MobileNetV3网络深入解析与Pytorch实现
Table of Contents
正文
网络结构优化
网络结构
MobileNetV3 block
MobileNetV3-Large
MobileNetV3-Small
MobileNetV3实现
block
MobileNetV3-Large
MobileNetV3-Small
论文名:Searching for MobileNetV3
论文地址:https://arxiv.org/pdf/1905.02244.pdf
正文
MobileNetV3是Google继MobileNet V1,V2之后的又一个应用于移动端的轻量级网络,V3结合了V1的depthwise separable convolutions(详情移步MobileNetV1),V2的inverted residual with linear bottleneck(详情移步MobileNetV2)和SE结构(详情请移步SENet),并通过结合硬件感知网络架构搜索(NAS)和NetAdapt算法对网络结构进行了优化,性能优于前两个网络.
网络结构优化
我对NAS和NetAdapt不了解,同时也感觉自动搜索得到的网络架构不属于人力范畴,我就只说明一下网络结构优化的点,方便大家在自己实现网络时参考.
1.在之前的网络设计中,最后都会采用一个1*1卷积来提高输出特征图数量(960->1280),为了提速,V3将1*1卷积放在average pooling之后,如下图所示
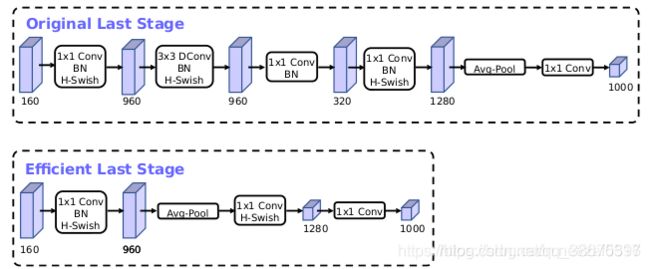
2.在初使结构中,通常输出的是32维通道(3->32),这里输出16维通道,并使用hswish替代relu
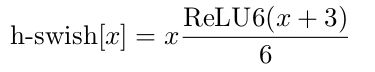
3.使用h-sigmoid(将h-swish表达式中的x去掉),用来替换SE结构中的sigmoid,并设定SE结构压缩系数为4
网络结构
MobileNetV3 block
MobileNetV3 block在MobileNetV2的基础上增加了SE结构,如下图所示

MobileNetV3-Large

MobileNetV3-Small

MobileNetV3实现
block
class hswish(nn.Module):
def __init__(self):
super().__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x*self.relu6(x+3)/6
return out
class hsigmoid(nn.Module):
def __init__(self):
super().__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x+3)/6
return out
class SE(nn.Module):
def __init__(self, in_channels, reduce=4):
super().__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels//reduce, 1, bias=False),
nn.BatchNorm2d(in_channels//reduce),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels // reduce, in_channels, 1, bias=False),
nn.BatchNorm2d(in_channels),
hsigmoid()
)
def forward(self, x):
out = self.se(x)
out = x*out
return out
class Block(nn.Module):
def __init__(self, kernel_size, in_channels, expand_size, out_channels, stride, se=False, nolinear='RE'):
super().__init__()
self.se = nn.Sequential()
if se:
self.se = SE(expand_size)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.block = nn.Sequential(
nn.Conv2d(in_channels, expand_size, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(expand_size),
self.nolinear,
nn.Conv2d(expand_size, expand_size, kernel_size, stride=stride,
padding=kernel_size // 2, groups=expand_size, bias=False),
nn.BatchNorm2d(expand_size),
self.se,
self.nolinear,
nn.Conv2d(expand_size, out_channels, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.block(x)
if self.stride == 1:
out += self.shortcut(x)
return outMobileNetV3-Large
class MobileNetV3_Large(nn.Module):
def __init__(self, class_num=settings.CLASSES_NUM):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
hswish()
)
self.neck = nn.Sequential(
Block(3, 16, 16, 16, 1),
Block(3, 16, 64, 24, 2),
Block(3, 24, 72, 24, 1),
Block(5, 24, 72, 40, 2, se=True),
Block(5, 40, 120, 40, 1, se=True),
Block(5, 40, 120, 40, 1, se=True),
Block(3, 40, 240, 80, 2, nolinear='HS'),
Block(3, 80, 200, 80, 1, nolinear='HS'),
Block(3, 80, 184, 80, 1, nolinear='HS'),
Block(3, 80, 184, 80, 1, nolinear='HS'),
Block(3, 80, 480, 112, 1, se=True, nolinear='HS'),
Block(3, 112, 672, 112, 1, se=True, nolinear='HS'),
Block(5, 112, 672, 160, 2, se=True, nolinear='HS'),
Block(5, 160, 960, 160, 1, se=True, nolinear='HS'),
Block(5, 160, 960, 160, 1, se=True, nolinear='HS'),
)
self.conv2 = nn.Sequential(
nn.Conv2d(160, 960, 1, bias=False),
nn.BatchNorm2d(960),
hswish()
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.conv3 = nn.Sequential(
nn.Conv2d(960, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
hswish()
)
self.conv4 = nn.Conv2d(1280, class_num, 1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.flatten(1)
return xMobileNetV3-Small
class MobileNetV3_Small(nn.Module):
def __init__(self, class_num=settings.CLASSES_NUM):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
hswish()
)
self.neck = nn.Sequential(
Block(3, 16, 16, 16, 2, se=True),
Block(3, 16, 72, 24, 2),
Block(3, 24, 88, 24, 1),
Block(5, 24, 96, 40, 2, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 120, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 144, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 288, 96, 2, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
)
self.conv2 = nn.Sequential(
nn.Conv2d(96, 576, 1, bias=False),
nn.BatchNorm2d(576),
hswish()
)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.conv3 = nn.Sequential(
nn.Conv2d(576, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
hswish()
)
self.conv4 = nn.Conv2d(1280, class_num, 1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.flatten(1)
return x