Python爬虫获取百度贴吧进行手游评测同时生成词云并进行情感分析——信息检索课设
文章目录
- 一、背景以及需求分析
- 二、前期的准备:Python的安装,第三方库的使用,一些常见问题
- 三、编码过程:模块设计,编码,单元测试以及整合测试
- (一)从百度贴吧爬取相关内容,并存储在指定的txt文本中
- (二) 从指定的txt文本读取内容,生成词云
- (三) 从指定的txt文本读取内容,生成情感趋向折线图
- 四、效果展示以及不足之处
一、背景以及需求分析
最近网易研发出一款末日生存题材的手游——《明日之后》,我本人对这种类型的游戏很感兴趣,但是又担心网易第一次做这种类型的游戏没有经验,所以我准备使用Python爬虫,来爬取百度贴吧关于明日之后手游的帖子,来具体分析一下明日之后这款手游。具体思路就是使用Python爬虫获取百度贴吧有关明日之后的帖子的标题,然后把他们爬取到一个txt文本,之后再利用Python的matplotlib和jieba等第三方库来生成一个关键字词云,通过观察词云来初步评测一下明日之后,然后,我在利用Python的第三方库snownlp来进行情感分析,看一下贴吧中对明日之后的评价是正向的还是负向的。
二、前期的准备:Python的安装,第三方库的使用,一些常见问题
- 磨刀不误砍材工,首先我需要把Python以及他的强大的第三方库安装完成,Python只需要去官方网站下载安装即可,Python通过导入一些第三方库就可以完成爬虫的任务,通过request和response请求和beautiful soup请求标签的内容,最后在加上一个文档下载就可以。
- 但是我在本次课设使用的是scrapy框架,Scrapy 是一个高级的 python 爬虫框架,功能极其强大,拥有它就可以快速编写出一个爬虫项目,拥有它就可以搭建分布式架构。scrapy框架有很多依赖的库,分别是lxml、pyOpenSSL、Twisted、pywin32,共四个依赖库。
- 接下来,还需要安装生成词云有关的库文件:wordcloud、matplotlib、pillow、numpy、jieba共5个库文件。
- 最后,安装情感分析的第三方库:snownlp、pandas两个库文件
注意:
以上所提到到第三方库安装方式有两种,一种是在安装Python的文件夹下,使用cmd命令行工具,利用pip install 库文件,在线安装;另一种方式是去指定的库文件的官方网站下载安装包,然后把安装包放在Python的安装文件夹下,同样要打开cmd命令行,使用pip install 安装包名,进行安装。使用第一种安装方式的时候,有的时候会提示安装失败(失败的原因可能是版本不对,或者安装包在线找不到),这个时候需要使用第二种安装方式来安装,使用第二种安装方式的时候,需要注意下载的安装包要与Python的版本一致。
三、编码过程:模块设计,编码,单元测试以及整合测试
(一)从百度贴吧爬取相关内容,并存储在指定的txt文本中
Scrapy Engine(Scrapy 核心) 负责数据流在各个组件之间的流。Spiders(爬虫) 发出 Requests 请求,经由 Scrapy Engine(Scrapy 核心) 交给 Scheduler(调度器),Downloader(下载器)Scheduler(调度器) 获得 Requests 请求,然后根据 Requests 请求,从网络下载数据。Downloader(下载器) 的 Responses 响应再传递给 Spiders 进行分析。根据需求提取出 Items,交给 Item Pipeline 进行下载。所以我们需要设置四个Python文件,分别是settings.py、pipelines.py、items.py、以及爬虫文件。
-
在爬取贴吧之前,我们先要分析一下贴吧的页面结构,通过明日之后贴吧首页,进入贴吧首页,然后右击审查元素,可以查看页面结构,类似这样:
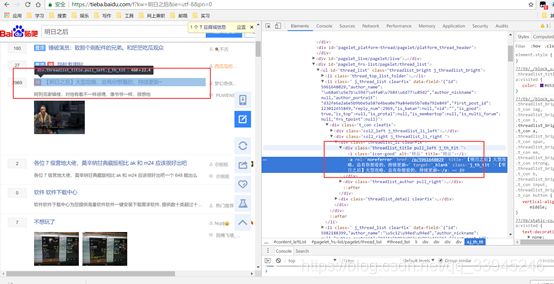
左边被选中的标题,所对应的在右边的标签中。 -
在scrapy框架中,还有一个强大的功能,通过命令行的shell命令可以辅助分析页面结构,在scrapy下有两种方式访问网页指定元素的方式,一种是通过xpath的方式,另一种是通过css选择器。
首先,在python文件夹下,用cmd命令行scrapy shell 明日之后的url:然后会进入可便捷状态,类似这样: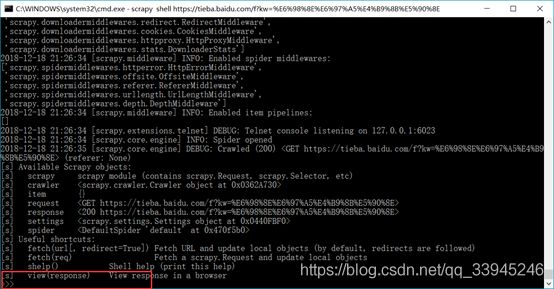
这个时候可以用response命令查看页面的全部信息,比如使用response.body可以查看页面body标签的元素:
在提取页面元素方面,xpath和css选择器各有优点,对于处理复杂页面元素,css选择器变现更好一点,所以我在这里选择使用css选择器。我通过审查元素看到在贴吧的题目是在class为threadlist_title.pull_left.j_th_tit的div标签下,所以在shell命令行输入:response.css("#thread_list div.threadlist_title.pull_left.j_th_tit a::text").extract()这个命令,可以查看当前页面所有帖子的标题: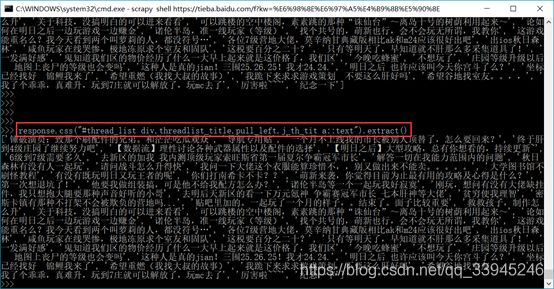
-
获取到了目标元素,就可以进行爬取工作了。
在cmd命令行使用:scrapy startproject tieba来生成一个scrapy结构文件夹,目录是这个样子的:
tieba/
scrapy.cfg
tieba/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
- 之后,在进入tieba/tieba文件,使用命令行scrapy genspider tiebaspider 来生成主爬虫文件。这样就可以编写爬虫了。生成的爬虫文件会在tieba/tieba/spiders/文件夹下。
打开tiebaspider.py文件,会有一个TiebaspiderSpider类,该类下有parse函数,用来写爬虫逻辑
核心代码:
class TiebaspiderSpider(scrapy.Spider):
name = 'tiebaspider'
# allowed_domains = ['https://tieba.baidu.com/']
# start_urls = ['https://tieba.baidu.com/f?kw=明日之后&ie=utf-8&pn=0']
# start_urls =['http://169tp.com/']
url = 'https://tieba.baidu.com/f?kw=明日之后&ie=utf-8&pn='
offset = 0
# 起始url
start_urls = [url + str(offset)]
# re_rule = re.compile('def parse(self, response):
print("开始爬虫:")
div_list = response.css("#thread_list div.threadlist_title.pull_left.j_th_tit a::text").extract()
# div_list = response.xpath('//u[@id = "thread_list"]//div[@class = "threadlist_title.pull_left.j_th_tit"]//a/text()').extract()
# div_url = re.findall(self.re_rule, div_list)
# print(div_list
item = TiebaItem()
item['text'] = div_list
yield item
if self.offset < 500:
self.offset += 50
# print("结束爬虫")
yield scrapy.Request(self.url + str(self.offset), callback = self.parse)
分析:
start_url是最开始的url,开始爬虫之后会进入parse函数,在parse函数中,通过css选择器获取页面的元素,然后通过yield来进行后续的爬虫,yield item是把爬虫的元素传送到pipelines文件处理,yield scrapy. Request是指定下一次爬取的url。
打开items.py文件,在这里是处理页面元素的格式核心就是生命数据的对象格式:
text = scrapy.Field()
- 在之后打开settings.py文件,在这个文件主要设置爬虫的一些规则,比如是否遵循robot原则,设置爬虫的深度,延迟等等元素。如果要使用pipelines,还需在settings设定好:
ITEM_PIPELINES = {
'tieba.pipelines.TiebaPipeline': 300,
}
- 最后是处理pipeline文件,在这个文件主要是把爬取的内容下载到本地的TXT文件,
核心代码如下:
class TiebaPipeline(object):
def __init__(self):
self.filename = open("test.txt", "a", encoding="utf-8")
def process_item(self, item, spider):
res=dict(item)
for i in range(0, 20) :
com = res['text'][i]
# print(com)
self.filename.write(com+'\n')
print('完成当前页面。。。')
# self.file.write(line.encode('utf-8')+'\n')
def close_spider(self, spider):
self.filename.close()
主要是打开文件,写入文件,关闭文件,
这里有一个问题,就是乱码问题,在写入文件的时候,必须指定写入文件的编码方式utf-8,不指定编码的话,写入的文件会出现乱码。
- 把各个文件都编写完成之后,就可以开始运行爬虫
在cmd命令行下使用scrapy crawl tiebaspider
(二) 从指定的txt文本读取内容,生成词云
爬虫爬取数据存储在指定路径下,之后就可以生成词云,生成的词云有两种表现方式,一种是正正方方的词云,一种以某个图片为背景的词云。
生成的词云可以进行多种个性化的设定,根据wordcloud库的源码:
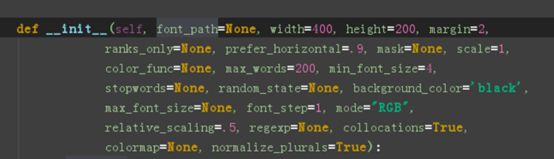
可以设定比如长宽,词云的最多单词数量,背景,字体大小,字体格式,颜色,等等属性,这里一切从简,能默认的全部默认,
核心代码:
def GetWordCloud():
path_txt = 'C://D/Python/scrapyDemo/tieba/test.txt'
path_img = "C://D/Python/PythonDemo/2.png"#
f = open(path_txt, 'r', encoding='UTF-8').read()
background_image = np.array(Image.open(path_img))
# 结巴分词,生成字符串,如果不通过分词,无法直接生成正确的中文词云,感兴趣的朋友可以去查一下,有多种分词模式
#Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
cut_text = " ".join(jieba.cut(f))
wordcloud = WordCloud(
# 设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
background_color="black",
# mask参数=图片背景,必须要写上,另外有mask参数再设定宽高是无效的
mask=background_image).generate(cut_text)
# 生成颜色值
image_colors = ImageColorGenerator(background_image)
# 下面代码表示显示图片
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
plt.show()
大体流程就是:
- wordcloud 制作词云时,首先要对对文本数据进行分词,使用 process_text()方法,这一步的主要任务是去除停用词
- 第二步是计算每个词在文本中出现的频率,生成一个哈希表。词频用于确定一个词的重要性
- 根据词频的数值按比例生成一个图片的布局,类 IntegralOccupancyMap 是该词云的算法所在,是词云的数据可视化方式的核心。生成词的颜色、位置、方向等
- 最后将词按对应的词频在词云布局图上生成图片,核心方法是 generate_from_frequencies, 不论是 generate()还是 generate_from_text()都最终用到 generate_from_frequencies
- 完成词云上各词的着色, 默认是随机着色
(三) 从指定的txt文本读取内容,生成情感趋向折线图
绘制完成词云之后,我们在此读入文本,来绘制情感趋势折线图。在这里使用的是snownlp,SnowNLP 是国人开发的 python 类库,可以方便的处理中文文本内容,是受到了 TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和 TextBlob 不同的是,这里没有用 NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。
注意本程序都是处理的 unicode 编码,所以使用时请自行 decode 成 unicode。
核心代码如下:
txt = open('C://D/Python/scrapyDemo/tieba/test.txt','r', encoding='UTF-8')
text = txt.readlines()
n = 0#获取文本行数
for num in text :
n = n +1
txt.close()
print('读入成功', '共读入'+str(n)+'行')
sentences = []
senti_score = []
for i in text:
a1 = SnowNLP(i)
a2 = a1.sentiments
sentences.append(i) # 语序...
senti_score.append(a2)
print('doing')
table = pd.DataFrame(sentences, senti_score)
# table.to_excel('F:/_analyse_Emotion.xlsx', sheet_name='Sheet1')
# ts = pd.Series(sentences, senti_score)
# ts = ts.cumsum()
# print(table)
x = []
for i in range(1, n+1) :
x.append(i)
pl.mpl.rcParams['font.sans-serif'] = ['SimHei']
pl.plot(x, senti_score)
pl.title(u'明日之后')
pl.xlabel(u'评 论 用 户')
pl.ylabel(u'情 感 程 度')
pl.show()
分析:
得到文本文件,获取文本行数作为文件的横坐标,纵坐标从0-1,0代表最差,1代表最好,使用训练好的语料库分析文本,得到每一行的喜好程度,绘制折线图。
四、效果展示以及不足之处
- 先爬100页数据
- 先开始运行爬虫:
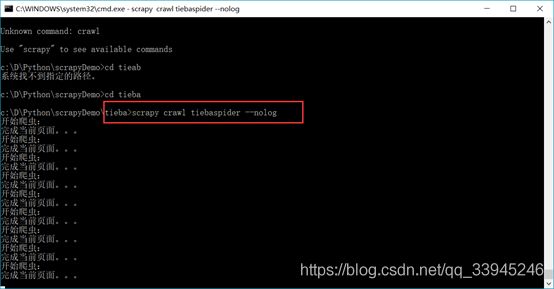
- 得到一个test.txt
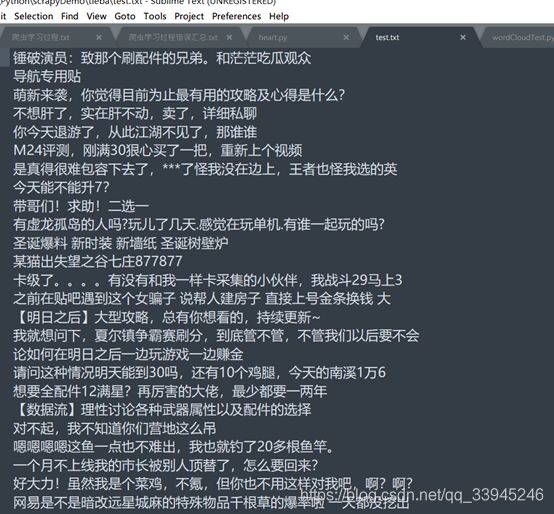
- 然后在cmd命令行运行python wordCloudTest.py,就可以得到一个词云图,如下

关键字:明日之后、营地、大佬、森林、希望、秋日、同居、锦鲤、配件
根据这些词汇,可以大体得到,明日之后的那些玩法比较受关注,比如营地,建筑同居、钓鱼以及武器配件这几个元素很受关注。 - 接下来在看看情感趋势图:
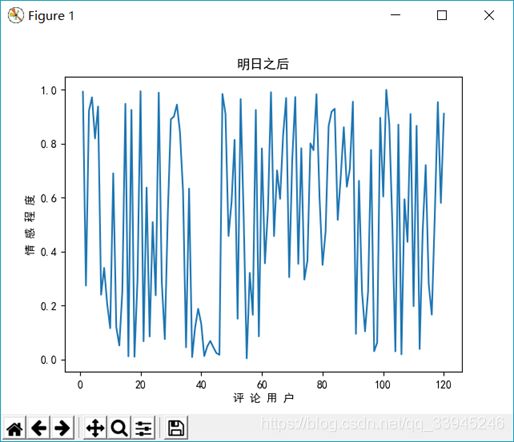
以0.5为界,可以看出来褒贬不一,但是整体是好评要多一点的。
说完效果,再说说本次设计的不足之处,在进行情感分析的时候,选择的snownlp的库文件,使用的分词和语料库是已经训练好的,但是这个库设计之初是用来分析评论的,贴吧的内容还是跟评论有一些差别,如果想要达到更好的效果,应该自己单独训练,这样的效果会更好,同时情感分析的是折线图,x轴会显示出每一个数据的感情趋向,当数据量足够大的时候,显示会有问题。