.74.236.242 ./scpdb2hkjump.sh` ssh -n可以说这个选项是专门用来解决这个问题的。用/dev/null来当ssh的输入,阻止ssh读取本地的标准输入内容. ##31.zip 压缩和解压缩命令:zip【选项】【参数】zip -r hk_kdbbackup_20190822150000 .zip kdbbackup_20190822150000选项:-r表示递归压缩, 参数分为指定要创建的zip压缩包 (压缩包目录)和指定要压缩的文件列表(可以为多个,用空格分开)。zip -d myfile.zip smart.txt删除压缩文件中smart.txt文件,zip -u myfile.zip rpm_info.txt向压缩文件myfile.zip中添加rpm_info.txt文件。 ##32.unzip unzip【选项】【参数】选项:-o 不询问用户,直接覆盖原有文件。-d【目录】:压缩后存储的目录。unzip -o -d /home/sunny myfile.zip把myfile.zip文件解压到 /home/sunny/, -v:不解压,查看压缩文件目录。-q执行时不显示任何信息。unzip *.zip a.zip b.zip c.zip 会报错,可以写成unzip ‘*.zip’ 或者unzip “*。zip” 或者for z in *.zip do unzip -n $z done ##33.sz 命令发送文件到本地:# sz filename ##34.rz 命令本地上传文件到服务器:# rz –y 选项表示覆盖,执行该命令后,在弹出框中选择要上传的文件即可。 ##35. tar tar【选项】【参数】下面的参数是根据需要在压缩或解压档案时可选的: -z:有gzip属性的 -x 解压 -c建立 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 -C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。 -p:保留备份数据的原本权限和属性, -P:保留绝对路径,即允许备份数据中含有根目录存在(目录最前面的”/”)。压缩时候如果有根目录,解压的时候就会根据根目录解压。否则就是当前目录 tar –zxvf 解压 tar –czvf xxx.tar.gz xxx 默认递归 常见解压/压缩命令 tar .gz .tar.gz 和 .tgz .tar.bz2 .tar.bz .tar.Z .zip .rar tar 压缩排除某个文件夹或者文件 我们以tomcat 为例,打包的时候我们要排除 tomcat/logs 目录,命令如下: tar -zcvf tomcat.tar.gz --exclude=tomcat/logs tomcat 如果要排除多个目录,增加 --exclude 即可,如下命令排除logs和libs两个目录及文件xiaoshan.txt: tar -zcvf tomcat.tar.gz --exclude=tomcat/logs --exclude=tomcat/libs --exclude=tomcat/xiaoshan.txt tomcat 如果时间冲突了可以加m参数 使用解压地时间。 ##36.read 命令, 从键盘读取变量的值,通常用在shell脚本中与用户进行交互的场合。该命令可以一次读取多个变量的值,变量和输入的值都需要使用空格隔开。在read命令后面,如果没有指定变量名,读取的数据将被自动赋值给特定的变量REPLY。也可以接受用户输入,read –p 提示信息 变量名 ##37.tr : 可以对来自标准输入的字符进行替换、压缩和删除. /dev/random和/dev/urandom是Linux系统中提供的随机伪设备 /dev/urandom不依赖系统的中断,也就不会造成进程忙等待,但是数据的随机性也不高。这两个文件记录Linux下的熵池,所谓熵池就是当前系统下的环境噪音,描述了一个系统的混乱程度,环境噪音由这几个方面组成,如内存的使用,文件的使用量,不同类型的进程数量等等,刚开机的时候系统噪音会较小文件里面全是linux自己生成的char型随机数据,你把里面的字符读出来就相当于读随机数了。 https://blog.csdn.net/weixin_38239856/article/details/81979959 -c或——complerment:取代所有不属于第一字符集的字符; -d或——delete:删除所有属于第一字符集的字符; -s或--squeeze-repeats:把连续重复的字符以单独一个字符表示; -t或--truncate-set1:先删除第一字符集较变第二字符集多出的字符。 一般情况下 dc连用 tr -d '[ \t]' 其中-d后面为通配符 表示删除输入中的空格和制表符(Tab键) ##38. tee 命令用于将数据重定向到文件,另一方面还可以提供一份重定向数据的副本作为后续命令的stdin。简单的说就是把数据重定向到给定文件和屏幕上。 -a 向文件中重定向的时候使用追加模式,-i:忽略中断(interrupt)信号。 ##39.declare : declare命令用于声明和显示已存在的shell变量。当不提供变量名参数时显示所有shell变量。declare命令若不带任何参数选项,则会显示所有shell变量及其值。declare的功能与typeset命令的功能是相同的。shell变量:声明shell变量,格式为“变量名=值” 。-a 变量为数组。-i 整数, -x 环境变量, –r 只读。Declare –i sum=100+300+50 echo$sum 为450。 Bash环境中的数值运算,默认最多仅能达到整数类型。 ##40.dos2unix 命令用来将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter)。DOS下的文本文件是以 ##41.shift : shift命令用于对参数的移动(左移),通常用于在不知道传入参数个数的情况下依次遍历每个参数然后进行相应处理(常见于Linux中各种程序的启动脚本)。 ##42.Bg: 用于将作业放到后台运行,使前台可以执行其他任务。该命令的运行效果与在指令后面添加符号 ##43.查看cpu ##44.id指令 :查看一个用户的id,用户组id,附加组id, ##45.top 指令 :查看服务器进程占的资源, 是一个进入命令(动态显示),按q键退出 第五行(Swap):表示类别同第四行(Mem),但此处反映着交换分区(Swap)的使用情况。通常,交换分区(Swap)被频繁使用的情况,将被视作物理内存不足而造成的。 total 交换区总量,used 使用的交换区总量, free 空闲交换区总量,cached 缓冲的交换区总量。 nice(NI)和priority(PR),并不是同一个概念。 load average 表示 1分钟,5分钟,15分钟 内的负载情况。PID:进程id,User:该进程对应的用户,PR:优先级。NI:NInice值VIRT:虚拟内存RES:常住内存SHR:共享内存。计算一个进程实际使用的内存 = RES – SHR。S:表示进程的状态(S表示睡眠,R表示运行),Time+:执行时间(该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值),COMMAND:进程的名称或者属性。进入top命令后,按下M键:表示按照内存从高低进行降序排列,P快捷键表示结果按照CPU降序排列。1:表示各个cpu的使用率从高到低降序排列。关于各种内存:总结一下就是,虚拟内存是一个假象的内存空间,在程序运行过程中虚拟内存空间中需要被访问的部分会被映射到物理内存空间中。虚拟内存空间大只能表示程序运行过程中可访问的空间比较大,不代表物理内存空间占用也大。它表示的是进程占用的共享内存大小。在上图1中我们看到进程A虚拟内存空间中的A4和进程B虚拟内存空间中的B3都映射到了物理内存空间的A4/B3部分。咋一看很奇怪。为什么会出现这样的情况呢?其实我们写的程序会依赖于很多外部的动态库(.so),比如libc.so、libld.so等等。这些动态库在内存中仅仅会保存/映射一份,如果某个进程运行时需要这个动态库,那么动态加载器会将这块内存映射到对应进程的虚拟内存空间中。多个进展之间通过共享内存的方式相互通信也会出现这样的情况。这么一来,就会出现不同进程的虚拟内存空间会映射到相同的物理内存空间。这部分物理内存空间其实是被多个进程所共享的,所以我们将他们称为共享内存,用SHR来表示。某个进程占用的内存除了和别的进程共享的内存之外就是自己的独占内存了。所以要计算进程独占内存的大小只要用RES的值减去SHR值即可。 ##46.du –sh : 查看目录的真实大小 选项:-s: summary ,只显示汇总的大小 –h表示以较高可读性进行显示。du –sh [目录] 递归操作 ##47.find指令: 用于查找文件(55个参数),语法:find 【路径范围】 【选项】 【选项的值】。-name :按照文件名称搜索(支持模糊搜索)-type:按照文档的类型进行搜索,“-“表示文件,使用中用f替换,“d“ 表示文件夹。find -name a | wc –l 输出当前目录下的a文件的个数, find -name *b,:输出当前目录下xb文件。find -type f | wc –l:输出当前目录下文件的个数。find ../ -type d | wc –l:输出上一层级目录下文件夹的个数。可以搜出隐藏文件。iname根据文件名查找,但是不区分大小写 。在/home目录下查找以.txt结尾的文件名并忽略大小写,find /home –iname “*。txt”。默认递归操作。Maxdepth 选项可以控制最大查找深度。find . -maxdepth 1 -name "version-*.txt" 。也可以根据时间来搜索:find -type f -mtime -6 :6天内修改的文件。-mmin/分钟 用户最近一次访问时间:-atime/天,-amin/分钟。文件数据元(例如权限等)最后一次修改时间:-ctime/天,-cmin/分钟。find后如果想进一步操作,可以用exec,-exec 参数后面跟的是 command 命令,它的终止是以“;”为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。建议进一步操作前先ls查看一下,exec 选项后面跟随着所要执行的命令或脚本,然后是一对儿{},一个空格和一个\,最后是一个分号。如:find . -type f -exec ls -l {} \; find 命令匹配到了当前目录下的所有普通文件,并在 -exec 选项中使用 ls -l 命令将它们列出。 ##48.service指令: 用于控制一些软件的启动、停止、重启。语法:service 服务名 start/stop/restart ##49.kill 命令: 表示杀死进程 kill 【进程pid】可以配合ps一起使用。 ##50.ifconfig: 用于操作网卡的命令,etho表示linux中的一个网卡。Etho是名称,lo(loop,本地回还网卡,其ip地址一般都是127.0.0.1)也是一个网卡名称,inet addr就是网卡的ip地址。 ##51.reboot命令 :重新启动计算机。reboot –w 是模拟重启,但不是重启(只写关机与开机的日志信息)。 ##52.shutdown 关机(慎用,想好怎么开机)-h now “关机提示”立即关机 或者 –h 15:35 “关机提示” 表示定时关机。shutdown –c 取消关机(7.x版本)或者ctrl + c。init 0 命令、halt命令、poweroff命令也表示关机。 ##53.uptime命令 :输出计算机在线时间(从计算机开机到现在的运行时间) ##54.uname命令: 获取计算机操作系统相关的信息。uname:获取操作系统的类型,uname –a 获取全部的系统信息。可以获取内核版本、发布时间、开源计划。 ##55.netstat –tnlp 指令 查看网络连接状态 netstat -tunlp |grep 端口号,用于查看指定的端口号的进程情况 -t 表示只列出tcp协议的链接 -u (udp)仅显示udp相关选项 n 表示将地址从字母组合转化成ip地址,将协议转化成端口号来显示。 l 表示过滤出“state(状态)”列中其值为listen(监听)的链接 p 表示发起链接的进程的pid和进程名称。 a 表示所有 Local Address :本地地址:端口 如果端口尚未建立,端口号显示为星号 访问端口的方式,0.0.0.0 是对外开放端口,说明此端口外面可以访问;127.0.0.1 说明只能对本机访问,外面访问不了此端口 同时IPv6在某些条件下可以省略,以下是省略规则 规则1:每项数字前导的0可以省略,省略后前导数字仍是0则继续,例如下组IPv6是相等的 规则2:可以用双冒号"::"表示一组0或多组连续的0,但只能出现一次。 对外开放,一般都为0.0.0.0:* Recv-Q Send-Q分别表示网络接收队列,发送队列。Q是Queue的缩写。 这两个值通常应该为0,如果不为0可能是有问题的。packets在两个队列里都不应该有堆积状态。可接受短暂的非0情况。如文中的示例,短暂的Send-Q队列发送pakets非0是正常状态。 如果接收队列Recv-Q一直处于阻塞状态,可能是遭受了拒绝服务 denial-of-service 攻击。 如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快。 Recv-Q:表示收到的数据已经在本地接收缓冲,但是还有多少没有被进程取走,recv() Send-Q:对方没有收到的数据或者说没有Ack的,还是本地缓冲区. 通过netstat的这两个值就可以简单判断程序收不到包到底是包没到还是包没有被进程recv。 状态:表示一个TCP连接的状态,可能的状态如下所示: LISTENING:(Listening for a connection.) 侦听来自远方的TCP端口的连接请求 SYN-SENT:(Active; sent SYN. Waiting for a matching connection request after having sent a connection request.) 再发送连接请求后等待匹配的连接请求 SYN-RECEIVED:(Sent and received SYN. Waiting for a confirming connection request acknowledgment after having both received and sent connection requests.) 再收到和发送一个连接请求后等待对方对连接请求的确认 ESTABLISHED:(Connection established.) 代表一个打开的连接 FIN-WAIT-1:(Closed; sent FIN.) 等待远程TCP连接中断请求,或先前的连接中断请求的确认 FIN-WAIT-2:(Closed; FIN is acknowledged; awaiting FIN.) 从远程TCP等待连接中断请求 CLOSE-WAIT:(Received FIN; waiting to receive CLOSE.) 等待从本地用户发来的连接中断请求 CLOSING:(Closed; exchanged FIN; waiting for FIN.) 等待远程TCP对连接中断的确认 LAST-ACK:(Received FIN and CLOSE; waiting for FIN ACK.) 等待原来的发向远程TCP的连接中断请求的确认 TIME-WAIT:(In 2 MSL (twice the maximum segment length) quiet wait after close. ) 等待足够的时间以确保远程TCP接收到连接中断请求的确认 CLOSED:(Connection is closed.) 没有任何连接状态 ##56.sh命令 【选项】【路径】,-n 表示进行shell脚本语法检查,-x表示shell脚本逐条语句跟踪,还可以在脚本中切换用户执行命令。 su - tomcat << EOF 或者 切换用户只执行一条命令的可以用: su - tomcat -c command ##57. md5sum 查看一个文件的md5值 ##58.rsync命令 是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件。rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。 v:显示详细信息 z:传输过程中对数据进行压缩 r:递归 t:保留修改时间属性 o:保留文件所有者属性 p:保留文件权限属性 g:保留文件所属组属性 a:归档模式,主要保留文件属性,等同于-rlptgoD r : 对子目录递归处理 u: 仅在源时间比目录已存在的文件的时间新时才拷贝,注意,该选项是接收端判断的,不会影响删除行为。 --progress:显示数据传输的进度信息 --password-file=FILE:指定密码文件,将密码写入文件,实现非交互式数据同步,这个文件名也需要修改权限为600,FILE为密码文件 --delete:删除那些仅在目标路径中存在的文件(源路径中不存在),在脚本中的数据同步经常加上此参数 --list-only:仅列出服务器模块列表,需要rsync服务器设置list=true 对应于以上六种命令格式,rsync有六种不同的工作模式: ##59.https://www.cnblogs.com/archoncap/p/6103680.html linxu下的mutt安装和使用 ,linux下可以 使用mutt发送邮件。 ##60.Cksum cksum命令是检查文件的CRC是否正确,确保文件从一个系统传输到另一个系统的过程中不被损坏。这种方法要求校验和在源系统中被计算出来,在目的系统中又被计算一次,两个数字进行比较,如果校验和相等,则该文件被认为是正确传输了。注意:CRC是指一种排错检查方法,即循环冗余校验法。指定文件交由cksum命令进行校验后,会返回校验结果供用户核对文件是否正确无误。若不指定任何文件名称或是所给予的文件名为"-",则cksum命令会从标准输入设备中读取数据。返回校验码和字节数。如下: cksum testfile1 #对指定文件进行CRC校验 以上命令执行后,将输出校验码等相关的信息,具体输出信息如下所示: 1263453430 78 testfile1 #输出信息 上面的输出信息中,"1263453430"表示校验码,"78"表示字节数。 ##61.cut 命令用来显示行中的指定部分,删除文件中指定字段。cut经常用来显示文件的内容,类似于下的type命令。说明:该命令有两项功能,其一是用来显示文件的内容,它依次读取由参数file所指 明的文件,将它们的内容输出到标准输出上;其二是连接两个或多个文件,如 ##62.sort命令 是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入。sort将文件/文本的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。-n:依照数值的大小排序。 ##63.uniq命令 用于报告或忽略文件中的重复行,一般与sort命令结合使用 grep “No such file or directory” error.log |cut -d ‘ ’ -f 7 | sort | uniq grep -E "[0-9]+_[0-9]+_[0-9]" user.txt | awk '{print $11}' | awk 'BEGIN{FS="_"}{print $1}' | sort | uniq > a.txt ##64.source: 格式 source 文件路径FileName 在当前bash环境下读取并执行FileName中的命令。source 和./ 的区别 1 ./script 作为一个可执行文件来运行脚本,启动一个子shell来运行它,当执行完脚本之后,又回到了父shell中,所以在子shell中执行的一切操作都不会影响到父shell; 而source script 在当前shell环境中从文件名读取和执行命令。 2. 使用./ 运行脚本的时候,系统变量不会受到影响,而使用source的时候,会影响到系统当前的环境变量。 ##65.wait 是用来阻塞当前进程的执行,直至指定的子进程执行结束后,才继续执行。使用wait可以在bash脚本“多进程”执行模式下,起到一些特殊控制的作用。eg:wait 23 or wait %1 wait [进程号 或 作业号] 如果wait后面不带任何的进程号或作业号,那么wait会阻塞当前进程的执行,直至当前进程的所有子进程%1都执行结束后,才继续执行。 ##66.测试Linux端口的连通性的四种方法: 1. telnet ip port 。telnet为用户提供了在本地计算机上完成远程主机工作的能力,因此可以通过telnet来测试端口的连通性 2. ssh -v -p port username@ip。 SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议,在linux上可以通过ssh命令来测试端口的连通性, 3. curl ip:port。 curl是利用URL语法在命令行方式下工作的开源文件传输工具。也可以用来测试端口的连通性 4. wget ip:port。 wget是一个从网络上自动下载文件的自由工具,支持通过HTTP、HTTPS、FTP三个最常见的TCP/IP协议下载,并可以使用HTTP代理。wget名称的由来是“World Wide Web”与“get”的结合,它也可以用来测试端口的连通性 ##67.xargs 是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具,它擅长将标准输入数据转换成命令行参数,xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。xargs的默认命令是echo,空格是默认定界符。这意味着通过管道传递给xargs的输入将会包含换行和空白,但是通过xargs的处理,换行和空白将被空格取代。xargs是构建单行命令的重要组件之一。-n选项多行输出,n表示每行数量、 -i和-I: xargs -i选项在逻辑上用于接收传递的分批结果。如果不使用-i,则默认是将分割后处理后的结果整体传递到命令的最尾部。但是有时候需要传递到多个位置,不使用-i就不知道传递到哪个位置了,例如重命名备份的时候在每个传递过来的文件名加上后缀.bak,这需要两个参数位。使用xargs -i时以大括号{}作为替换符号,传递的时候看到{}就将被结果替换。可以将{}放在任意需要传递的参数位上,如果多个地方使用{}就实现了多个传递。 xargs -I(大写字母i)和xargs -i是一样的,只是-i默认使用大括号作为替换符号,-I则可以指定其他的符号、字母、数字作为替换符号,但是必须用引号包起来。man推荐使用-I代替-i,但是一般都使用-i图个简单,除非在命令中不能使用大括号,如touch {1..1000}.log时大括号就不能用来做替换符号。例如下面的重命名备份过程。 但是我将“-i”选项划分在分批选项里,它默认一个段为一个批,每次传递一个批也就是传递一个段到指定的大括号{}位上。由于-i选项是按分段来传递的。所以尽管看上去等价的xargs echo和xargs -i echo {}并不等价。 既然使用-i后是分段传递的,这就意味着指定了它就无法实现按批传递多个参数了;并且如果使用多个大括号,意味着必须使用-i,那么也无法分批传递,但可以通过使用多次xargs。解决分段的问题。 #68.vi:Vim是vi的升级版,有三种基本的大众认知模式:命令模式、编辑模式、末行模式,按i进入编辑模式 光标移动到首行:gg,光标移动到末行:shift + g 复制操作:复制光标所在行:yy。以光标所在的行为准,向下复制指定行数(包含当前行):数字(大键盘)yy 。可视化复制:ctrl + v 然后 上下左右键选择,然后yy复制块。按两下Esc退出可视化复制。 粘贴:在想要粘贴的0地方按下 p键 剪切和删除:剪切和删除光标所在行:dd 删除之后下一行上移,光标不动,但如果删除的是最后一行光标会上移。若果剪切之后不粘贴就是删除效果。以剪切或删除光标所在行为准,向下删除/剪切指定行(包含当前行):数字(大键盘)dd。删除或者剪切当前行但是下一行不上移:D, 当前行会变成空拍行,即使是最后一行,光标也不会上移。数字 D :以当前行为准删除以下行数(包括当前行和空白行) 撤销:输入“:u”(前者不属于命令模式)或“u” 恢复:取消之前的撤销操作 ctrl + r 光标的快速移动到指定行:数字 G 或者输入“:数字” 按回车 向下翻页快捷键(下一页):Ctrl + f,向上翻页快捷键(上一页):Ctrl + b 末行模式:可以在末行输入命令来对文件进行操作(搜索、替换、保存、退出、撤销、高亮等等),进入方式:由命令模式进入 按下shift + “:”或者“/”即可进入 后者紧限于搜索。退出方式:按下esc、连按两次esc、删除末行全部输入字符。 :w 保存文件但不退出vi 搜索和查找:/关键词 代表搜索 按下回车,N/n 前者向上查找,后者向下查找下一个。"/" 是从上向下查找, “?” 是从下往上查找。取消高亮:“:nohl”,设置高亮:1、临时设置:vim打开文档-->命令行形式输入set hlsearch。缺点:关闭文档后,下次打开,又需要重新设置一遍。2、永久设置(推荐):在~/.vimrc中配制, vim ~/.vimrc在文件中加上set hlsearch 然后保存退出便可。优点:一次设置,永久生效. 替换: :s/搜索的关键词/新的内容 表示替换光标所在行的第一处符合条件的内容。 :s/搜索的关键词/新的内容/g ,表示光标所在行符合条件的全部内容。 :%s/搜索的关键词/新的内容:替换整个文档中每行第一个符合条件的内容。 %表示整个文档,g表示全局(global) 显示行号 “:set nu” 隐藏行号:“:set nonu” 异常退出:在编辑文件之后没有正常退出,则会显示交换文件.【文件名】.Swp文件已存在,把交换文件删除掉即可。交换文件就是编写过程中产生的临时文件。 别名机制:创建一些属于自己的自定义命令,例如window下的cls的清屏命令,在linnux下没又这个命令。我们可以别名解决这个问题。它依靠一个别名映射文件。文件在当前家目录~.bashrc下。Vim编辑模式下 输入alias cls=“clear” 然后重新登录账户即可,=号两端不能有空格。于赋值变量类似。 退出方式为 : “:q” 或者 “:wq” 或者 “:x”。 最后一个是把前两者合二为一,智能选择。用wq退出文件即使没被修改,文件的修改时间也会更新,注意不要使用大写X, 大X 是对文件的加密,解密操作就是重新把密码设置成空即可。 ##69软连接 目录较深,此时可以创建一个快捷方式(软连接),方便以后查找。ln –s 示例: ln –s 【源路径】 【目标路径】 目标文件不能存在,成功之后是 目标 > 源 ##70diff 文件比较工具,主要以行比较为单位比较,diff【选项】【老文件】【新文件】选项:-b表示忽略一行当中仅有多个空白的区别,“about me”与“about me”视为相同,-B代表忽略空白行的区别,-i:忽略大小写 ##cmp: 主要以字节单位进行比较。Cmp【选项】【老文件】【新文件】-l表示将所有不同点的字节处都列出来 因为你cmp默认仅会输出第一个发现的不同点。 Patch:与diff合用,用于文件升级, 先用diff 和冲定向 “>” 制作补丁文件,文件一般以.patch结尾。Patch –pN < 补丁文件 ,此为更新 ,N 代表取消基层目录的意思。Patch –R –pN < 补丁文件 –R代表还原,将新的文件还原成旧的版本。 #运行模式 在linux中存在一个进程:init(initialize, 初始化)进程id 是1,该进程有一个配置文件:inittab(系统运行级别的文件, /etc/ inittab) Centos6.5中有7种运行级别/模式: 0 – 表示关机级别(不要将默认的运行级别设置成0) 1 – 单用户模式 2 – 多用户模式 不带NFS(Network File System) 3 – 多用户模式, 完全的多用户模式(不带桌面的)。 4 – 没有被使用的模式(被保留模式) 5 – X11 完整的图形化界面模式 6 – 表示重启级别(不要将默认的运行级别设置成0) 这些命令调用的都是init进程 参数是运行级别,进程去读取配置文件执行对应操作。(临时切换,非永久,改配置文件里的为永久操作) #用户管理 /etc/passwd 存储用户的关键信息,/etc/group 存储用户组的关键信息。/etc/shadow 存储用户的密码信息。 用户名:x(密码):用户id:用户主组id:注释:家目录:解释器:shell ##添加用户:useradd 【选项】【用户名】 示例:useradd zhangsan 验证方式:/etc/passwd的最后一行和是否存在家目录。在不添加选项的时候创建同名家目录,创建同名用户组. 常用选项: -g (指定用户的用户组,选项值可以是用户组id,也可以是组名) –G(指定用户的用户附加组,选项值可以是用户组id,也可以是组名) –u(uid,用户的id(用户的标识符)),系统会从500之后按顺序分配uid,如果不想使用系统分配的,可以通过该选项自定义。 -c 添加注释 -m 自动创建家目录 eg useradd -m hkActivities 记得在/etc/passwd中指定bash 案例:创建用户lisi 让lisi 属于501主组,附加组500 自选靓号666 useradd –g 501 –G 500 –u 666 lisi ##修改用户 usermod [用户名] usermod –g 500 –G 501 zhangsan -g (指定用户的用户组,选项值可以是用户组id,也可以是组名) –G(指定用户的用户附加组,选项值可以是用户组id,也可以是组名) –u(uid,用户的id(用户的标识符)),系统会从500之后按顺序分配uid,如果不想使用系统分配的,可以通过该选项自定义。 -l 修改用户名 usermod –l 新用户名 旧用户名 ##设置密码 Linux不允许没有密码的用户登录到系统,因此前面创建的用户处于锁定状态,需要设置密码后才能登录计算机,语法:passwd 【用户名】回车 开始设置密码。 ##删除用户: userdel 选项 用户名 -r :表示删除用户的同时,删除其家目录。已经登录的用户需要kill正在登录用户的全部进程,再删除。 ##切换用户 su【用户名】 如果不写用户名默认切换到管理员 从低到高权限切换要密码。反之不需要。切换前后工作路径不变。 #用户组管理 ##用户组添加 groupadd 【选项】【用户组名】 -g:自己设置一个自定义的用户组,如果自己不指定,则默认从500开始。 groupadd –g [用户附加组名] ##用户组修改 groupmod 【选项】【用户名】 groupmod –g 【新id】-n 【新名字】 用户组名 -g:自己设置一个自定义的用户组id -n: 表示设置新的用户组名称 ##删除用户组 groupdel 【用户组名】 如果要删除的组是某个用户的主组时,则不允许删除,可以先把组内用户移除。 #网络设置 网卡配置文件位置:/etc/sysconfig/network-scripts 重启网卡:service network restart /etc/init.d/network restart 停止某个网卡:ifdown 网卡名 开启某个网卡:ifup 网卡名 ##ssh服务 ssh(secure shell,安全外壳协议)作用:远程链接协议,远程文件传输协议。协议默认使用端口号:22 如果修改需要修改配置文件:/etc/ssh/ssh_config 端口号的范围:0-65535, 不能使用已经被占用的端口号。service sshd restart /etc/init.d/shhd restart。远程终端:主要有xshell、 secureCRT、 Putty ##修改主机名 临时设置主机名:需要切换用户使之生效 hostname 设置主机名(root权限) 永久设置主机名:需要重启才能生效, 文件在/etc/sysconfig/network ,修改这个文件里的hostname与临时主机名一致后,再修改linux服务器的hosts文件,将临时主机名指向本地(修改fqdn)。文件在/etc/hosts 在本地地址那行后面加上此名字即可。不设置的后果:1.很多开源服务器软件(例如Apache)则无法启动或报错。2.方便记忆,看到主机名对其作用有一个初步判断。3.会影响本地域名的解析(本地访问) ##chkconfig: 相当于windows下的“安全位置”等辅助工具,提供”开机启动项的管理服务”。 语法:chkconfig –list(两个-) ##ntp服务 作用:主要用于对计算机时间的同步管理操作。一次性同步时间:ntpdate 【时间服务器的域名或者ip地址】ip地址可以去网上搜。 ##防火墙 防火墙:防范一些网络攻击,有软件防火墙和硬件防火墙之分。选择性的让请求通过。 Centos6.5中防火墙有一个名称:iptables【7.x中默认使用的是firewalld】 查看iptables是否开机启动: 启动等操作service iptables start/restart/stop 或者 /etc/inti.d/iptables start/restart/stop 查看状态:service iptables status 查看规则的命令: iptables –L –n 含义:-L表示列出规则,-n表示显示端口号 简单设置防火墙规则: -A表示add(加到最后,如果想加到前面用- I),input 表示进站请求(进来的协议)-p表示协议, tcp表示协议类型,--dport 22:端口号。 -j:表示操作方式, accept 表示允许 reject 表示禁止。操作之后要有保存操作:/etc/init.d/iptables save 清除已有iptables规则 iptables -F iptables -X iptables -Z iptables命令选项输入顺序: iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作 表名包括: 使用 multiport 我们可以一次性在单条规则中写入多个端口: Iptables -m 扩展 -m state https://blog.csdn.net/aa43795381/article/details/101911815?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase iptables -A INPUT -p tcp -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -m state --state NEW,ESTABLISHED -j ACCEPT -m multiport 指定多端口号 iptables -A INPUT -p tcp -m multiport --dport 22,80,8080 -j ACCEPT iptables -A OUTPUT -p tcp -m multiport --sport 22,80,8080 -j ACCEPT iptables -A INPUT -p tcp -m iprange --src-range 100.0.0.0/24 --dport 80 -j ACCEPT iptables -A OUTPUT ##rpm管理 rpm的作用类似于windows上的电脑管家中的“软件管理”,可以查询、卸载、安装linux的软件包。 查询:rpm –qa | grep 关键词, -q表示查询(query), -a表示全部 卸载:rpm –e软件的名称 ,没有依赖关系可以直接卸载,如果有依赖关系的,要么先卸载依赖关系的软件,要么强制卸载:rem –e 软件包名 –nodeps(两个-) 安装:安装软件包语法:rpm –ivh 软件包完成名称,-i:install 安装,-v:显示进度条,-h:表示以#号形式显示进度条。 挂载:mount 语法:mount 设备原始地址 目标路径. 解挂:umount 语法:umount 当前设备的挂载点(路径). #cron/crontab计划内容 作用:定点执行任务。语法:crontab 【选项】【用户】 -l:表示list,列出指定用户的计划列表 -e:edit 编辑指定用户的计划任务列表 -u:user 指定的用户名,如果不指定则表示当前用户。 -r:remove 删除指定用户的计划任务列表 1.列出:crontab –l –u root 2.编辑计划任务:语法格式:以行为单位,一行则为一个计划:分 时 日 月 周 需要执行的命令。取值范围:分 0-59,时 0-23, 日 1-31, 月1-12, 周 0-6 四个符号:* - / , * 表示取值范围里的每一个数字, - 表示区间,比如1-7, / 表示每多少个,例如每10分钟一次则可以在分的位置写*/10。 “,”表示多个取值,比如想在1点2点6点执行,则可以在时的位置写:1,2,6 问题1:每月1,10,22日的4:45重启network服务 45 4 1,10,22 * * service network restart 问题2:每周六、日的1:10重启network服务 10 1 * * 6,0 service network restart 问题3:每天18:00至23:00之间每隔30分钟重启network服务 */30 18-23 * * * service network restart 问题4:每隔两天的上午8点到11点的第3和第15分钟执行一次重启 3,15 8-11 */2 * * reboot 超级管理员可以通过配置来设置某些基本用户不允许设置计划任务: 文件位于:/etc/cron.deny, 写法:里面写用户名,一行一个即可。 还有一个白名单:/etc/cron.allow 写法:里面写用户名,一行一个即可。白名单优先级高于黑名单。 在ubuntu 中用crontab -e 去设置一个定时任务,发现vi无效,也无法正常退出。 修改/etc/crontab这种方法只有root用户能用,这种方法更加方便与直接直接给其他用户设置计划任务,而且还可以指定执行shell等等,crontab -e这种所有用户都可以使用,普通用户也只能为自己设置计划任务。然后自动写入crontab -e是针对用户的cron来设计的,如果是系统的例行性任务,该怎么办?是否还是需要以crontab -e来管理例行性命令?当然不需要,只需要编辑/etc/crontab文件就可以了。需要注意的是:crontab -e的作用其实是/usr/bin/crontab这个执行文件,但是/etc/crontab是个纯文本文件,可以root的身份编辑这个文件。基本上,cron服务的最低检测时间单位是分钟,所以cron会每分钟读取一次/etc/crontab与/var/spool/cron中的数据内容,因此,只要您编辑完/etc/crontab文件并且保存之后,crontab时设定就会自动执行。注意:在Linux下的crontab会自动帮我们每分钟重新读取一次/etc/crontab的例行工作事项,但是某些原因或在其他的unix系统中,由于crontab是读到内存中,所以在您修改完/etc/crontab之后可能并不会马上执行,这时请重新启动crond服务. /var/spool/cron/usename /etc/crontab 里的配置可以试下面例子 */5 * * * * tomcat cd /home/tomcat/rxjh/game/area820/scripts/ && ./reportconsume.sh &&含义: 1.格式 command1 && command2 2.含义 &&左边的command1执行成功(返回0表示成功)后,&&右边的command2才能被执行。 ||含义:1.格式 command1 || command2 2.含义 如果||左边的command1执行失败(返回1表示失败),就执行||右边的command2。 如果想执行几个命令,则需要用命令分隔符分号隔开每个命令,并使用圆括号()把所有命令组合起来。结合||和&&可以实现复杂的功能。 1.格式(command1;command2;command3;...) 2.实例 (1)使用多个命令,如果sort命令执行成功,先将排序后的文件备份到/root/backup/目录下,然后再打印 sort facebook.txt > facebook.txt.sorted && (cp facebook.txt.sorted /root/backup/facebook.txt.sorted;lp facebook.txt.sorted) 另一个需要注意的地方在於:“你可以分别以周或者是日月为单位作为循环,但你不可使用‘几月几号且为星期几’的模式工作”。 这个意思是说,你不可以这样编写一个工作排程: 30 12 11 9 5 root echo "just test" <==这是错误的写法 本来你以为九月十一号且为星期五才会进行这项工作,无奈的是,系统可能会判定每个星期五作一次,或每年的 9 月 11 号分别进行,如此一来与你当初的规划就不一样了~所以,得要注意这个地方!上述的写法是不对的! #Linux的权限操作 Linux系统一般将文件可存/取访问的身份分为3个类别:owner、group、others,且3种身份各有read、write、execute等权限。 Owner:文件的所有者(默认为文件的所有者),group(与文件所有者同组的用户,用户可以有多个组(主组/附加组))others(其他人)Root(超级用户) 当我们ll或者ls –lha之后列出对应目录下的目录结构:第一列对应的权限描述可以解析为 权限设置:chmod【选项】【权限模式】【文档】 常用选项 : -R:递归设置权限(当文档类型为文件夹的时候)权限模式:就是该文档需要设置的权限信息.文档:可以试文件,也可以是文件夹,可以是相对路径也可以是绝对路径。 数字形式:如果出现2,3则需要关注下面的注意项 读(r):4 写(w):2执行(x):1 没任何权限:0 注意:当我们只设置写权限不设置读权限的时候,这时我们不能用vim等写入文件(因为不能读),但是可以用重定向写入文件。注意:在linux中要删除一个文件,不是看文件有没有对应的权限,而是要看文件所在的目录有没有写权限,如果有才可以删除。 #属主与属组的设置 chown:更改文档的所属用户 语法:chown【选项】【用户名】【路径】 -R:文件夹用此选项。 也可以更改用户组:语法:chown【选项】【用户名】:【用户组名】【路径】 -R:文件夹需要递归用此选项。 chgrp:更改文档所属的用户组 语法:chgrp –R 【组名】【路径】 递归的话加-R ##命令的灵活使用 Unix用户允许一个命令行输入多个命令,各个命令用“;”隔开。 当一个命令行数超过80个字符时,可以转到下一行,有时,我们必须把一个长长的命令分解成多行,针对这种情况shell会提示一个次级提示符,通常用“>”表示,它表示一个命令行还没有结束,如果是按了【enter】键之后,屏幕出现了“>”符号,往往是由于引号或括号没有配对造成。 #Shell ##编写规范 ##变量 UNIX系统具有编程特性,可以在提示符下给一个变量赋值,x=5,注意=两边不能有空格,否则解释为命令,回车后再用echo命令显示变量x,这时x前要加$。 单双引号问题: 双引号能够识别变量,双引号能够实现转移(类似于“\*”) 单引号不能识别变量,只会原样输出,单引号是不能转转义的 Local问题: (1)shell 脚本中定义的变量是global的,作用域从被定义的地方开始,一直到shell结束或者被显示删除的地方为止。 (2)shell函数定义的变量也是global的,其作用域从 函数被调用执行变量的地方 开始,到shell结束或者显示删除为止。函数定义的变量可以是local的,其作用域局限于函数内部。但是函数的参数是local的。 (3)如果局部变量和全局变量名字相同,那么在这个函数内部,会使用局部变量。 反引号(esc键下方的那个键):当在脚本中需要执行一些指令并且将执行的结果赋给变量的时候或者在一串命令中,还需要通过其他命令提供信息,可以使用反单引号“`命令`”或者$(命令)。 若变量需要在其他子进程执行(比如打开另一个shell),则需要以export来使变量变成环境变量, export PATH,通常大写字符为系统字符,自行设置变量可以使用小写字符,方便判断。终端输入export命令或env命令查看当前的环境变量。 变量的有效范围:环境变量可以被子进程所引用,其他自定义变量不会存在子进程中,环境变量可以被子进程引用的原因:这与内存配置的关系,当启动一个shell,操作系统会分配一记忆块给shell使用,此内存内的变量可以让子进程取用,若父进程利用export功能,可以让自定义变量内容写到上述的记忆块中(环境变量),当加载另一个shell时(即启动子进程,而离开原本的父进程了,)子shell可以将父shell的环境变量所在的记忆块导入自己的环境变量块中。 数组变量类型 var[index]=content var:数组名index索引content内容,般来说读取建议直接以${数组}的方式读取 只读变量 :readonly 变量名 ##Shell里的数学运算 算术运算符指的是可以在程序中实现加、减、乘、除等数学运算的运算符。Shell中常用的数学运算符如下所示。 +:对两个变量做加法。 -:对两个变量做减法。 *:对两个变量做乘法。 /:对两个变量做除法。 **:对两个变量做幂运算。 %:取模运算,第一个变量除以第二个变量求余数。 +=:加等于,在自身基础上加第二个变量。 -=:减等于,在第一个变量的基础上减去第二个变量。 *=:乘等于,在第一个变量的基础上乘以第二个变量。 /=:除等于,在第一个变量的基础上除以第二个变量。 %=:取模赋值,第一个变量对第二个变量取模运算,再赋值给第一个变量。 注意:echo 1+2 Shell并没有输出结果3,而是输出了1+2。在shell中有三种方法可以更改运算顺序 — 用expr改变运算顺序。可以用echo `expr 1 +2`来输出1+2的结果,用expr表示后面的表达式为一个数学运算。需要注意的是,`并不是一个单引号,而是“Tab”键上面的那个符号。两个变量和符号间要有空格。 ((i=$j+$k)) 等价于 i=`expr $j + $k` 二 用let指示数学运算。可以先将运算的结果赋值给变量b,运算命令是let b=1+2。然后用echo$b来输出b的值。如果没有let,则会输出1+2。 用$[]表示数学运算。将一个数学运算写到$[]符号的中括号中,中括号中的内容将先进行数学运算。例如命令echo$[1+2],将输出结果3。 可以用expr判断是不是数字 expr $1 "+" $2 &> /dev/null 删除变量 语法:unset 【变量名】 不能删除只读的。 ##shell 变量的高级用法 https://www.cnblogs.com/crazymagic/p/11067147.html ##if判断语句 If语句的条件需要用【】包括起来 $符号和 【】 之间有空格, == 号两边有空格。最后还要有fi结束语句。 语句块不能是空,也就是说 then 和else /else if 的语句块不能为空 注意:如果用test命令不用加中括号“【】” test 表达式1 –a 表达式2 两个都为真 test 表达式1 –o 表达式2 两个有一个为真 test !表达式1 表达式1为false时 结果为真 ##运算符 原生的bash不支持简单的数学运算,但是可以用其他命令来实现,如 expr ##关系运算符: 只支持数字,不支持字符串,除非字符串的值是数字 ##逻辑运算符: 多个条件可以放在两个中括号里也可以放在一个中括号里,两个的时候&&表示与||表示或, 一个中括号用 –a或-o,下面第一个表示如果&&第一个为真才走下一个,false直接返回 第二个表示||如果第一个为真直接返回,false会走下一个。 ##字符串运算符 ##文件测试运算符 其他检查符: ##$ $! 表示Shell最后运行的后台Process的PID(后台运行的最后一个进程的进程ID号) $$代表Shell本身的PID(ProcessID,即脚本运行的当前进程ID号) ##case … esac 语法:case $变量 in “第一个变量内容”) 程序段 ;; “第二个变量内容”) 程序段 ;; *) // 最后一个变量内容都会用*来代表所有的其他值 程序段 exit 1 ;; Esac exit命令同于退出shell,并返回给定值。在shell脚本中可以终止当前脚本执行。执行exit可使shell以指定的状态值退出。若不设置状态值参数,则shell以预设值退出。状态值0代表执行成功,其他值代表执行失败。 ##function(函数) 简单的说,函数可以在shell script中当做类似自定义执行命令的东西,最大的功能是,可以简化我们很多的程序代码。 function 函数名(){ 程序段} 注意:shell脚本的执行方式是由上而下,由左而右,因此在脚本中function的设置一定要在程序的前面。 ##while do done, unitl do done(不定循环) 语法: while [ condition ] do 程序段 done 上面是当条件满足时执行循环,下面是当满足条件终止循环 until [ condition ] do 程序段 done 此结果表明过滤后的数据传给while之后 read读的是每行的内容 ,多余的都被最后一个字段读取。read命令也有退出状态,当它从文件file中读到内容时,退出状态为0,循环继续进行;当read从文件中读完最后一行后,下次便没有内容可读了,此时read的退出状态为非0,所以循环才会退出。 ##for … do …done 和 固定循环和数值处理 语法: for var in con1 con2 con3 … do 程序段 Done seq :seq命令用于产生从某个数到另外一个数之间的所有整数。 for((初始值;限制值;执行步长)) do 程序段 done 初始值:某个变量在循环当中的初始值,类似i=1 限制值:例如i<=100 步长:i++或者i=i+2 左边输出10 右边输出4 #sed sed:sed是一个管道命令可以分析standard input,而且sed还可以将数据进行替换、删除、新增、选取特定行的功能,语法:sed【参数】【动作】 -n:只有经过特殊处理的那行才会被列出来, -e:直接在命令模式上进行sed动作编辑,-f:直接将sed的动作写在一个文件内,-f filename 则可以执行filename内的sed动作,-r:支持扩展型正则表达式(默认是基础正则表达式)-i:直接修改读取文件的内容,而不是由屏幕输出,动作用单引号包围。 动作说明:‘n1,n2动作行为’, a代表新增,c代表选定行替换,d代表删除,i代表插入,p代表打印,s代表替换指定字符。下面原本要执行sed –e才对,没有-e也行,$代表最后一行。 上面依次为删除2-4行,删除第二行,删除第二行到最后。 上面依次为增加第二行后,第二行前,和增加两行,一次增加多行要用反斜杠“\”来进行新行增加 上面依次是 替换2-5行,原来的查找第2行到第三行数据,sed方法查询2到3行数据,如果不加-n会出现在全输出的情况下重复输出(2-3行)。 上面依次是全局查找h替换为000,去掉g表示只替换每行第一个出现的h,以及只替换3-5行第一次出现的h。 上面为直接修改文件b,把文件b里的行以“.sh”结尾的替换为“!” 动作参数s 的语法: 如: 1,20s/old/new/g sed中也可以用\1和\2来代表用转义括号捕获的字符,最多可以使用九个捕获组。比如 在第一个命令中,只有第一个匹配受到影响。在第二个命令中,每个匹配都会受到影响。在这两种情况下,\1指的是由转义括号捕获的字符。 在第三个命令中,指定了两个捕获组。他们通过使用\1和引用\2。最多可以使用九个捕获组。 除了 sed -i ‘s/\-Xm\(x\|s\|n)[0-9] \+G \+//g’ **/*.sh 中的 | 表示或的意思 ##awk sed常常作用于整行的处理,awk则比较倾向于将一行分成数个“字段”来处理。 语法: awk ‘条件类型1{动作1}条件类型2{动作2}。。。‘ filename, awk可以处理后续文件也可以读取standardoutput。awk主要是处理每一行的字段内的数据,而默认的字段的分隔符为空格或【tab】键。 awk的所有后续动作都是print打印出来的。Awk的模式中可以运用多种运算和循环,与sed有很大区别,更接近其他语言编码。ssh 远程执行awk命令,如用$需要在$前加转意符 “\” 并且ssh用“ ” 执行命令 ,因为命令在字符串中,所以要加转义字符“\”, 比如\”print xxx \” 上面依次是列出每行第二列和第四列的内容,列出整行的内容。Awk的后续动作是以单引号括住的,由于单引号与双引号都必须成对的,所以print打印时非变量的文字部分要用双引号定义出来 使用 默认字段定界符是空格,可以使用-F“定界符” 明确指定一个定界符 Awk的内置变量:NF:每一行($0)拥有的字段总数,NR:目前处理的是第几行数据,FS:目前的分隔,默认是空格键。下面列出的是每行的行号和总列数。 Pattern中当使用不带参数的print时就打印当前行。 此为以“。”为分隔符列出第三列小于10的数据,第一行没有显示出来是因为我们读入第一行的时候,变量还是默认以空格键为分隔符,第2行以后才开始生效,解决办法为利用BEGIN关键字预先设置awk变量,下面为正常现象。 上面为当行数为1的时候输入为对应的文本,%10s中的10代表字符串长度,大于等于2行的时候输出对应的内容和变量,注意:awk 的所有动作都在{}内,如果有多个命令辅助时,可利用分好“;”间隔,或直接【enter】回车键来分隔开每个命令。逻辑运算符“==”,printf 的格式中需要加入\n才能换行,与bash,shell不同在awk中变量可以直接使用,不用加上$. Awk中也可以用if和循环语句,格式与其他语言一样,并且区别于bash,shell里。 先用-F 分隔字符串 然后用split函数把变量$2转化成数组zones,再打印数组,这里zid表是第几个元素 awk内可以执行命令 awk '{cmd="rm "$0;system(cmd)}' a.txt #正则表达式和通配符的区别 在文本过滤工具里,都是用正则表达式,比如像awk,sed,等,是针对文件的内容的以行为单位进行字符串处理的,专门用来处理字符串的。 而通配符多用在文件名上,比如查找find,ls,cp,等等系统命令使用,一般用来匹配文件名或者什么的用在系统命令中。 还有一点需要注意的是:*在通配符和正则表达式中有其不一样的地方,在通配符中*可以匹配任意的0个或多个字符,而在正则表达式中他是重复之前的字符零个到无穷多个,不能独立使用的。比如通配符可以用*来匹配任意字符,而正则表达式不行,他只匹配任意长度的前面的字符。https://blog.csdn.net/huiguixian/article/details/6284834 #Linux的日志 Apache的开源项目log4j它是一个功能强大的日志组件(搜索log4j 配置文件) 每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为: 上面这些级别是定义在org.apache.log4j.Level类中。Log4j只建议使用4个级别,优先级从高到低分别是error,warn,info和debug。通过使用日志级别,可以控制应用程序中相应级别日志信息的输出。例如,如果使用了info级别,则应用程序中所有低于info级别的日志信息(如debug)将不会被打印出来。项目输出信息的地方在Logger里的debug和info等方法。 #创建公钥 A:192.168.1.1 B:192.168.1.2 现在想让A无密码登陆B机器 A上运行以下命令来生成公钥和私钥 ssh-keygen -t rsa 运行该命令后会生成如下两个文件 id_rsa 和id_rsa.pub 将A生成的公钥传到B机器上的/root/.ssh/authorized_keys文件中,命令如下: scp /root/.ssh/id_rsa.pub root@B机器IP地址:/root/.ssh/authorized_keys 然后就可以在A上无密码登陆B机器了 .ssh文件在家目录下,是隐藏的。通过ll –a查看 ##Linux上安装apache-tomcat-7.0.68 Linux上解压 apache-tomcat-7.0.68. tar.gz 后,Apache Tomcat已准备就绪,但是在我们这样做之前,我们需要分配证书来访问tomcat的'Manager'和'GUI'页面,默认情况下没有设置用户名和密码。 为了验证凭证,我们将使用'apache-tomcat-7.0.68/conf/tomcat-users.xml'文件,在文件里按照例子加上rolename和username 然后启动tomcat服务器,转到/opt/tomcat/bin文件夹并运行名为“startup.sh”的脚本 验证:访问http://xx.xx.x.xxx:8080后出现 点击managerAPP提示输入账户密码:输入上面输入的账号后出现下面界面后输出账号密码然后上传war包即可、
log_facility=daemon
pid_file=/var/run/nrpe.pid
EOF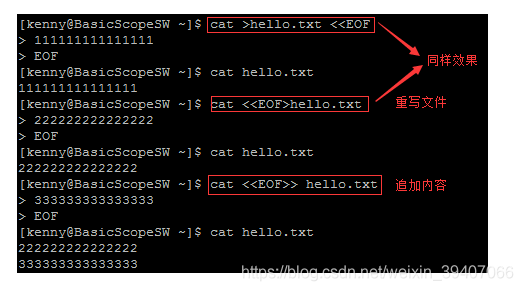
![]()

/home/administrator/ 本地文件的绝对路径
news.txt 要复制到服务器上的本地文件
root 通过root用户登录到远程服务器(也可以使用其他拥有同等权限的用户)
192.168.6.129 远程服务器的ip地址(也可以使用域名或机器名)
/etc/squid 将本地文件复制到位于远程服务器上的路径如果远程服
remote 通过remote用户登录到远程服务器(也可以使用其他拥有同等权限的用户)
www.abc.com 远程服务器的域名(当然也可以使用该服务器ip地址)
/usr/local/sin.sh 欲复制到本机的位于远程服务器上的文件
/home/administrator 将远程文件复制到本地的绝对路径


2)这三个值经常被省略。(当其出现重定向符号左侧时)
3)文件描述符在重定向符号左侧时直接写即可,在右侧时前面加&。
4)文件描述符与重定向符号之间不能有空格!
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出
解包:tar xvf FileName.ta
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz zcat –c xxx.gz |grep xxx(-c表示将文件内容写到标准输出)
压缩:gzip FileName
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
解压:tar jxvf FileName.tar.bz
压缩:未知
.Z
解压:uncompress FileName.Z
压缩:compress FileName
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
解压:rar x FileName.rar
压缩:rar a FileName.rar DirName 
\r\n作为断行标志的,表示成十六进制就是0D 0A。而Unix下的文本文件是以\n作为断行标志的,表示成十六进制就是0A。DOS格式的文本文件在Linux底下,用较低版本的vi打开时行尾会显示^M,而且很多命令都无法很好的处理这种格式的文件,如果是个shell脚本,。而Unix格式的文本文件在Windows下用Notepad打开时会拼在一起显示。因此产生了两种格式文件相互转换的需求,对应的将UNIX格式文本文件转成成DOS格式的是unix2dos命令。上面在转换时,都会直接在原来的文件上修改,如果想把转换的结果保存在别的文件,而源文件不变,则可以使用-n参数。如果要保持文件时间戳不变,加上-k参数。所以上面几条命令都是可以加上-k参数来保持文件时间戳的。dos2unix -k -n oldfile newfile
&的效果是相同的,都是将其放到系统后台执行。Bg 参数 (作业标识:指定需要放到后台的作业标识号)bg 1:如果系统中只有一个挂起的任务时,即使不为该命令设置参数"1",也可以实现这个功能。
lscpu命令,查看的是cpu的统计信息.
blue@blue-pc:~$ lscpu
Architecture: i686 #cpu架构
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian #小尾序
CPU(s): 4 #总共有4核
On-line CPU(s) list: 0-3
Thread(s) per core: 1 #每个cpu核,只能支持一个线程,即不支持超线程
Core(s) per socket: 4 #每个cpu,有4个核
Socket(s): 1 #总共有1一个cpu
Vendor ID: GenuineIntel #cpu产商 intel
Virtualization: VT-x #支持cpu虚拟化技术
查看/proc/cpuinfo,可以知道每个cpu信息,如每个CPU的型号,主频等。
#cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 42
model name : Intel(R) Core(TM) i5-2320 CPU @ 3.00GHz
.....
上面输出的是个cpu部分信息,还有3个cpu信息省略了。

NICE值应该是熟悉Linux/UNIX的人很了解的概念了,它是反应一个进程“优先级”状态的值,其取值范围是-20至19,一共40个级别。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。nice值虽然不是priority,但是它确实可以影响进程的优先级。一般会把nice值叫做静态优先级,这也基本符合nice值的特点,就是当nice值设定好了之后,除非我们用renice去改它,否则它是不变的。
实用priority值表示PRI和PR值,或者叫动态优先级。priority的值在之前内核的O1调度器上表现是会变化的,所以也叫做动态优先级。在内核中,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是MAX_PRIO,它的值为140。
而这个值又是由另外两个值相加组成的,一个是代表nice值取值范围的NICE_WIDTH宏,另一个是代表实时进程(realtime)优先级范围的MAX_RT_PRIO宏。
说白了就是,Linux实际上实现了140个优先级范围,取值范围是从0-139,这个值越小,优先级越高。nice值的-20到19,映射到实际的优先级范围是100-139。


Foreign Address:外部地址:端口 0.0.0.0是ipv4, :::是ipv6. 都表示接受对端任意ip地址
cd $deploydir;
sh -c "./stopAllServer.sh all";
sh -c "./runAllServer.sh all";
EOF
切换用户执行一个shell文件可以用:su - tomcat -s /bin/bash shell.shrsync [OPTION]... SRC DEST
rsync [OPTION]... SRC [USER@]host:DEST
rsync [OPTION]... [USER@]HOST:SRC DEST
rsync [OPTION]... [USER@]HOST::SRC DEST
rsync [OPTION]... SRC [USER@]HOST::DEST
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
rsync -a /data /backuprsync -avz *.c foo:srcrsync -avz foo:src/bar /datarsync -av [email protected]::www /databackrsync -av /databack [email protected]::wwwrsync -v rsync://192.168.78.192/wwwcut fl f2 > f3将把文件fl和几的内容合并起来,然后通过输出重定向符“>”的作用,将它们放入文件f3中。-d选项:指定字符的分隔符,默认的字段分隔符为“TAB”;



![]()

:w 【路径】将修改另外保存到file中,不退出vi
:w! 强制保存,不推出vi
:wq 保存文件并退出vi
:wq! 强制保存文件,并退出vi
:q 不保存文件,退出vi
:q! 不保存文件,强制退出vi
:e! 放弃所有修改,从上次保存文件开始再编辑
:!【外部命令】 可以执行外部命令, 外部命令执行结束后按任意键回到vim
:%s/搜索的关键词/新的内容/g:替换整个文档的符合条件的内容。![]()






iptables -A INPUT -p tcp -m multiport --dports 22,80,443 -j ACCEPT
--state {NEW,ESTATBLISHED,INVALID,RELATED} 指定检测那种状态
--sport
--dport
--ports
-m iprange 指定IP段
--src-range ip-ip
--dst-range ip-ip
-m connlimit 连接限定
--comlimit-above # 限定大连接个数
-m limit 现在连接速率,也就是限定匹配数据包的个数
--limit 指定速率
--limit-burst # 峰值速率,最大限定
-m string 按字符串限定
--algo bm|kmp 指定算法bm或kmp
--string "STRING" 指定字符串本身


只能ctrl + z 强制退出
再用ps -ef|grep crontab 找出相关的进程pid
使用 kill pid去杀死相关进程
最后从网上得知ubuntu下crontab的默认编辑器不是vi,如果要用vi需要export EDITOR=vim设置后就可以在ubuntu下用vi正常的编辑crontab了。




![]() 加减可以同时运行
加减可以同时运行

![]()




((i=$j-$k)) 等价于 i=`expr $j -$k`
((i=$j*$k)) 等价于 i=`expr $j \*$k`
((i=$j/$k)) 等价于 i=`expr $j /$k`
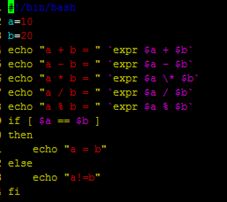
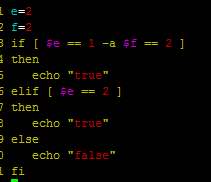
if [ $? -eq 0 ];then
echo "arg is number"
else
echo "arg not number"
exit 1
fi


















![]()

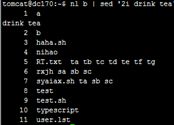


![]()
![]()
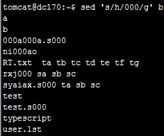


![]()


g(全局)运算符(或没有它,第一次匹配)之外,你可以指定特定的匹配项: 这个替换指定的第4个的位置
这个替换指定的第4个的位置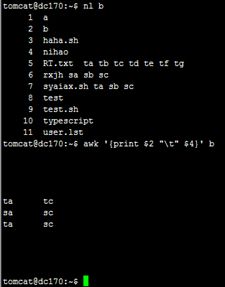
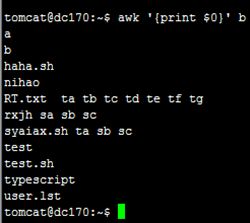
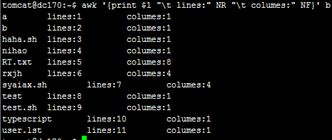
print $NF可以打印出一行中的最后一个字段,使用$(NF-1)则是打印倒数第二个字段,其他以此类推:![]()







A:off 最高等级,用于关闭所有日志记录。
B:fatal 指出每个严重的错误事件将会导致应用程序的退出。
C:error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
D:warn 表明会出现潜在的错误情形。
E:info 一般和在粗粒度级别上,强调应用程序的运行全程。
F:debug 一般用于细粒度级别上,对调试应用程序非常有帮助。
G:all 最低等级,用于打开所有日志记录。
