滚动轴承振动序列的预处理--CWRU数据集
试验中发现对返回数据的shape进行如下改进会更好一些:
- 对iteror_raw_data()中的返回值data维度降为1维。从而使得data_augment()部分返回值X变为二维数据,进而使得可以对X进行数据标准化
- 修改标准化部分内容
- 其余内容见我的Github
1.内容
对CWRU轴承数据集中12kDriveEndBearingFaultData进行:
- 读取指定的.mat文件;
- 标签标注和数据提取;
- 数据增强处理;
- 标准化设计;
- 对标签为"normal"的数据进行降采样;
2.读取mat文件和数据标注
这部分的思路是,通过scipy.io.loadmat 载入指定的mat文件("FE"或者“DE”数据),然后设计一个(X,y)的生成器来返回数据和数据标签;其中,X表示数据data, y是数据标签label。
import os
from scipy.io import loadmat
def iteror_raw_data(data_path,data_mark):
"""
读取.mat文件,返回数据的生成器:标签,样本数据。
:param data_path:.mat文件所在路径
:param data_mark:"FE" 或 "DE"
:return iteror:(标签,样本数据)
"""
# 标签数字编码
labels = {
"normal":0, "IR007":1, "IR014":2, "IR021":3, "OR007":4,
"OR014":5, "OR021":6, "B007":7, "B014":8, "B021":9}
# 列出所有文件
filenams = os.listdir(data_path)
# 逐个对mat文件进行打标签和数据提取
for single_mat in filenams:
single_mat_path = os.path.join(data_path, single_mat)
# 打标签
for key, _ in labels.items():
if key in single_mat:
label = labels[key]
# 数据提取
file = loadmat(single_mat_path)
for key, _ in file.items():
if data_mark in key:
#data = file[key]
data = file[key].ravel() # 2020/06/22, 降为一维
yield label, data3.数据增强处理
本部分在哈工大张伟的硕士论文《基于卷积神经网络的轴承故障诊断算法研究》的基础上进行了改进:(1)以时间长度s来度量数据的长度、滑动窗口的长度、重叠量的长度。目的是为了使程序适应不同采样频率的数据集。(2)将数据标准化设计为可选操作,这样满足对原始数据和标准化后数据的同时查看的需求,使得数据的处理更加灵活。
import numpy as np
import random
from sklearn.preprocessing import scale, StandardScaler, MinMaxScaler
from collections import Counter
def data_augment(fs, win_tlen, overlap_rate, data_iteror, **kargs):
"""
:param win_tlen: 滑动窗口的时间长度
:param overlap_rate: 重叠部分比例, [0-100],百分数;
overlap_rate*win_tlen*fs//100 是论文中的重叠量。
:param fs: 原始数据的采样频率
:param data_iteror: 原始数据的生成器格式
:param kargs: {"norm"}
norm 数据标准化的方式,三种选择:
1:"min-max";
2:"Z-score", mean = 0, std = 1;
3: sklearn中的StandardScaler;
:return (X, y): X, 切分好的数据, y数据标签
"""
overlap_rate = int(overlap_rate)
# 重合部分的时间长度,单位s
overlap_tlen = win_tlen * overlap_rate / 100
# 步长,单位s
step_tlen = win_tlen - overlap_tlen
# 滑窗采样增强数据
X = []
y = []
for iraw_data in data_iteror:
single_raw_data = iraw_data[1]
lab = iraw_data[0]
number_of_win = np.floor((len(single_raw_data) - overlap_tlen * fs)
/ (fs * step_tlen))
for iwin in range(1,int(number_of_win)+1):
# 滑窗的首尾点和其更新策略
start_id = int((iwin - 1) * fs * step_tlen + 1)
end_id = int(start_id + win_tlen * fs)
current_data = single_raw_data[start_id:end_id]
current_label = lab
X.append(current_data)
y.append(np.array(current_label))
# 转换为np数组
# X[0].shape == (win_tlen*fs,)
# X.shape == (len(X), win_tlen*fs)
X = np.array(X)
y = np.array(y)
# 这里进行了修改 2020/06/22
for key, val in kargs.items():
# 数据标准化方式选择
if key == "norm" and val == 1:
X = MinMaxScaler().fit_transform(X.T)
X = X.T
if key == "norm" and val == 2:
X = scale(X.T)
X = X.T
if key == "norm" and val == 3:
X = StandardScaler().fit_transform(X.T)
X = X.T
return X, y 4. 数据降采样
这部分程序的鲁棒性不是很好,只能适应于CWRU数据集,其他数据集上慎用。在本文所采用的数据集上,经过上述程序操作后,得到的数据有两个特征:(1)数据是按标签有序排列。(2)normal标签(0)的增强处理后数据数量是其他标签的两倍,而其他标签数据数量基本相等。
基于上述事实,所以该部分采取的降采样策略是,将增强处理后的normal标签(0)数据随机删除一半。代码如下:
def under_sample_for_c0(X, y, low_c0, high_c0, random_seed):
""" 使用非0类别数据的数目,来对0类别数据进行降采样。
:param X: 增强后的振动序列
:param y: 类别标签0-9
:param low_c0: 第一个类别0样本的索引下标
:param high_c0: 最后一个类别0样本的索引下标
:param random_seed: 随机种子
:return X,y
"""
np.random.seed(random_seed)
to_drop_ind = random.sample(range(low_c0, high_c0), (high_c0 - low_c0 + 1) - len(y[y==3]))
# 按照行删除
X = np.delete(X,to_drop_ind,0)
y = np.delete(y,to_drop_ind,0)
return X, y5. 整体处理流程
def preprocess(path, data_mark, fs, win_tlen,
overlap_rate, random_seed, **kargs):
data_iteror = iteror_raw_data(path, data_mark)
X, y = data_augment(fs, win_tlen, overlap_rate, data_iteror, **kargs)
# 降采样,随机删除类别0中一半的数据
low_c0 = np.min(np.argwhere(y==0))
high_c0 = np.max(np.argwhere(y==0))
X, y = under_sample_for_c0(X, y, low_c0, high_c0, random_seed)
print("-> 数据位置:{}".format(path))
print("-> 原始数据采样频率:{0}Hz,\n-> 数据增强和0类数据降采样后共有:{1}条,"
.format(fs, X.shape[0]))
print("-> 单个数据长度:{0}采样点,\n-> 重叠量:{1}个采样点,"
.format(X.shape[1], int(overlap_rate*win_tlen*fs // 100)) )
print("-> 类别数据数目:", sorted(Counter(y).items()))
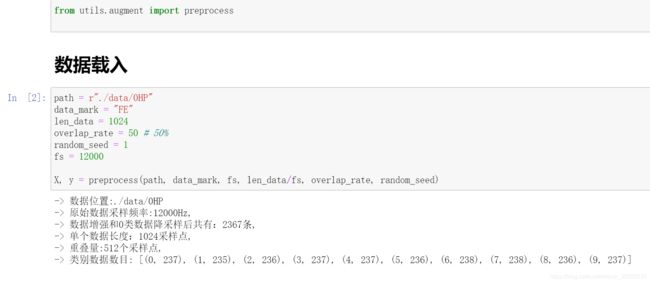
return X, y代码在jupyter notebook中调用和结果:
6. 写在最后
刚入手这个项目的时候,我从一个小白开始点滴积累和学习,网络上的资料繁多,搜集、整理、甄别、消化到最后应用到项目中,前期的过程花费了太多的时间和心力。现在回头看,常常这样想,如果当初有现成的数据处理或者是特征处理的流程和代码可供参考的话,今天这个项目应该会有更多的不一样。为了弥补这个遗憾,也为了想做这个项目的同学少走弯路,能够尽早地进入实质性的工作中,于是我将项目内容整理并分享在这里。由于受个人能力水平的限制,其中难免会有不当和错误,非常欢迎各位修改的意见,希望在彼此的交流中,大家能共同进步。附上该部分的GitHub链接。(项目没更新完全,因为有些东西还在试验中)