SpringBoot + Flume + Hadoop搭建日志采集系统(通过Flume输送springboot项目日志到Hdfs文件存储服务器)
主旨:讲述SpringBoot项目使用LogBack日志,LogBack + Flume收集日志到Hdfs文件存储服务器的环境搭建
主要软件版本配置说明:
- SpringBoot-2.1.4 (windows10 IDEA DeBug模式运行)
- Flume-1.9.0 (部署在hadoop-1服务器上,也就是hadoop主节点所在服务器)
- Hadoop-3.2.0 (部署在三台Linux虚拟机上)
???????????????日志采集架构图???????????????
✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌以下介绍搭建步骤✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌
一、搭建Hadoop-3.2.0集群
二、安装Flume-1.9.0
2.1下载Flume-1.9.0安装包
2.2下载上传至Hadoop集群主节点服务器/opt/hadoop/路径下
2.3解压缩apache-flume-1.9.0-bin.tar.gz
2.4配置Flume的环境变量
2.5检查是否配置成功
2.6配置Flume
2.7创建HDFS下flume目录并给予权限
2.8启动Flume a1
三、配置SpringBoot项目
3.1引入logback-flume依赖
3.2配置logback-spring.xml
3.3启动SpringBoot项目
???????????????日志采集架构图???????????????
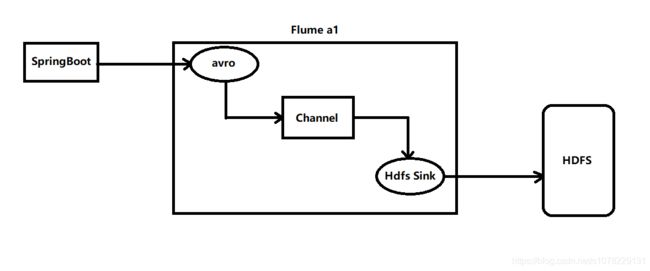
✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌以下介绍搭建步骤✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌✌
一、搭建Hadoop-3.2.0集群
准备资源: 3台Linux虚拟机 linux_JDK1.8安装包 Hadoop-3.2.0安装包
可参考我的另一篇文章:Linux从零搭建Hadoop集群(CentOS7+hadoop 3.2.0+JDK1.8完全分布式集群)
二、安装Flume-1.9.0
2.1下载Flume-1.9.0安装包
下载地址:http://flume.apache.org/download.html
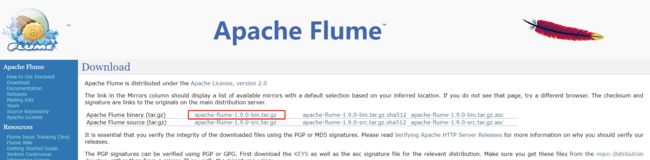
我选择的是编译后的包。
![]()
2.2下载上传至Hadoop集群主节点服务器/opt/hadoop/路径下
2.3解压缩apache-flume-1.9.0-bin.tar.gz
# 解压缩命令
tar -zxvf apache-flume-1.9.0-bin.tar.gz
# 修改解压后的文件名
mv apache-flume-1.9.0-bin flume-1.9.0
如图:
![]()
2.4配置Flume的环境变量
# 修改Linux配置信息
vi /etc/profile
# 添加如下信息
export FLUME_HOME=/opt/hadoop/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
如图:
![]()
添加完毕保存配置文件,并重新编译配置文件
# 使配置文件生效
source /etc/profile
2.5检查是否配置成功
执行 flume-ng version 命令:
如图则代表成功:

2.6配置Flume
进入/opt/flume-1.9.0/conf目录
复制一份flume-env.sh.template
cp flume-env.sh.template flume-env.sh
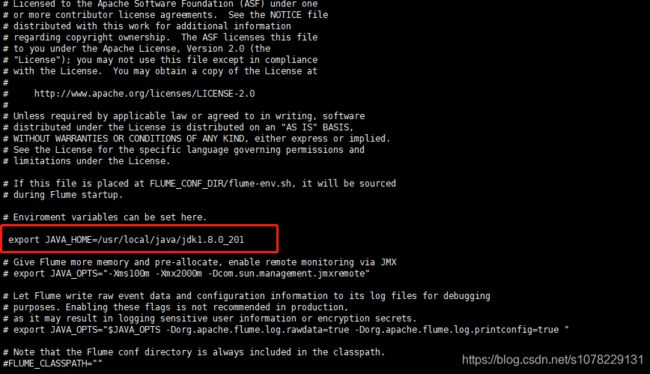
修改flume-env.sh
vi flume-env.sh
# 添加如下信息
export JAVA_HOME=/usr/local/java/jdk1.8.0_201 (此处是你的JDK安装)
如图:
新建flume.conf,加入如下内容
vi flume.conf
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
# 默认该通道中最大的可以存储的 event 数量
a1.channels.c1.capacity = 10000
# 每次最大可以从 source 中拿到或者送到 sink 中的 event 数量
a1.channels.c1.transactionCapacity = 1000
# 描述和配置 sink 组件:k1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.217.128:9000/flume/%Y-%m-%d/%H(你的hadoop集群hdfs地址)
a1.sinks.k1.hdfs.filePrefix = logs
a1.sinks.k1.hdfs.inUsePrefix = .
# 默认值:30; hdfs sink 间隔多长将临时文件滚动成最终目标文件,单位:秒; 如果设置成 0,则表示不根据时间来滚动文件
a1.sinks.k1.hdfs.rollInterval = 0
# 默认值:1024; 当临时文件达到该大小(单位:bytes)时,滚动成目标文件; 如果设置成 0,则表示不根据临时文件大小来滚动文件
a1.sinks.k1.hdfs.rollSize = 16777216
# 默认值:10; 当 events 数据达到该数量时候,将临时文件滚动成目标文件; 如果设置成 0,则表示不根据 events 数据来滚动文件
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.writeFormat = text
# 生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 操作 hdfs 超时时间
a1.sinks.k1.callTimeout =10000
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.7创建HDFS下flume目录并给予权限
hadoop fs -mkdir /flume
hadoop fs -chown -R flume:flume /flume
如图:
2.8启动Flume a1
执行命令????
flume-ng agent --conf conf --conf-file conf/flume.conf -n a1 -Dflume.root.logger=INFO,console看到如下日志即表示成功↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓

三、配置SpringBoot项目
3.1引入logback-flume依赖
com.teambytes.logback
logback-flume-appender_2.10
0.0.9
3.2配置logback-spring.xml
192.168.217.128:44444(你的flume a1所在地址:a1监听的端口号)
connect-timeout=4000;
request-timeout=8000
100
1000
myHeader = myValue
JustryDeng's Application
%d{HH:mm:ss.SSS} %-5level %logger{36} - \(%file:%line\) - %message%n%ex
3.3启动SpringBoot项目
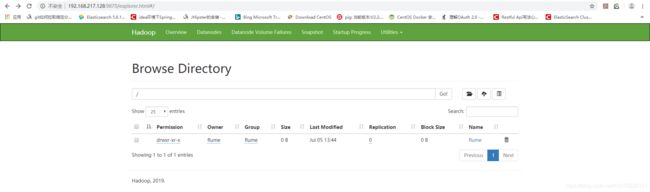
查看HDFS系统中flume目录:
图一 /flume:
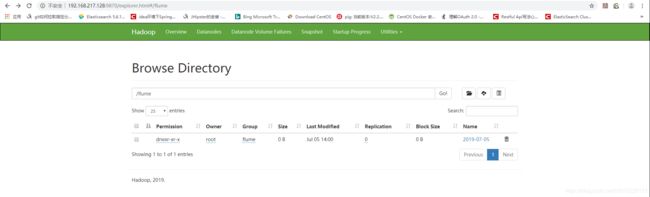
图二 /flume/年-月-日:
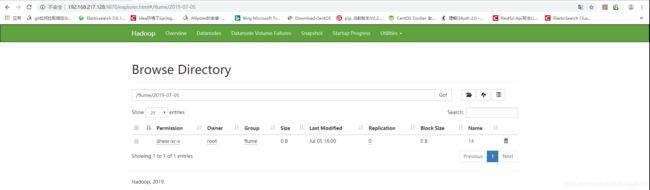
图三 /flume/年-月-日/小时:
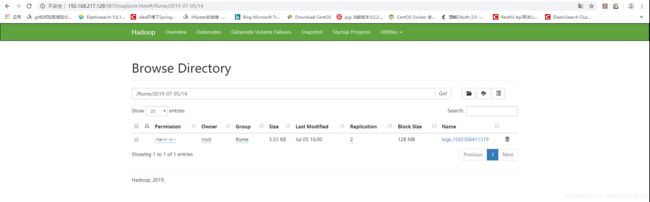
图四 日志文件内容:
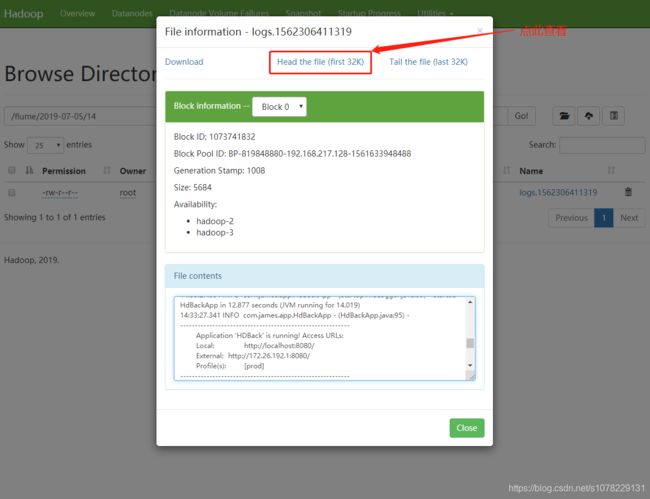
四、完毕 - 接下来准备数据清洗和数据分析相关文章
最后给各位看官来波福利!
阿里云服务器代金券和折扣免费领:https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=ypbt9nme
性能级主机2-5折:https://promotion.aliyun.com/ntms/act/enterprise-discount.html?userCode=ypbt9nme
新用户云通讯专享8折:https://www.aliyun.com/acts/alicomcloud/new-discount?userCode=ypbt9nme
新老用户云主机低4折专项地址:https://promotion.aliyun.com/ntms/act/qwbk.html?userCode=ypbt9nme
680元即可注册商标专项地址:https://tm.aliyun.com/?userCode=ypbt9nme
17元/月云主机:https://promotion.aliyun.com/ntms/act/qwbk.html?spm=5176.11533447.1097531.13.22805cfaiTv7SN&userCode=ypbt9nme