pytorch实现FCN8s、PSPnet、deeplab3+、Unet等语义分割模型
文章目录
- 训练集(voc2012)
- 训练模型
- 配置环境
- 运行train.py文件
- 测试
训练集(voc2012)
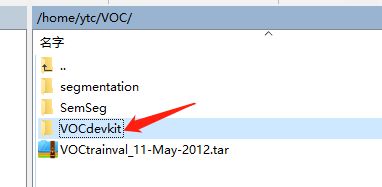
本文使用的训练集为voc2012官方上下载的数据集,有5个文件夹,我们需要的文件只有三个具体如下图:
仔细观察sementationObject文件夹,你会发现此文件夹有2913张.png图,而JPEGImages文件夹中却有3万多张图,这是因为voc数据集只有部分用作语义分割任务,其他任务用来做别的计算机视觉任务,为了防止显存不够,我们将文件夹中的其他图片删除,仅留2913张语义分割图片,具体代码如下:
for i in set(image_files) - set(files):
os.remove('./data/dataset/JPEGImages/' + i + '.jpg')
for i in set(label_files) - set(files):
os.remove('./data/dataset/gtFine/' + i + '.png')
如果内存足够,可以不做处理,具体视情况决定。
注:voc数据集有20类,另外还有个0(黑色)作为背景,255(白色)作为空
训练模型
本文所使用的所有模型github代码地址: https://github.com/yassouali/pytorch_segmentation
这个git中提供了Deeplab V3+、U-Net、FCN、PSPNet等常用语义分割模的pytorch实现,上手容易,模型切换简单,非常适合做研究
配置环境
1、安装anaconda
2、pip install torch1.1.0
pip install torchvision0.3.0
pip install tqdm4.32.2
pip install tensorboard1.14.0
pip install Pillow6.0.0
pip install opencv-python4.1.0.25
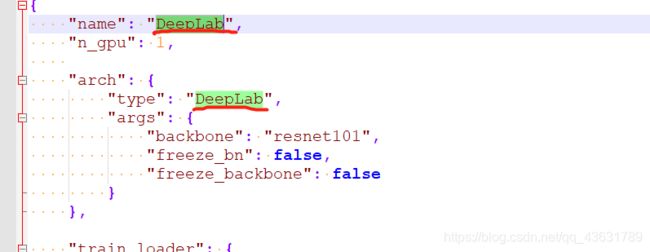
3、替换git中的config.json文件,操作如下
{
"name": "DeepLab",
"n_gpu": 1,
"arch": {
"type": "DeepLab",
"args": {
"backbone": "resnet101",
"freeze_bn": false,
"freeze_backbone": false
}
},
"train_loader": {
"type": "VOC",
"args":{
"data_dir": "/home/ytc/VOC",
"batch_size":16,
"base_size": 400,
"crop_size": 380,
"augment": true,
"shuffle": true,
"scale": true,
"flip": true,
"rotate": true,
"blur": false,
"split": "train",
"num_workers": 8
}
},
"val_loader": {
"type": "VOC",
"args":{
"data_dir": "/home/ytc/VOC",
"batch_size": 16,
"crop_size": 480,
"val": true,
"split": "val",
"num_workers": 8
}
},
"optimizer": {
"type": "SGD",
"differential_lr": true,
"args":{
"lr": 0.01,
"weight_decay": 1e-4,
"momentum": 0.9
}
},
"loss": "CrossEntropyLoss2d",
"ignore_index": 255,
"lr_scheduler": {
"type": "Poly",
"args": {}
},
"trainer": {
"epochs": 200,
"save_dir": "saved/",
"save_period": 5,
"monitor": "max Mean_IoU",
"early_stop": 10,
"tensorboard": true,
"log_dir": "saved/runs",
"log_per_iter": 20,
"val": true,
"val_per_epochs": 5
}
}
记得更改路径,写到这个文件夹的父目录
其他不用改动,此时batchsize是16,跑的模型是DeepLab,如果报了显存错误,就把batchsize调小点。可以换的模型有:FCN8,UNet,SegNet,SegResNet,ENet,GCN,DeepLab,DeepLab_DUC_HDC,UperNet,PSPNet,PSPDenseNet。换模型需要修改config.json中的tpye,模型的名称在_init_.py中

运行train.py文件
python train.py --config config.json
测试
先创个文件夹叫 testImages,挑几张jpg格式的的用来测试的图片,复制进这个文件夹里
然后:
python inference.py --config config.json --model saved/DeepLab/09-30_16-22/checkpoint-epoch140.pth --images ./images
例如:python inference.py --config config.json --model E:\gao\1\pytorch_segmentation-master\saved\PSPNet\10-22_13-07epoch140.pth\best_model.pth --images E:\gao\1\pytorch_segmentation-master\testImages
然后他会生成一个叫 output的文件夹,里面就是标注完的png的图,打开 output文件夹,输出结果在那个里面。
inference.py (需要替换)如下
import argparse
import scipy
import os
import numpy as np
import json
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from scipy import ndimage
from tqdm import tqdm
from math import ceil
from glob import glob
from PIL import Image
import dataloaders
import models
from utils.helpers import colorize_mask
def pad_image(img, target_size):
rows_to_pad = max(target_size[0] - img.shape[2], 0)
cols_to_pad = max(target_size[1] - img.shape[3], 0)
padded_img = F.pad(img, (0, cols_to_pad, 0, rows_to_pad), "constant", 0)
return padded_img
def sliding_predict(model, image, num_classes, flip=True):
image_size = image.shape
tile_size = (int(image_size[2]//2.5), int(image_size[3]//2.5))
overlap = 1/3
stride = ceil(tile_size[0] * (1 - overlap))
num_rows = int(ceil((image_size[2] - tile_size[0]) / stride) + 1)
num_cols = int(ceil((image_size[3] - tile_size[1]) / stride) + 1)
total_predictions = np.zeros((num_classes, image_size[2], image_size[3]))
count_predictions = np.zeros((image_size[2], image_size[3]))
tile_counter = 0
for row in range(num_rows):
for col in range(num_cols):
x_min, y_min = int(col * stride), int(row * stride)
x_max = min(x_min + tile_size[1], image_size[3])
y_max = min(y_min + tile_size[0], image_size[2])
img = image[:, :, y_min:y_max, x_min:x_max]
padded_img = pad_image(img, tile_size)
tile_counter += 1
padded_prediction = model(padded_img)
if flip:
fliped_img = padded_img.flip(-1)
fliped_predictions = model(padded_img.flip(-1))
padded_prediction = 0.5 * (fliped_predictions.flip(-1) + padded_prediction)
predictions = padded_prediction[:, :, :img.shape[2], :img.shape[3]]
count_predictions[y_min:y_max, x_min:x_max] += 1
total_predictions[:, y_min:y_max, x_min:x_max] += predictions.data.cpu().numpy().squeeze(0)
total_predictions /= count_predictions
return total_predictions
def multi_scale_predict(model, image, scales, num_classes, device, flip=False):
input_size = (image.size(2), image.size(3))
upsample = nn.Upsample(size=input_size, mode='bilinear', align_corners=True)
total_predictions = np.zeros((num_classes, image.size(2), image.size(3)))
image = image.data.data.cpu().numpy()
for scale in scales:
scaled_img = ndimage.zoom(image, (1.0, 1.0, float(scale), float(scale)), order=1, prefilter=False)
scaled_img = torch.from_numpy(scaled_img).to(device)
scaled_prediction = upsample(model(scaled_img).cpu())
if flip:
fliped_img = scaled_img.flip(-1).to(device)
fliped_predictions = upsample(model(fliped_img).cpu())
scaled_prediction = 0.5 * (fliped_predictions.flip(-1) + scaled_prediction)
total_predictions += scaled_prediction.data.cpu().numpy().squeeze(0)
total_predictions /= len(scales)
return total_predictions
def save_images(image, mask, output_path, image_file, palette, mode):
# Saves the image, the model output and the results after the post processing
w, h = image.size
image_file = os.path.basename(image_file).split('.')[0]
colorized_mask = colorize_mask(mask, palette)
if mode == 'maskOnly':
colorized_mask.save(os.path.join(output_path, image_file+'.png'))
return
elif mode == 'origin&mask':
output_im = Image.new('RGB', (w*2, h))
output_im.paste(image, (0,0))
output_im.paste(colorized_mask, (w,0))
output_im.save(os.path.join(output_path, image_file+'.png'))
return
elif mode == 'all':
combination = Image.blend(image.convert('RGBA'), colorized_mask.convert('RGBA'), 0.6)
masked = Image.new('RGB', (w*3, h))
masked.paste(image, (0,0))
masked.paste(colorized_mask, (w,0))
masked.paste(combination, (w*2,0))
masked.save(os.path.join(output_path, image_file+'.png'))
else:
raise Exception("Invalid output mode!")
def main():
args = parse_arguments()
config = json.load(open(args.config))
# Dataset used for training the model
dataset_type = config['train_loader']['type']
assert dataset_type in ['VOC', 'COCO', 'CityScapes', 'ADE20K']
if dataset_type == 'CityScapes':
scales = [0.75, 1.0, 1.25, 1.5, 1.75, 2.0, 2.25]
else:
scales = [0.75, 1.0, 1.25, 1.5, 1.75, 2.0]
loader = getattr(dataloaders, config['train_loader']['type'])(**config['train_loader']['args'])
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize(loader.MEAN, loader.STD)
num_classes = loader.dataset.num_classes
palette = loader.dataset.palette
# Model
model = getattr(models, config['arch']['type'])(num_classes, **config['arch']['args'])
availble_gpus = list(range(torch.cuda.device_count()))
device = torch.device('cuda:0' if len(availble_gpus) > 0 else 'cpu')
checkpoint = torch.load(args.model)
if isinstance(checkpoint, dict) and 'state_dict' in checkpoint.keys():
checkpoint = checkpoint['state_dict']
if 'module' in list(checkpoint.keys())[0] and not isinstance(model, torch.nn.DataParallel):
model = torch.nn.DataParallel(model)
model.load_state_dict(checkpoint)
model.to(device)
model.eval()
if not os.path.exists('outputs'):
os.makedirs('outputs')
image_files = sorted(glob(os.path.join(args.images, f'*.{args.extension}')))
with torch.no_grad():
tbar = tqdm(image_files, ncols=100)
for img_file in tbar:
image = Image.open(img_file).convert('RGB')
input = normalize(to_tensor(image)).unsqueeze(0)
if args.mode == 'multiscale':
prediction = multi_scale_predict(model, input, scales, num_classes, device)
elif args.mode == 'sliding':
prediction = sliding_predict(model, input, num_classes)
else:
prediction = model(input.to(device))
prediction = prediction.squeeze(0).cpu().numpy()
prediction = F.softmax(torch.from_numpy(prediction), dim=0).argmax(0).cpu().numpy()
save_images(image, prediction, args.output, img_file, palette, args.outputMode)
def parse_arguments():
parser = argparse.ArgumentParser(description='Inference')
parser.add_argument('-c', '--config', default='VOC',type=str,
help='The config used to train the model')
parser.add_argument('-mo', '--mode', default='multiscale', type=str,
help='Mode used for prediction: either [multiscale, sliding]')
parser.add_argument('-m', '--model', default='model_weights.pth', type=str,
help='Path to the .pth model checkpoint to be used in the prediction')
parser.add_argument('-i', '--images', default=None, type=str,
help='Path to the images to be segmented')
parser.add_argument('-o', '--output', default='outputs', type=str,
help='Output Path')
parser.add_argument('-e', '--extension', default='jpg', type=str,
help='The extension of the images to be segmented')
parser.add_argument('-om', '--outputMode', default='all', type=str,
help='The mode of output images. [maskOnly, origin&mask, all]')
args = parser.parse_args()
return args
if __name__ == '__main__':
main()
测试结果如下:
运行中遇到的问题补充:
1、torch与tensorboard版本不一致,我把tensor注释掉了

2、类型转换错误

修改:
![]()
划线那句改成:np.array(label).astype(int)