深度学习之GRU网络
1、GRU概述
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
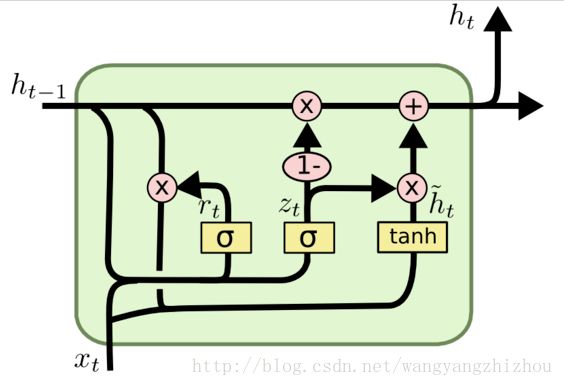
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h~th~t 上,重置门越小,前一状态的信息被写入的越少。
2、GRU前向传播
根据上面的GRU的模型图,我们来看看网络的前向传播公式:
![]()
![]()
![]()
![]()
![]()
其中[]表示两个向量相连,*表示矩阵的乘积。
3、GRU的训练过程
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来:
![]()
![]()
![]()
输出层的输入:
![]()
输出层的输出:
![]()
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:
![]()
则单个样本的在所有时刻的损失为:
![]()
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):
![]()
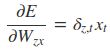
![]()
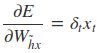
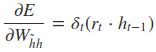
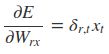
![]()
其中各中间参数为:
![]()
![]()
![]()
![]()
![]()
在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
概括来说,LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还是得看具体的应用场景。
参考文献:
GRU神经网络
GRU与LSTM总结
LSTM 和GRU的区别
先给出一些结论:
GRU和LSTM的性能在很多任务上不分伯仲。
GRU 参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将hidden state 传给下一个单元,而LSTM则用memory cell 把hidden state 包装起来。
1. 基本结构
1.1 GRU
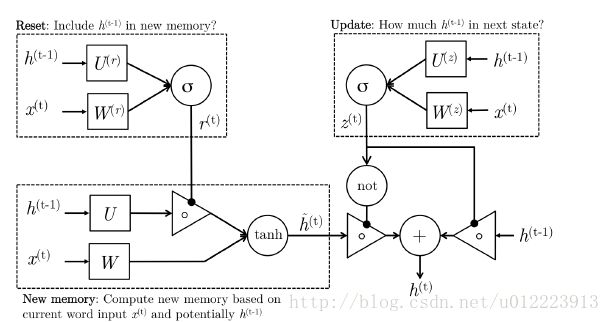
GRU的设计是为了更好的捕捉long-term dependencies。我们先来看看输入ht−1ht−1和x(t)x(t), GRU怎么通过计算输出h(t)h(t):
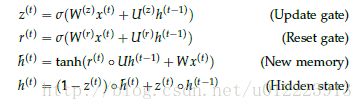
Reset gate
r(t)r(t) 负责决定h(t−1)h(t−1) 对new memory h^(t)h^(t) 的重要性有多大, 如果r(t)r(t) 约等于0 的话,h(t−1)h(t−1) 就不会传递给new memory h^(t)h^(t)
new memory
h^(t)h^(t) 是对新的输入x(t)x(t) 和上一时刻的hidden state h(t−1)h(t−1) 的总结。计算总结出的新的向量h^(t)h^(t) 包含上文信息和新的输入x(t)x(t).
Update gate
z(t)z(t) 负责决定传递多少ht−1ht−1给htht 。 如果z(t)z(t) 约等于1的话,ht−1ht−1 几乎会直接复制给htht ,相反,如果z(t)z(t) 约等于0, new memory h^(t)h^(t) 直接传递给htht.
Hidden state:
h(t)h(t) 由 h(t−1)h(t−1) 和h^(t)h^(t) 相加得到,两者的权重由update gate z(t)z(t) 控制。
1.2 LSTM
LSTM 的设计也是为了更好的捕捉long-term dependencies,但是结构上有一些不同,更复杂一些,我们想来看看计算过程:
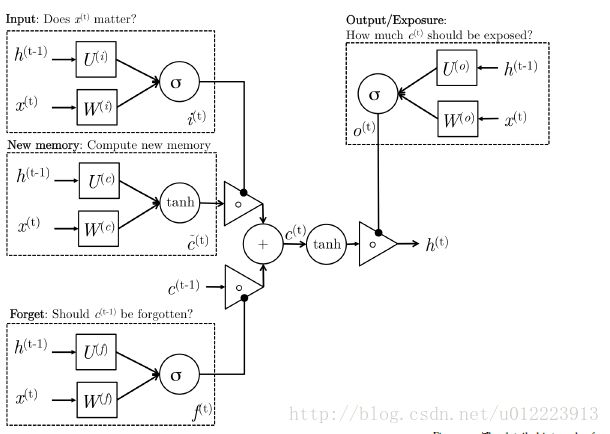

new memory cell
这一步和GRU中的new memory类似,输出的向量c^(t)c^(t)都是对新的输入x(t)x(t) 和上一时刻的hidden state h(t−1)h(t−1) 的总结。
Input gate
i(t)i(t)负责决定输入的x(t)x(t) 信息是否值得保存。
Forget gate
f(t)f(t)负责决定past memory cell c^(t−1)c^(t−1)对c(t)c(t) 的重要性。
final memory cell
c(t)c(t) 由c^(t−1)c^(t−1) 和c^(t)c^(t) 相加得到,权重分别由 Forget gate 和Input gate 决定
Output gate
这个门是GRU没有的。它负责决定c(t)c(t) 中的哪些部分应该传递给hidden state h(t)h(t)
2. 区别
1. 对memory 的控制
LSTM: 用output gate 控制,传输给下一个unit
GRU:直接传递给下一个unit,不做任何控制
2. input gate 和reset gate 作用位置不同
LSTM: 计算new memory c^(t)c^(t)时 不对上一时刻的信息做任何控制,而是用forget gate 独立的实现这一点
GRU: 计算new memory h^(t)h^(t) 时利用reset gate 对上一时刻的信息 进行控制。
3. 相似
最大的相似之处就是, 在从t 到 t-1 的更新时都引入了加法。
这个加法的好处在于能防止梯度弥散,因此LSTM和GRU都比一般的RNN效果更好。
Reference:
1. https://cs224d.stanford.edu/lecture_notes/LectureNotes4.pdf
2. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
3. https://feature.engineering/difference-between-lstm-and-gru-for-rnns/
---------------------
原文:https://blog.csdn.net/u012223913/article/details/77724621
https://www.cnblogs.com/jiangxinyang/p/9376021.html