使用Xgboost和lightgbm实现对贷款用户逾期预测
一、背景及目标
根据提供的金融数据,分别使用xgboost和lightgbm两种算法预测贷款用户是否会逾期。
二、任务分析
- 导入数据后,首先,由于数据中存在缺失值,因此需要对缺失值数据进行预处理。
- 其次,对明显与模型无关的特征进行删除。
- 最后,分别采用xgboost和lightgbm进行模型训练,预测结果以及输出评分。
三、数据预处理
一共4754行,89列(除去首行、首列)
- 直接删除,对模型影响不大的数据及特征,比如固定的个人信息
列:custid、trade_no、bank_card_no、id_name
行:删除很多项特征缺失的用户信息
缺失特征数据的用户数据:apply_score等到最后一个特征全为缺失项的用户数据 - 特征转换:特征student_feature列的NA转为0,2转为0(2只有2个)
- 几个需考虑的因素
城市:境外0,一线1,二线2,三线3,四线4,NA及其他(共4组数据,删除)
现阶段不进行处理而直接删除的列:比如 first_transaction_time,latest_query_time,loans_latest_time
四、代码实现
代码实现与zuolinye一起完成。首先是数据处理,包括删除不要信息、缺失值填充、映射替换以及数据归一化。
"""1. 导包"""
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score,r2_score
"""2. 读取数据"""
dataset = pd.read_csv('F:\AI\mission_data\mission_data\data.csv',encoding='gbk')
"""3. 数据处理"""
# 删除固定信息列
dataset = dataset.drop(["custid","trade_no","bank_card_no","id_name","first_transaction_time","latest_query_time","loans_latest_time","source"],axis=1)
# 对于sstudent_feature列,我们进行NAN转成0,2转为0
# 缺失值填充
dataset["student_feature"] = dataset["student_feature"].fillna(0)
# 2替换为0
dataset["student_feature"] = dataset["student_feature"].replace([2],[0])
# 针对城市列'reg_preference_for_trad',进行数据替换
dataset["reg_preference_for_trad"] = dataset["reg_preference_for_trad"].replace("一线城市", "1")
dataset["reg_preference_for_trad"] = dataset["reg_preference_for_trad"].replace("二线城市", "2")
dataset["reg_preference_for_trad"] = dataset["reg_preference_for_trad"].replace("三线城市", "3")
dataset["reg_preference_for_trad"] = dataset["reg_preference_for_trad"].replace("其他城市", "4")
dataset["reg_preference_for_trad"] = dataset["reg_preference_for_trad"].replace("境外", "0")
# 填充其他空值
# 使用均值进行填充
# dataset.fillna(dataset.mean(), inplace=True)
# 使用众数进行填充
dataset = dataset.fillna(0) # 使用 0 替换所有 NaN 的值
col = dataset.columns.tolist()[1:]
def missing(df, columns):
"""
使用众数填充缺失值
df[i].mode()[0] 获取众数第一个值
"""
col = columns
for i in col:
df[i].fillna(df[i].mode()[0], inplace=True)
df[i] = df[i].astype('float')
missing(dataset, col)
# 将object类型转成folat
dataset = dataset.convert_objects(convert_numeric=True)
"""4. 数据划分"""
X = dataset.drop(["status"],axis=1)
Y = dataset["status"]
# 数据按正常的2、8划分
X_train, X_test, y_train, y_test = train_test_split(X, Y,test_size=0.2, random_state=666)
# not enough values to unpack (expected 4, got 2)
from sklearn.preprocessing import minmax_scale # minmax_scale归一化,缩放到0-1
X_train = minmax_scale(X_train)
X_test = minmax_scale(X_test)
# Input contains NaN, infinity or a value too large for dtype('float64').
"""5. 数据归一化"""
from sklearn.preprocessing import minmax_scale
# 归一化,缩放到0-1
X_train = minmax_scale(X_train)
X_test = minmax_scale(X_test)
使用xgboost进行预测,我这里使用的是XGBClassifier ,是xgboost的sklearn包。
"""6. 模型训练"""
from xgboost.sklearn import XGBClassifier
from sklearn import metrics
xgbClassifier = XGBClassifier()
xgbClassifier.fit(X_train, y_train)
xgbClassifier_predict = xgbClassifier.predict(X_test)
"""7. 输出结果"""
print("predict:",xgbClassifier.score(X_test, y_test))
print("f1_score:",f1_score(y_test, xgbClassifier_predict))
y_pred = (xgbClassifier_predict >= 0.5)*1
print('Recall: ', metrics.recall_score(y_test,y_pred))
print('AUC: ', metrics.roc_auc_score(y_test,y_pred))
print("ACC:", metrics.accuracy_score(y_test,y_pred))
得到结果如下:

使用lightgbm进行预测
"""6. 模型训练"""
from lightgbm.sklearn import LGBMClassifier
from sklearn import metrics
lgbmClassifier = LGBMClassifier()
lgbmClassifier.fit(X_train, y_train)
lgbm_predict = lgbmClassifier.predict(X_test)
"""7. 输出结果"""
print("predict:",lgbmClassifier.score(X_test, y_test))
print("f1_score:",f1_score(y_test, lgbm_predict))
y_pred = (lgbm_predict >= 0.5)*1
print('Recall: ', metrics.recall_score(y_test,y_pred))
print('AUC: ', metrics.roc_auc_score(y_test,y_pred))
print("ACC:", metrics.accuracy_score(y_test,y_pred))
得到结果如下
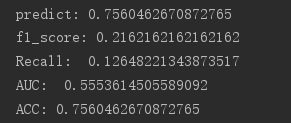
五、存在的问题
- 使用xgboost和lightgbm算法时,是很简单的直接调用其sklearn进行预测,未进行交叉验证和参数调优,需要在后续的学习中跟进。
- 输出一些评价指标时,对阈值的设置还不太理解
- 还可以直接调用xgboost库和lightgbm库进行预测,只是在输入数据时需要注意是不同的数据类型。
- 两种算法的一些细节还需要加深理解,比如优缺点对比和调参时候的区别。