金融现金贷用户数据分析和用户画像
金融现金贷用户数据分析和用户画像 博主录制:http://dwz.date/b62E

讲师介绍
讲师Toby,持牌照消费金融模型专家,和中科院,中科大教授保持长期项目合作;和同盾,聚信立等外部数据源公司有项目对接。熟悉消费金融场景业务,线上线下业务,包括现金贷,商品贷,医美,反欺诈,汽车金融等等。模型项目200+,擅长Python机器学习建模,对于变量筛选,衍生变量构造,变量缺失率高,正负样本不平衡,共线性高,多算法比较,调参等疑难问题有良好解决方法。
课程概述
此课程用python代码对LendingClub平台贷款数据分析和用户画像,针对银行,消费金融,现金贷等场景,教会学员用python实现金融信贷申请用户数据分析。项目采用lendingclub 12万多条真实信贷数据,包括用户年收入,贷款总额,分期金额,分期数量,职称,住房情况等几十个维度。通过课程学习,我们发现2019年四季度时候,美国多头借贷情况非常严重,为全球系统性金融危机埋下种子。
课程目录
章节1python编程环境搭建
课时1.金融现金贷用户数据分析和画像_介绍视频
课时2.Anaconda快速入门指南
课时3.Anaconda下载安装
课时4.python第三方包安装(pip和conda install)
章节2金融现金贷用户数据分析和画像
课时5.描述性统计-知己知彼百战百胜
课时6.好坏客户占比严重失衡
课时7不要用相关性分析杀人
课时8变量相关性分析-你不知道的秘密
课时9贷款金额和趋势分析-2018年Q4信贷略有缩紧
课时10产品周期分析-看来lendingclub是短周期借贷平台
课时11用户工龄分析-10年工龄用户最多
课时12年收入分析-很多美国人年薪5万美金左右
课时13住房情况与贷款等级-原来美国大部分都是房奴
课时14贷款人收入水平_贷款等级_收入核实多因子分析
课时15贷款用途-美国金融危机浮出水面
课程部分内容展示
Lending Club公司背景
Lending Club 创立于2006年,主营业务是为市场提供P2P贷款的平台中介服务,公司总部位于旧金山。
公司在运营初期仅提供个人贷款服务,至2012年平台贷款总额达10亿美元规模。
2014年12月,Lending Club在纽交所上市,成为当年最大的科技股IPO。
2014年后公司开始为小企业提供商业贷款服务。
2015年全年Lending Club平台新设贷款金额达到了83.6亿美元。
2016年上半年Lending club爆出违规放贷丑闻,创始人离职,股价持续下跌,全年亏损额达1.46亿美元。
2019-2020年公司业务被迫转型,可能和美国高负债率,用户违约率上升有关。
作为P2P界的鼻祖,Lending club跌宕起伏的发展历史还是挺吸引人的。
此处介绍一下什么是P2P。概括起来可以这样理解,“所有不涉及传统银行做媒介的信贷行为都是P2P”。简单点来说,P2P公司不会出借自有资金,而是充当“中间人”的角色,连接借款人与出借人需求。
借款人高兴的是拿到了贷款,而且过程快速便利,免遭传统银行手续众多的折磨;出借人高兴的是借出资金的投资回报远高于存款利率;那么中间人高兴的是用服务换到了流水(拿的便是事成之后的抽成) 最后实现三赢。
P2P初衷是好的,但随着诸多平台建立蓄水池,违规操作和房贷,造成几十万人被骗。2018-2019年国内对P2P监管越来越严,到了2020年,P2P基本清退。只有持牌照的公司才能放贷。
贷款标准
借款人提交申请后,Lending Club 会根据贷款标准进行初步审查。贷款人需要满足以下标准才能借款:
1.FICO 分数在660 分以上

FICO分数等级划分
2.债务收入比例低于40%
3.信用报告反应以下情况:至少有两个循环账户正在使用,最近6 个月不超过5 次被调查,至少36 个月的信用记录
贷款等级grade
贷款分为A、B、C、D、E、F、G 7 个等级,每个等级又包含了1、2、3、4、5 五个子级。
二、目的
研究影响贷款等级的相关因素,并探寻潜藏在数据背后的一些规律
三、数据集获取
选取2018年第四季度数据集以及特征变量的说明文档。

官网上下载数据集
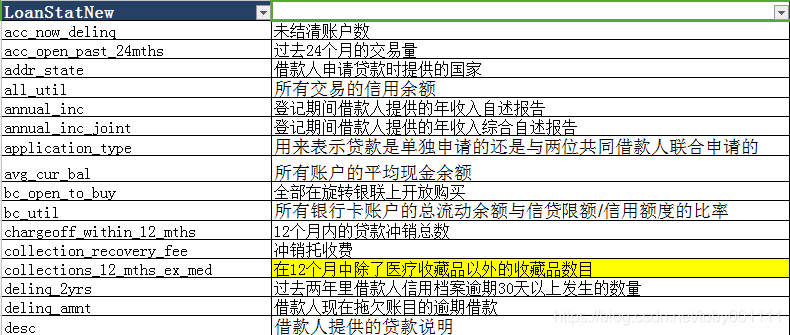
已翻译的特征说明文档
说明:部分重要的特征变量似乎缺失,多次下载的数据集中缺少fico分数、fico_range_low、fico_range_high等与fico相关的特征,所以在形成结论进行总结的时候,这些特征的结论将从相关的报告中获取。
四、数据处理
在对数据进行处理前,我们需要对数据有一个整体的认识

从上述的信息中可以看出:
1.128412行数据,23个特征变量(抽选比较重要的变量,原始变量有110多个)
2.13个特征变量中有86个是浮点数类型,5个是Object对象。
调用data.describe()函数对数据描述性统计,观察各个变量的计数,平均值,标准差,最大值,最小值,1/4位数和3/4位数值,并观察一下异常值。

Object基类对象的数据分布情况
从图表中可以得到部分信息:
1.贷款共7个等级,占比最多的是B级
2.还款的形式有两种,占比最多的是36个月
3.贷款人中大多数人工龄10+年
4.贷款人的房屋状况大多是抵押贷款
5.大多数人贷款的目的是债务整合
6.id与desc特征的数据缺失率高达0.99,间接表明这两个特征可以删除掉。
同样可以按照这种方式对浮点型的数据进行数据预览,得到均值、标准差、四分位数以及数据的缺失比重等信息。
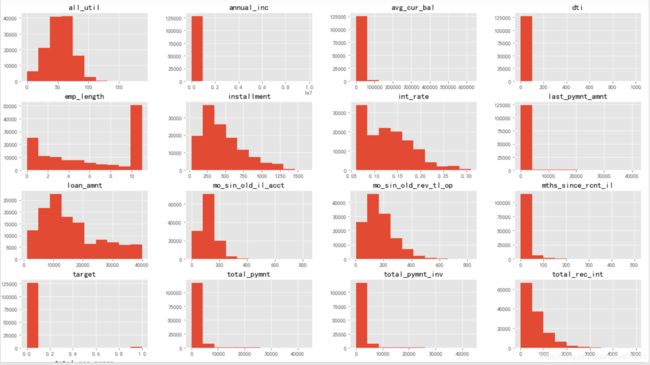
我们调用hist函数可以对数据的所有维度绘制直方图,一目了然观察所有变量数据分布。
第四季度贷款等级变化趋势
首先我们来看一下2018年第四季度业务开展情况,主要是放款笔数,金额,期限等情况。第四季度放款笔数和放款金额略有下降,业务上是有意义的,年底坏账率会上升,平台会收紧。特别是在国内,年底收紧幅度比较大。

贷款金额分析:
通过seaborn,scipy,pandas三个包,我们绘制了一个正太分布图,观察lendingclub平台给个人贷款金额大多在1万-2万美金,较高金额的贷款数量较少,此平台主要是小额贷为主。

贷款周期占比
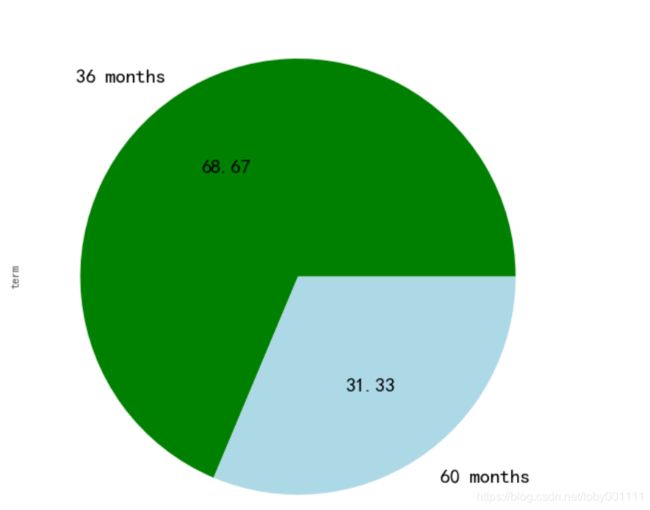
通过绘制饼状图,我们得到lendingclub平台贷款周期分为36个月与60个月,主要以36个月为主,60个月的比重31%左右。在p2p平台上以短期贷款为主,长期贷款也有,利率较高,但周期较长。借出人收获利息,承担风险,而借入人到期要偿还本金。贷款周期越长,对借出人来说风险越高。
在国内的环境下,借出人不仅要承担推迟还款的风险,还要担心平台跑路、本息全无的高风险;对借入人来说,因为国内缺少健全的征信体系,借款方违约及重复违约成本低。
对国内的情况不再多说,话题绕回来。国外的部分国家已有健全的征信体系,一旦违约还款,违约率不断上涨,个人征信也会保留记录,对后序的贷款、买房有很大的影响。所以如果贷款周期较长,且如果没有固定的工作和固定的收入的话(即使有未定收入也不一定如期偿还),偿还本金充满变数,很有可能违约。
接下来我们再试着对贷款人进行分析,形成一下用户画像吧。
贷款人工龄分布图

从图中可以看出,贷款人中工龄为10年以上频率最多。那么,我们可以考虑一下,为什么工龄超过10年的人有贷款需求呢?且占比这么高?
那么可以猜测一下(个人意见),首先可能是工龄越长,贷款通过率越高(筛选后占比较高),这可能和lendingclub贷前审批策略有关。
贷款人收入水平

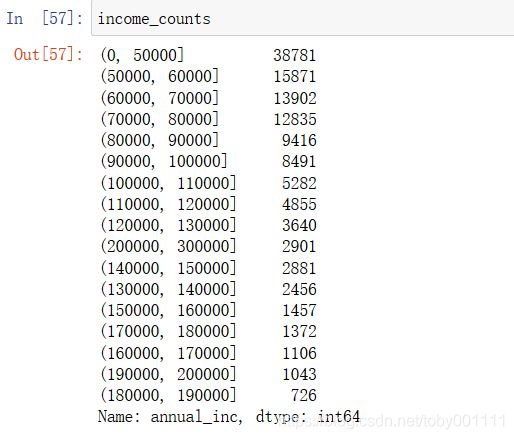
通过上图发现,美国贷款人收入水平中年收入在0-5万美元的占比最高,30.53%左右。其次是5万-10万区间,11万-30万年收入区间占比逐步变小。得到这张图并不容易,是对数据进行深度清洗后得到的。特别是调用了pandas的cut函数,对收入变量进行分箱处理。
贷款人年收入,贷款等级,收入验证多因子分析

lending club会对客户收入进行验证,这非常值得国内平台学习。贷款人的收入水平信息分为三种情况:已经过LC验证,收入来源已验证,未验证。这三种情况目前从图中看出LC验证,收入来源已验证,未验证的收入数据还是有显著区别。另外贷款等级与收入水平在整体上呈正相关的趋势。上图由seaborn的的factorplot函数生成。factorplot函数是用于多因子分析的,非常实用。
借款人住房状况分布图

一半用户房屋状态是抵押贷款,只有10%用户拥有完全的产权。看来美国房奴大军不小呀!接着用pandas的stack和unstack函数对grade和home_ownship两个等级变量做数据深度清洗,然后绘制下图。通过观察贷款等级越高用户按揭占比越高,租房占比越低,反之亦然。自有住房占比每个等级略有不同。

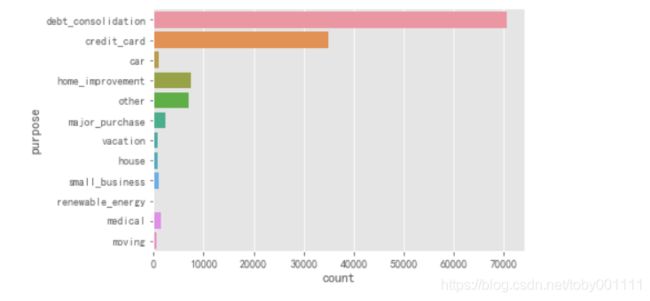
上图中debt_consolidation(可以理解为债务整合,借新还旧)占比最高,占比第二高的credit_card也归属为同一类。不同平台新债还旧债属于多头借贷行为,多头借贷会提升用户负债率,而负债率会引发经济系统性危机。经济危机会进一步提高社会基尼系数,引发社会动荡。多头借贷是一个非常敏感的指标,无论公司还是地方政府都应该监控此指标。
从历史经验看,举债发展导致住户部门高杠杆和过快的债务增速,与债务危机显著相关。如日本平成大萧条,韩国信用卡危机,美国次贷危机,均是居民负责短期内快速上涨,导致收入,储蓄及资产价值无法偿付债务,从而造成金融系统系风险。

美国上个世纪开始就提倡超前消费观念刺激经济,传统储蓄观念备受冷漠。但人有不愿意还钱倾向,债务越高,金融危机风险越大。2019年美国债务占GDP比重已经高到106%,也就是说美国创造的社会财富还不够还债。1970年时,债务只占GDP38%左右,由此可见华尔街贪欲程度,可以用too much, never enough来形容。很巧的是,我们在lending club数据分析时就发现了这猫腻,发现大多借款人借款目的就是新债换旧债。无论新冠状病毒是否爆发,美国金融体系已经存在严重系统风险,而且其他国家也存在类似问题,只是负债程度不一样。
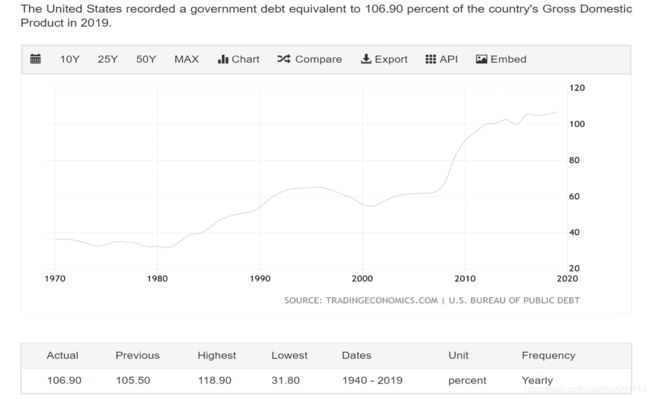
专业人士预测到2025年,美国负债占GDP比重可能达到140%,负债呈现逐年上升趋势。

居民负债率上升,富人却通过房贷和货币宽松政策获利,从而导致社会基尼系数不断上升,社会贫富差距拉大,最后导致社会动荡和战争。下图是几年前全球基尼系数,可以看到美国基尼系数在40-50,实际数据可能更大。

贷款目的与人均收入水平

综合收入水平与贷款用途得到上图,我们可以发现在第四季度中,人均收入水平较高的人群贷款用于小生意,家庭生活改善,房子等。而贷款为了债务整合(占比最高)的人群的人均收入水平在整体的中下。收入最低的一般用于医疗开支或车辆相关。这也间接证明了多头借贷的收入会越来越低,陷入贫困陷阱。
变量相关性分析:
数据分析和画像后,我们可以用上述变量建模。建模型并非所有变量都使用,需要做变量筛选工作。变量相关性分析就是最基础的变量筛选步骤。我们用seaborn的heatmap函数绘制出下图变量相关性热力图后,我们发现部分变量呈现0.9高相关性

除了python,excel也可以绘制变量相关性热力图,下图由excel生成。
变量相关性取值从0-1,值越接近0,两个变量相关性越低;值越接近1,两个变量相关性越高。下图是变量相关性数据分布。

python金融风控评分卡模型和数据分析微专业课(博主亲自录制视频):http://dwz.date/b62E