大数据Druid部署、Push数据摄入实例
Druid 单机部署
有很多文章都介绍了Druid,大数据实时分析,在此我就不多说了。本文主要描述如何部署Druid的环境,Imply提供了一套完整的部署方式,包括依赖库,Druid,图形化的数据展示页面,SQL查询组件等,Push摄入数据Tranquility Server配置。
一、环境安装前准备:
- Java 8 https://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz
- Node.js 4.5.x
- Linux, Mac OS X (不支持 Windows )
- At least 4GB of RAM
二、安装JAVA 8 :
- 新增 Java 目录 mkdir /usr/local/java
- 解压JDK tar -zxvf jdk-8u191-linux-x64.tar.gz
- 配置环境变量
# JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
- 环境变量需要重启生效 source /ect/profile
- 验证JDK java -version
三、Node.js 安装
1、去官网下载和自己系统匹配的文件:
英文网址:https://nodejs.org/en/download/
中文网址:http://nodejs.cn/download/
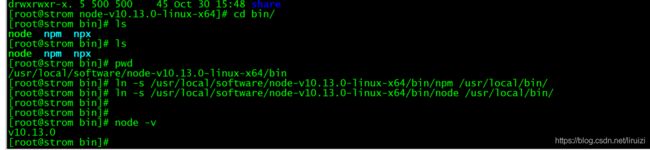
2、下载下来的tar文件上传到服务器并且解压,然后通过建立软连接变为全局;
1)上传服务器可以是自己任意路径,目前我的放置路径为 cd /usr/local/software
2)解压上传 tar -xvf node-v10.13.0-linux-x64.tar.xz
3)建立软连接,变为全局
- ln -s /usr/local/software/node-v10.13.0-linux-x64/bin/npm /usr/local/bin/
- ln -s /usr/local/software/node-v10.13.0-linux-x64/bin/node /usr/local/bin/
4)最后一步检验nodejs是否已变为全局 node -v 说明安装成功。
三、下载与安装 imply
- 从 https://imply.io/get-started 下载最新版本安装包
- tar -zxvf imply-2.7.12.tar.gz
- cd imply-2.7.12
- 启动项目 nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &

- 如果启动出现上图 请重新安装 perl Centos7 下面执行:yum install perl
- 重新启动就好了

安装验证
** 导入测试数据、安装包中包含一些测试的数据,可以通过执行预先定义好的数据说明文件进行导入 **
# 导入数据,进入 imply-2.7.12 执行下面语句
[root@strom imply-2.7.12]# bin/post-index-task --file quickstart/wikipedia-index.json
Beginning indexing data for wikipedia
Task started: index_wikipedia_2018-11-22T07:39:13.068Z
Task log: http://localhost:8090/druid/indexer/v1/task/index_wikipedia_2018-11-22T07:39:13.068Z/log
Task status: http://localhost:8090/druid/indexer/v1/task/index_wikipedia_2018-11-22T07:39:13.068Z/status
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task index_wikipedia_2018-11-22T07:39:13.068Z still running...
Task finished with status: SUCCESS
Completed indexing data for wikipedia. Now loading indexed data onto the cluster...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia is 0.0% finished loading...
wikipedia loading complete! You may now query your data
[root@strom imply-2.7.12]#
四、可视化控制台
-
overlord 控制页面:http://192.168.164.136:8090/console.html

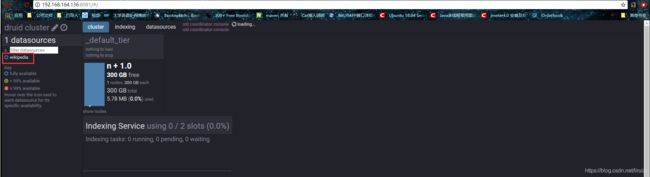
-
druid集群页面:http://192.168.164.136:8081
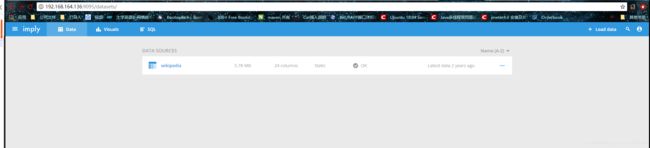
-
数据可视化页面:http://192.168.164.136:9095
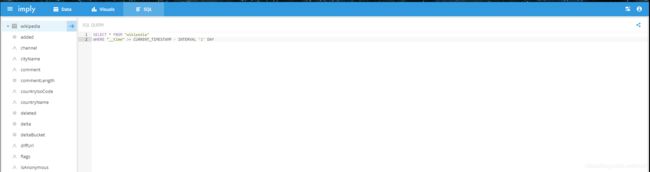
-
数据查询
五、Druid的数据摄入主要包括两大类:
1. 实时输入摄入:包括Pull,Push两种
- Pull:需要启动一个RealtimeNode节点,通过不同的Firehose摄取不同种类的数据源。
- Push:需要启动Tranquility或是Kafka索引服务。通过HTTP调用的方式进行数据摄入
2. 实时数据摄入
2.1 Pull
由于Realtime Node 没有提供高可用,可伸缩等特性,对于比较重要的场景推荐使用 Tranquility Server or 或是Tranquility Kafka索引服务
2.2 Push
通过Tranquility 的数据摄入,可以分为两种方式
Tranquility Server:发送方可以通过Tranquility Server 提供的HTTP接口,向Druid发送数据。
Tranquility Kafka:发送发可以先将数据发送到Kafka,Tranquility Kafka会根据配置从Kafka获取数据,并写到Druid中。
2.2.1 Tranquility Server配置:
开启Tranquility Server,在数据节点上编辑conf/supervise/quickstart.conf 文件,将Tranquility Server注释放开
[root@strom imply-2.7.12]# cd conf/supervise/
[root@strom supervise]# ls
data.conf master-no-zk.conf master-with-zk.conf query.conf quickstart.conf
[root@strom supervise]# vi quickstart.conf
:verify bin/verify-java
:verify bin/verify-default-ports
:verify bin/verify-version-check
:kill-timeout 10
!p10 zk bin/run-zk conf-quickstart
coordinator bin/run-druid coordinator conf-quickstart
broker bin/run-druid broker conf-quickstart
historical bin/run-druid historical conf-quickstart
!p80 overlord bin/run-druid overlord conf-quickstart
!p90 middleManager bin/run-druid middleManager conf-quickstart
imply-ui bin/run-imply-ui-quickstart conf-quickstart
# Uncomment to use Tranquility Server 把此处的注释去掉的
!p95 tranquility-server bin/tranquility server -configFile conf-quickstart/tranquility/server.json
# Uncomment to use Tranquility Kafka
#!p95 tranquility-kafka bin/tranquility kafka -configFile conf-quickstart/tranquility/kafka.json
# Uncomment to use Tranquility Clarity metrics server
#!p95 tranquility-metrics-server java -Xms2g -Xmx2g -cp "dist/tranquility/lib/*:dist/tranquility/conf" com.metamx.tranquility.distribution.DistributionMain server -configFile conf-quickstart/tranquility/server-for-metrics.yaml
:wq!
2.2.2 查看 conf-quickstart/tranquility/server.json
{
"dataSources" : [
{
"spec" : {
"dataSchema" : {
"dataSource" : "tutorial-tranquility-server",
"parser" : {
"type" : "string",
"parseSpec" : {
"timestampSpec" : {
"column" : "timestamp",
"format" : "auto"
},
"dimensionsSpec" : {
"dimensions" : [],
"dimensionExclusions" : [
"timestamp",
"value"
]
},
"format" : "json"
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "hour",
"queryGranularity" : "none"
},
"metricsSpec" : [
{
"type" : "count",
"name" : "count"
},
{
"name" : "value_sum",
"type" : "doubleSum",
"fieldName" : "value"
},
{
"fieldName" : "value",
"name" : "value_min",
"type" : "doubleMin"
},
{
"type" : "doubleMax",
"name" : "value_max",
"fieldName" : "value"
}
]
},
"ioConfig" : {
"type" : "realtime"
},
"tuningConfig" : {
"type" : "realtime",
"maxRowsInMemory" : "50000",
"intermediatePersistPeriod" : "PT10M",
"windowPeriod" : "PT10M"
}
},
"properties" : {
"task.partitions" : "1",
"task.replicants" : "1"
}
}
],
"properties" : {
"zookeeper.connect" : "localhost",
"druid.discovery.curator.path" : "/druid/discovery",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"http.port" : "8200",
"http.threads" : "40",
"serialization.format" : "smile",
"druidBeam.taskLocator": "overlord"
}
}
- “dataSource” : “tutorial-tranquility-server” 可以改成自己需要的 dataSource
2.2.3. 重新启动项目,首先要down 掉上次启动程序
[root@strom imply-2.7.12]# bin/service --down
[root@strom imply-2.7.12]# nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &
出现以下信息,证明启动成功
[root@strom imply-2.7.12]# tail -f quickstart.log
[Thu Nov 22 16:05:20 2018] Running command[zk], logging to[/usr/local/druid/imply-2.7.12/var/sv/zk.log]: bin/run-zk conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[coordinator], logging to[/usr/local/druid/imply-2.7.12/var/sv/coordinator.log]: bin/run-druid coordinator conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[broker], logging to[/usr/local/druid/imply-2.7.12/var/sv/broker.log]: bin/run-druid broker conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[historical], logging to[/usr/local/druid/imply-2.7.12/var/sv/historical.log]: bin/run-druid historical conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[overlord], logging to[/usr/local/druid/imply-2.7.12/var/sv/overlord.log]: bin/run-druid overlord conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[middleManager], logging to[/usr/local/druid/imply-2.7.12/var/sv/middleManager.log]: bin/run-druid middleManager conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[imply-ui], logging to[/usr/local/druid/imply-2.7.12/var/sv/imply-ui.log]: bin/run-imply-ui-quickstart conf-quickstart
[Thu Nov 22 16:05:20 2018] Running command[tranquility-server], logging to[/usr/local/druid/imply-2.7.12/var/sv/tranquility-server.log]: bin/tranquility server -configFile conf-quickstart/tranquility/server.json
2.2.4. 进行测试类编写
# HTTP util
import java.io.IOException;
import java.net.SocketTimeoutException;
import java.security.GeneralSecurityException;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLException;
import javax.net.ssl.SSLSession;
import javax.net.ssl.SSLSocket;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.http.Consts;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.HttpClient;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.config.RequestConfig.Builder;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.conn.ConnectTimeoutException;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.conn.ssl.SSLContextBuilder;
import org.apache.http.conn.ssl.TrustStrategy;
import org.apache.http.conn.ssl.X509HostnameVerifier;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.message.BasicNameValuePair;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* HTTP
* @Description:
* @author:DARUI LI
* @version:1.0.0
* @Data:2018年11月22日 下午4:52:31
*/
public class HttpUtil {
public static final int connTimeout = 5000;
public static final int readTimeout = 5000;
public static final String charset = "UTF-8";
private static HttpClient client = null;
private static Logger logger = LoggerFactory.getLogger(HttpUtil.class);
static {
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
cm.setMaxTotal(128);
cm.setDefaultMaxPerRoute(128);
client = HttpClients.custom().setConnectionManager(cm).build();
}
public static String postJson(String url, String json) throws Exception {
return post(url, json, "application/json", charset, connTimeout, readTimeout);
}
public static String postParameters(String url, String parameterStr) throws Exception {
return post(url, parameterStr, "application/x-www-form-urlencoded", charset, connTimeout, readTimeout);
}
public static String postParameters(String url, String parameterStr, String charset, Integer connTimeout, Integer readTimeout) throws Exception {
return post(url, parameterStr, "application/x-www-form-urlencoded", charset, connTimeout, readTimeout);
}
public static String postParameters(String url, Map<String, String> params) throws
Exception {
return postForm(url, params, null, connTimeout, readTimeout);
}
public static String postParameters(String url, Map<String, String> params, Integer connTimeout, Integer readTimeout) throws
Exception {
return postForm(url, params, null, connTimeout, readTimeout);
}
public static String get(String url) throws Exception {
return get(url, charset, null, null);
}
public static String get(String url, String charset) throws Exception {
return get(url, charset, connTimeout, readTimeout);
}
/**
* 发送一个 Post 请求, 使用指定的字符集编码.
*
* @param url
* @param body RequestBody
* @param mimeType 例如 application/xml "application/x-www-form-urlencoded" a=1&b=2&c=3
* @param charset 编码
* @param connTimeout 建立链接超时时间,毫秒.
* @param readTimeout 响应超时时间,毫秒.
* @return ResponseBody, 使用指定的字符集编码.
* @throws ConnectTimeoutException 建立链接超时异常
* @throws SocketTimeoutException 响应超时
* @throws Exception
*/
public static String post(String url, String body, String mimeType, String charset, Integer connTimeout, Integer readTimeout)
throws Exception {
long startTime = System.currentTimeMillis();
HttpClient client = null;
HttpPost post = new HttpPost(url);
String result = "";
try {
if (StringUtils.isNotBlank(body)) {
HttpEntity entity = new StringEntity(body, ContentType.create(mimeType));
// HttpEntity entity = new StringEntity(body, ContentType.create(mimeType, charset));
post.setEntity(entity);
}
// 设置参数
Builder customReqConf = RequestConfig.custom();
if (connTimeout != null) {
customReqConf.setConnectTimeout(connTimeout);
}
if (readTimeout != null) {
customReqConf.setSocketTimeout(readTimeout);
}
post.setConfig(customReqConf.build());
HttpResponse res;
if (url.startsWith("https")) {
client = createSSLInsecureClient();
res = client.execute(post);
} else {
client = HttpUtil.client;
res = client.execute(post);
}
result = IOUtils.toString(res.getEntity().getContent(), charset);
long endTime = System.currentTimeMillis();
logger.info("HttpClient Method:[post] ,URL[" + url + "] ,Time:[" + (endTime - startTime) + "ms] ,result:" + result);
} finally {
post.releaseConnection();
if (url.startsWith("https") && client != null && client instanceof CloseableHttpClient) {
((CloseableHttpClient) client).close();
}
}
return result;
}
/**
* 提交form表单
*
* @param url
* @param params
* @param connTimeout
* @param readTimeout
* @return
* @throws ConnectTimeoutException
* @throws SocketTimeoutException
* @throws Exception
*/
public static String postForm(String url, Map<String, String> params, Map<String, String> headers, Integer connTimeout, Integer readTimeout) throws
Exception {
long startTime = System.currentTimeMillis();
HttpClient client = null;
HttpPost post = new HttpPost(url);
String result = "";
try {
if (params != null && !params.isEmpty()) {
List<NameValuePair> formParams = new ArrayList<NameValuePair>();
Set<Entry<String, String>> entrySet = params.entrySet();
for (Entry<String, String> entry : entrySet) {
formParams.add(new BasicNameValuePair(entry.getKey(), entry.getValue()));
}
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(formParams, Consts.UTF_8);
post.setEntity(entity);
}
if (headers != null && !headers.isEmpty()) {
for (Entry<String, String> entry : headers.entrySet()) {
post.addHeader(entry.getKey(), entry.getValue());
}
}
// 设置参数
Builder customReqConf = RequestConfig.custom();
if (connTimeout != null) {
customReqConf.setConnectTimeout(connTimeout);
}
if (readTimeout != null) {
customReqConf.setSocketTimeout(readTimeout);
}
post.setConfig(customReqConf.build());
HttpResponse res = null;
if (url.startsWith("https")) {
// 执行 Https 请求.
client = createSSLInsecureClient();
res = client.execute(post);
} else {
// 执行 Http 请求.
client = HttpUtil.client;
res = client.execute(post);
}
result = IOUtils.toString(res.getEntity().getContent(), charset);
long endTime = System.currentTimeMillis();
logger.info("HttpClient Method:[postForm] ,URL[" + url + "] ,Time:[" + (endTime - startTime) + "ms] ,result:" + result);
} finally {
post.releaseConnection();
if (url.startsWith("https") && client != null && client instanceof CloseableHttpClient) {
((CloseableHttpClient) client).close();
}
}
return result;
}
/**
* 发送一个 GET 请求
*
* @param url
* @param charset
* @param connTimeout 建立链接超时时间,毫秒.
* @param readTimeout 响应超时时间,毫秒.
* @return
* @throws ConnectTimeoutException 建立链接超时
* @throws SocketTimeoutException 响应超时
* @throws Exception
*/
public static String get(String url, String charset, Integer connTimeout, Integer readTimeout)
throws Exception {
long startTime = System.currentTimeMillis();
HttpClient client = null;
HttpGet get = new HttpGet(url);
String result = "";
try {
// 设置参数
Builder customReqConf = RequestConfig.custom();
if (connTimeout != null) {
customReqConf.setConnectTimeout(connTimeout);
}
if (readTimeout != null) {
customReqConf.setSocketTimeout(readTimeout);
}
get.setConfig(customReqConf.build());
HttpResponse res = null;
if (url.startsWith("https")) {
// 执行 Https 请求.
client = createSSLInsecureClient();
res = client.execute(get);
} else {
// 执行 Http 请求.
client = HttpUtil.client;
res = client.execute(get);
}
result = IOUtils.toString(res.getEntity().getContent(), charset);
long endTime = System.currentTimeMillis();
logger.info("HttpClient Method:[postForm] ,URL[" + url + "] ,Time:[ " + (endTime - startTime) + "ms ] ,result:" + result);
} finally {
get.releaseConnection();
if (url.startsWith("https") && client != null && client instanceof CloseableHttpClient) {
((CloseableHttpClient) client).close();
}
}
return result;
}
/**
* 从 response 里获取 charset
*
* @param ressponse
* @return
*/
@SuppressWarnings("unused")
private static String getCharsetFromResponse(HttpResponse ressponse) {
if (ressponse.getEntity() != null && ressponse.getEntity().getContentType() != null && ressponse.getEntity().getContentType().getValue() != null) {
String contentType = ressponse.getEntity().getContentType().getValue();
if (contentType.contains("charset=")) {
return contentType.substring(contentType.indexOf("charset=") + 8);
}
}
return null;
}
/**
* 创建 SSL连接
*
* @return
* @throws GeneralSecurityException
*/
private static CloseableHttpClient createSSLInsecureClient() throws GeneralSecurityException {
try {
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext, new X509HostnameVerifier() {
public boolean verify(String arg0, SSLSession arg1) {
return true;
}
public void verify(String host, SSLSocket ssl) throws IOException {
}
public void verify(String host, X509Certificate cert) throws SSLException {
}
public void verify(String host, String[] cns, String[] subjectAlts) throws SSLException {
}
});
return HttpClients.custom().setSSLSocketFactory(sslsf).build();
} catch (GeneralSecurityException e) {
throw e;
}
}
}
/**
* Druid Tranquility Server http 请求多线程 demo
* @Description:
* @author:DARUI LI
* @version:1.0.0
* @Data:2018年11月22日 下午4:55:33
*/
public class DruidThreadTest {
private static final int THREADNUM = 10;// 线程数量
public static void main(String[] args) {
// 线程数量
int threadmax = THREADNUM;
for (int i = 0; i < threadmax; i++) {
ThreadMode thread = new ThreadMode();
thread.getThread().start();
}
}
}
import java.util.Map;
import org.joda.time.DateTime;
import com.alibaba.fastjson.JSON;
import com.bitup.strom.uitl.HttpUtil;
import com.google.common.collect.ImmutableMap;
/**
* 执行程序 多线程访问
* @Description:
* @author:DARUI LI
* @version:1.0.0
* @Data:2018年11月22日 下午4:57:49
*/
public class ThreadMode {
public Thread getThread() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
System.out.print("\nout:" + i);
final Map<String, Object> obj = ImmutableMap.<String, Object>of("timestamp", new DateTime().toString(),"test5",i);
try {
String postJson = HttpUtil.postJson("http://192.168.162.136:8200/v1/post/tutorial-tranquility-server", JSON.toJSONString(obj));
System.err.println(postJson);
} catch (Exception e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("start time:" + start+ "; end time:" + end+ "; Run Time:" + (end - start) + "(ms)");
}
});
return thread;
}
}
2.2.5 Tranquility Kafka配置:
开启Tranquility Kafka,在数据节点上编辑conf/supervise/quickstart.conf 文件,将Tranquility Kafka注释放开
[root@strom imply-2.7.12]# cd conf/supervise/
[root@strom supervise]# ls
data.conf master-no-zk.conf master-with-zk.conf query.conf quickstart.conf
[root@strom supervise]# vi quickstart.conf
:verify bin/verify-java
:verify bin/verify-default-ports
:verify bin/verify-version-check
:kill-timeout 10
!p10 zk bin/run-zk conf-quickstart
coordinator bin/run-druid coordinator conf-quickstart
broker bin/run-druid broker conf-quickstart
historical bin/run-druid historical conf-quickstart
!p80 overlord bin/run-druid overlord conf-quickstart
!p90 middleManager bin/run-druid middleManager conf-quickstart
imply-ui bin/run-imply-ui-quickstart conf-quickstart
# Uncomment to use Tranquility Server
#!p95 tranquility-server bin/tranquility server -configFile conf-quickstart/tranquility/server.json
# Uncomment to use Tranquility Kafka 把此处的注释去掉的
!p95 tranquility-kafka bin/tranquility kafka -configFile conf-quickstart/tranquility/kafka.json
# Uncomment to use Tranquility Clarity metrics server
#!p95 tranquility-metrics-server java -Xms2g -Xmx2g -cp "dist/tranquility/lib/*:dist/tranquility/conf" com.metamx.tranquility.distribution.DistributionMain server -configFile conf-quickstart/tranquility/server-for-metrics.yaml
:wq!
2.2.6 详细配置可参考:
http://druid.io/docs/0.10.1/tutorials/tutorial-kafka.html
配置参考
通用配置:https://github.com/druid-io/tranquility/blob/master/docs/configuration.md
数据摄入通用配置:http://druid.io/docs/latest/ingestion/index.html
Tranquility Kafka:https://github.com/druid-io/tranquility/blob/master/docs/kafka.md
Druid 查询数据
1、基本sql查询
druid 查询接口的使用
druid的查询接口是HTTP REST 风格的查询方式,使用HTTP REST 风格查询(Broker,Historical,或者Realtime)节点的数据,查询参数为JSON格式,每个节点类型都会暴露相同的REST查询接口
curl -X POST ':/druid/v2/?pretty' -H 'Content-Type:application/json' -d @<query_json_file>
queryable_host: broker节点ip port: broker 节点端口 默认是8082
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/aa.json http://10.20.23.41:8082/druid/v2/?pretty
query 查询的类型有
1、Timeseries
2、TopN
3、GroupBy
4、Time Boundary
5、Segment Metadata
6、Datasource Metadata
7、Search
8、select
其中 Timeseries、TopN、GroupBy为聚合查询,Time Boundary、Segment Metadata、Datasource Metadata 为元数据查询,Search 为搜索查询
1、Timeseries
对于需要统计一段时间内的汇总数据,或者是指定时间粒度的汇总数据,druid可以通过Timeseries来完成。
timeseries 查询包括如下的字段:
| 字段名 | 描述 | 是否必须 |
|---|---|---|
| queryType | 查询类型,这里只有填写timeseries查询 | 是 |
| dataSource | 要查询的数据集 | 是 |
| descending | 是否降序 | 是 |
| queryType | 查询类型,这里只有填写timeseries查询 | 否 |
| intervals | 查询的时间范围,默认是ISO-8601格式 | 是 |
| granularity | 查询结果进行聚合的时间粒度 | 是 |
| filter | 过滤条件 | 否 |
| aggregations | 聚合 | 是 |
| postAggregations | 后期聚合 | 否 |
| context | 指定一些查询参数 | 否 |
| granularity | 查询结果进行聚合的时间粒度 | 是 |
timeseries输出每个时间粒度内指定条件的统计信息,通过filter指定条件过滤,通过aggregations和postAggregations指定聚合方式。
timeseries不能输出维度信息,granularity支持all,none,second,minute,hour,day,week,month,year等维度
all:汇总1条输出 none:不推荐使用
其他的:则输出相应粒度统计信息
查询的json
{
"aggregations": [
{
"type": "count",
"name": "count"
}
],
"intervals": "1917-08-25T08:35:20+00:00/2017-08-25T08:35:20+00:00",
"dataSource": "app_auto_prem_qd_pp3",
"granularity": "all",
"postAggregations": [],
"queryType": "timeseries"
}
等同于sql select count(1) from app_auto_prem_qd_pp3
TopN 返回指定维度和排序字段的有序top-n序列.TopN支持返回前N条记录,并支持指定的Metric为排序依据
{
"metric": "sum__total_standard_premium",
"aggregations": [
{
"type": "doubleSum",
"fieldName": "total_standard_premium",
"name": "sum__total_standard_premium"
}
],
"dimension": "is_new_car",
"intervals": "1917-08-29T20:05:10+00:00/2017-08-29T20:05:10+00:00",
"dataSource": "app_auto_prem_qd_pp3",
"granularity": "all",
"threshold": 50000,
"postAggregations": [],
"queryType": "topN"
}
| 字段名 | 描述 | 是否必须 |
|---|---|---|
| queryType | 对于TopN查询,这个必须是TopN | 是 |
| dataSource | 要查询的数据集 | 是 |
| intervals | 查询的时间范围,默认是ISO-8601格式 | 是 |
| filter | 过滤条件 | 否 |
| aggregations | 聚合 | 是 |
| postAggregations | 后期聚合 | 否 |
| dimension | 进行TopN查询的维护,一个TopN查询只能有一个维度 | 是 |
| threshold | TopN中的N值 | 是 |
| metric | 进行统计并排序的metric | 是 |
| context | 指定一些查询参数 | 否 |
metric:是TopN专属
方式:
"metric":"" 默认情况是升序排序的
"metric" : {
"type" : "numeric", //指定按照numeric 降序排序
"metric" : ""
}
"metric" : {
"type" : "inverted", //指定按照numeric 升序排序
"metric" : ""
}
"metric" : {
"type" : "lexicographic", //指定按照字典序排序
"metric" : ""
}
"metric" : {
"type" : "alphaNumeric", //指定按照数字排序
"metric" : ""
}
需要注意的是,TopN是一个近似算法,每一个segment返回前1000条进行合并得到最后的结果,如果dimension
的基数在1000以内,则是准确的,超过1000就是近似值
groupBy
groupBy 类似于SQL中的group by 操作,能对指定的多个维度进行分组,也支持对指定的维度进行排序,并输出limit行数,同时支持having操作
{
"dimensions": [
"is_new_car",
"status"
],
"aggregations": [
{
"type": "doubleSum",
"fieldName": "total_standard_premium",
"name": "sum__total_standard_premium"
}
],
"having": {
"type": "greaterThan",
"aggregation": "sum__total_standard_premium",
"value": "484000"
},
"intervals": "1917-08-29T20:26:52+00:00/2017-08-29T20:26:52+00:00",
"limitSpec": {
"limit": 2,
"type": "default",
"columns": [
{
"direction": "descending",
"dimension": "sum__total_standard_premium"
}
]
},
"granularity": "all",
"postAggregations": [],
"queryType": "groupBy",
"dataSource": "app_auto_prem_qd_pp3"
}
等同于SQL select is_new_car,status,sum(total_standard_premium) from app_auto_prem_qd_pp3 group by is_new_car,status limit 50000 having sum(total_standard_premium)>484000
{
"version" : "v1",
"timestamp" : "1917-08-30T04:26:52.000+08:00",
"event" : {
"sum__total_standard_premium" : 8.726074368E9,
"is_new_car" : "是",
"status" : null
}
}, {
"version" : "v1",
"timestamp" : "1917-08-30T04:26:52.000+08:00",
"event" : {
"sum__total_standard_premium" : 615152.0,
"is_new_car" : "否",
"status" : null
}
}
| 字段名 | 描述 | 是否必须 |
|---|---|---|
| queryType | 对于GroupBy查询,该字段必须是GroupBy | 是 |
| dataSource | 要查询的数据集 | 是 |
| dimensions | 进行GroupBy查询的维度集合 | 是 |
| limitSpec | 统计结果进行排序 | 否 |
| having | 对统计结果进行筛选 | 否 |
| granularity | 查询结果进行聚合的时间粒度 | 是 |
| postAggregations | 后聚合器 | 否 |
| intervals | 查询的时间范围,默认是ISO-8601格式 | 是 |
| context | 指定一些查询参数 | 否 |
GroupBy特有的字段为limitSpec 和having
limitSpec 指定排序规则和limit的行数
{
"type" : "default",
"limit":<integer_value>,
"columns":[list of OrderByColumnSpec]
}
其中columns是一个数组,可以指定多个排序字段,排序字段可以使demension 或者metric 指定排序规则的拼写方式
{
"dimension" :"" ,
"direction" : <"ascending"|"descending">
}
"limitSpec": {
"limit": 2,
"type": "default",
"columns": [
{
"direction": "descending",
"dimension": "sum__total_standard_premium"
},
{
"direction": "ascending",
"dimension": "is_new_car"
}
]
}
having 类似于SQL中的having操作
select 类似于sql中select操作,select用来查看druid中的存储的数据,并支持按照指定过滤器和时间段查看指定维度和metric,能通过descending字段指定排序顺序,并支持分页拉取,但不支持aggregations和postAggregations
json 实例如下
{
"dimensions": [
"status",
"is_new_car"
],
"pagingSpec":{
"pagingIdentifiers":{},
"threshold":3
},
"intervals": "1917-08-25T08:35:20+00:00/2017-08-25T08:35:20+00:00",
"dataSource": "app_auto_prem_qd_pp3",
"granularity": "all",
"context" : {
"skipEmptyBuckets" : "true"
},
"queryType": "select"
}
select
相当于SQL语句 select status,is_new_car from app_auto_prem_qd_pp3 limit 3
[ {
"timestamp" : "2017-08-22T14:00:00.000Z",
"result" : {
"pagingIdentifiers" : {
"app_auto_prem_qd_pp3_2017-08-22T08:00:00.000+08:00_2017-08-23T08:00:00.000+08:00_2017-08-22T18:11:01.983+08:00" : 2
},
"dimensions" : [ "is_new_car", "status" ],
"metrics" : [ "total_actual_premium", "count", "total_standard_premium" ],
"events" : [ {
"segmentId" : "app_auto_prem_qd_pp3_2017-08-22T08:00:00.000+08:00_2017-08-23T08:00:00.000+08:00_2017-08-22T18:11:01.983+08:00",
"offset" : 0,
"event" : {
"timestamp" : "2017-08-22T22:00:00.000+08:00",
"status" : null,
"is_new_car" : "是",
"total_actual_premium" : 1012.5399780273438,
"count" : 1,
"total_standard_premium" : 1250.050048828125
}
}, {
"segmentId" : "app_auto_prem_qd_pp3_2017-08-22T08:00:00.000+08:00_2017-08-23T08:00:00.000+08:00_2017-08-22T18:11:01.983+08:00",
"offset" : 1,
"event" : {
"timestamp" : "2017-08-22T22:00:00.000+08:00",
"status" : null,
"is_new_car" : "是",
"total_actual_premium" : 708.780029296875,
"count" : 1,
"total_standard_premium" : 1250.050048828125
}
}, {
"segmentId" : "app_auto_prem_qd_pp3_2017-08-22T08:00:00.000+08:00_2017-08-23T08:00:00.000+08:00_2017-08-22T18:11:01.983+08:00",
"offset" : 2,
"event" : {
"timestamp" : "2017-08-22T22:00:00.000+08:00",
"status" : null,
"is_new_car" : "是",
"total_actual_premium" : 1165.489990234375,
"count" : 1,
"total_standard_premium" : 1692.800048828125
}
} ]
}
} ]
在pagingSpec中指定分页拉取的offset和条目数,在结果中会返回下次拉取的offset,
"pagingSpec":{
"pagingIdentifiers":{},
"threshold":3,
"fromNext" :true
}
Search
search 查询返回匹配中的维度,类似于SQL中的topN操作,但是支持更多的匹配操作,
json示例如
{
"queryType": "search",
"dataSource": "app_auto_prem_qd_pp3",
"granularity": "all",
"limit": 2,
"searchDimensions": [
"data_source",
"department_code"
],
"query": {
"type": "insensitive_contains",
"value": "1"
},
"sort" : {
"type": "lexicographic"
},
"intervals": [
"1917-08-25T08:35:20+00:00/2017-08-25T08:35:20+00:00"
]
}
searchDimensions搜索的维度
| 字段名 | 描述 | 是否必须 |
|---|---|---|
| queryType | 对于search查询,该字段必须是search | 是 |
| dataSource | 要查询的数据集 | 是 |
| searchDimensions | 运行search的维度 | 是 |
| limit | 对统计结果进行限制 | 否(默认1000) |
| granularity | 查询结果进行聚合的时间粒度 | 是 |
| intervals | 查询的时间范围,默认是ISO-8601格式 | 是 |
| sort | 指定搜索结果排序 | 否 |
| query | 查询操作 | 是 |
| context | 指定一些查询参数 | 否 |
| filter | 过滤器 | 否 |
需要注意的是,search只是返回匹配中维度,不支持其他聚合操作,如果要将search作为查询条件进行topN,groupBy或timeseries等操作,则可以在filter字段中
指定各种过滤方式,filter字段也支持正则匹配,
查询结果如下:
[ {
"timestamp" : "2017-08-22T08:00:00.000+08:00",
"result" : [ {
"dimension" : "data_source",
"value" : "226931204023",
"count" : 2
}, {
"dimension" : "data_source",
"value" : "226931204055",
"count" : 7
} ]
} ]
查询的选择
1、在可能的情况下,建议使用Timeseries和TopN查询而不是GroupBy,GroupBy是最灵活的查询,也是最差的表现。对于不需要对维度进行分组的聚合,Timeseries比GroupBy查询要快,对于单个维度进行分组和排序,TopN查询比GroupBy更加优化
groupBy 多列聚合group by
{
"queryType": "groupBy",
"dataSource": "bitup",
"dimensions": ["sample_time"],
"granularity": "all",
"filter": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "symbol",
"value": "xbtusd"
}
]
},
"intervals": [
"2018-11-28T03:40:00/2018-11-28T03:54:30"
],
"limitSpec": {
"columns": [
{
"dimension": "sample_time",
"direction": "descending",
"dimensionOrder": "numeric"
}
],
"limit": 36000,
"type": "default"
}
}
topN 单 group by
{
"queryType": "topN",
"dataSource": "bitup",
"dimension": "sample_time",
"threshold": 36000,
"metric": "count",
"granularity": "all",
"aggregations": [
{
"type": "count",
"name": "count"
}
],
"intervals": [
"2018-11-28T03:40:00/2018-11-28T03:54:30"
]
}
类似于Select,但不支持分页,但是如果没有分页需求,推荐使用这个,性能比Select好
{
"queryType": "scan",
"dataSource": "bitup",
"resultFormat": "list",
"columns":["symbol","kline_type","sample_time","open","close","high","low","vol","coin_vol","vwap"],
"intervals": [
"2018-11-28T03:40:00/2018-11-28T03:54:30"
],
"batchSize":20480,
"limit":36000
}