flume+hadoop日志收集集群搭建
flume+hadoop日志收集集群搭建
一、系统环境描述
VMware
ubuntu16.04 64位 ip:172.16.29.10 应用程序服务器
ubuntu16.04 64位 ip:172.16.29.11 hadoop集群 namenode节点
ubuntu16.04 64位 ip:172.16.29.12 hadoop集群 datanode节点
ubuntu16.04 64位 ip:172.16.29.13 hadoop集群 datanode节点
flume 1.8.0
hadoop 2.8.1
jdk 9.0.4
二、架构
此博文是在虚拟机里实现最小架构,实际可按需求在此基础上进行扩展
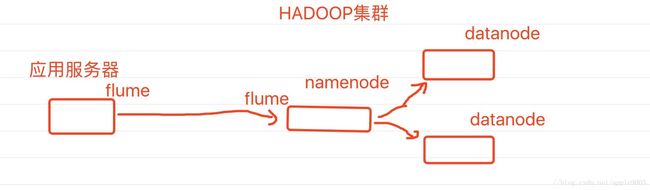
三、hadoop分布式集群搭建
请参见上篇博文:hadoop搭建全分布式集群-虚拟机
四、应用服务器flume配置
jdk安装配置略
下载flume,解压,重命名,放至/usr/local/下
> wget http://mirrors.hust.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-src.tar.gz
> tar -zxvf apache-flume-1.8.0-src.tar.gz
> mv apache-flume-1.8.0 flume在/usr/local/flume/conf下,创建配置文件example.conf:
> cd /usr/local/flume/conf
> touch example.conf配置文件内容为:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/log/test.log
# Describe the sink
#a1.sinks.k1.type = logger # 使用此项配置,会直接将数据打印到终端
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 172.16.29.11
a1.sinks.k1.port = 4444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1打开/etc/profile,配置环境变量:
> vi /etc/profile在文件尾部追加如下内容:
...
#flume
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin记得source一下:
> source /etc/profile五、hadoop集群namenode节点flume配置
此步与第四步一样,只是配置文件内容不同:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 172.16.29.11
a1.sources.r1.port = 4444
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://172.16.29.11:9000/user/zhangsan # hdfs的一个目录
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 20
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
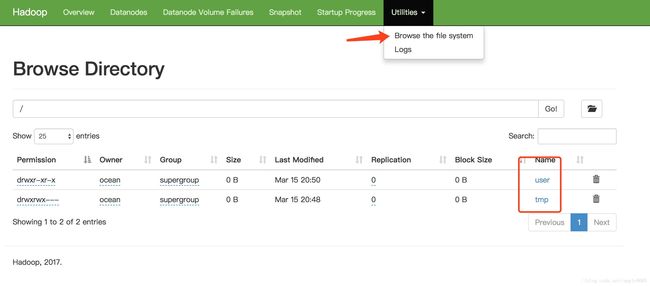
a1.sinks.k1.channel = c1注意:a1.sinks.k1.hdfs.path,写的是你hdfs创建的目录,如下图
http://172.16.29.11:8000/
六、测试
分别启动namenode节点、应用服务器的flume:
进入/usr/local/flume下,执行以下命令:
> flume-ng agent -c /usr/local/flume/conf -f /usr/local/flume/conf/example.conf -Dflume.root.logger=INFO,console -n a1在应用服务器启动应用服务,配置日志写入/data/log/test.log;或手动在此文件下追加保存内容。
查看http://172.16.29.11:50070/explorer.html#/user/zhangsan,如下图: 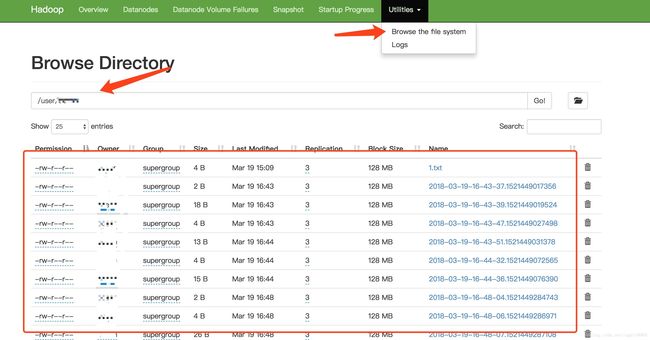
结束!
七、附flume配置项说明
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
## exec表示flume回去调用给的命令,然后从给的命令的结果中去拿数据
a1.sources.r1.type = exec
## 使用tail这个命令来读数据
a1.sources.r1.command = tail -F /home/tuzq/software/flumedata/test.log
a1.sources.r1.channels = c1
# Describe the sink
## 表示下沉到hdfs,类型决定了下面的参数
a1.sinks.k1.type = hdfs
## sinks.k1只能连接一个channel,source可以配置多个
a1.sinks.k1.channel = c1
## 下面的配置告诉用hdfs去写文件的时候写到什么位置,下面的表示不是写死的,而是可以动态的变化的。表示输出的目录名称是可变的
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
##表示最后的文件的前缀
a1.sinks.k1.hdfs.filePrefix = events-
## 表示到了需要触发的时间时,是否要更新文件夹,true:表示要
a1.sinks.k1.hdfs.round = true
## 表示每隔1分钟改变一次
a1.sinks.k1.hdfs.roundValue = 1
## 切换文件的时候的时间单位是分钟
a1.sinks.k1.hdfs.roundUnit = minute
## 表示只要过了3秒钟,就切换生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 3
## 如果记录的文件大于20字节时切换一次
a1.sinks.k1.hdfs.rollSize = 20
## 当写了5个事件时触发
a1.sinks.k1.hdfs.rollCount = 5
## 收到了多少条消息往dfs中追加内容
a1.sinks.k1.hdfs.batchSize = 10
## 使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream:为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
##使用内存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1参考博文:
http://blog.csdn.net/tototuzuoquan/article/details/73196122
https://www.cnblogs.com/itdyb/p/6270893.html
https://www.cnblogs.com/itdyb/p/6266789.html