高可用flume-ng搭建
一、概述
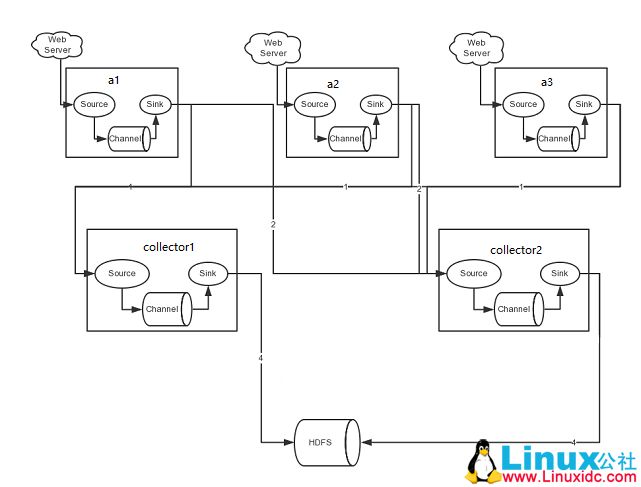
1.通过搭建高可用flume来实现对数据的收集并存储到hdfs上,架构图如下:
二、配置Agent
1.cat flume-client.properties
#name the components on this agent 声明source、channel、sink的名称
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
#Describe/configure the source 声明source的类型为通过tcp的方式监听本地端口5140
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 5140
a1.sources.r1.host = localhost
a1.sources.r1.channels = c1
#define sinkgroups 此处配置k1、k2的组策略,类型为均衡负载方式
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=k1 k2
a1.sinkgroups.g1.processor.type=load_balance
a1.sinkgroups.g1.processor.backoff=true
a1.sinkgroups.g1.processor.selector=round_robin
#define the sink 1 数据流向,都是通过avro方式发到两台collector机器
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=Hadoop1
a1.sinks.k1.port=5150
#define the sink 2
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=hadoop2
a1.sinks.k2.port=5150
# Use a channel which buffers events in memory 指定channel的类型为内存模式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel=c1
#a2和a3的配置和a1相同
三、配置Collector
1.cat flume-server.properties
#name the components on this agent 声明source、channel、sink的名称
collector1.sources = r1
collector1.channels = c1
collector1.sinks = k1
# Describe the source 声明source的类型为avro
collector1.sources.r1.type = avro
collector1.sources.r1.port = 5150
collector1.sources.r1.bind = 0.0.0.0
collector1.sources.r1.channels = c1
# Describe channels c1 which buffers events in memory 指定channel的类型为内存模式
collector1.channels.c1.type = memory
collector1.channels.c1.capacity = 1000
collector1.channels.c1.transactionCapacity = 100
# Describe the sink k1 to hdfs 指定sink数据流向hdfs
collector1.sinks.k1.type = hdfs
collector1.sinks.k1.channel = c1
collector1.sinks.k1.hdfs.path = hdfs://master/user/flume/log
collector1.sinks.k1.hdfs.fileType = DataStream
collector1.sinks.k1.hdfs.writeFormat = TEXT
collector1.sinks.k1.hdfs.rollInterval = 300
collector1.sinks.k1.hdfs.filePrefix = %Y-%m-%d
collector1.sinks.k1.hdfs.round = true
collector1.sinks.k1.hdfs.roundValue = 5
collector1.sinks.k1.hdfs.roundUnit = minute
collector1.sinks.k1.hdfs.useLocalTimeStamp = true
#collector2配置和collector1相同
四、启动
1.在Collector上启动fulme-ng
flume-ng agent -n collector1 -c conf -f /usr/local/flume/conf/flume-server.properties -Dflume.root.logger=INFO,console
# -n 后面接配置文件中的Agent Name
2.在Agent上启动flume-ng
flume-ng agent -n a1 -c conf -f /usr/local/flume/conf/flume-client.properties -Dflume.root.logger=INFO,console
五、测试
[root@hadoop5 ~]# echo "hello" | nc localhost 5140 #需要安装nc
17/09/03 22:56:58 INFO source.AvroSource: Avro source r1 started.
17/09/03 22:59:09 INFO ipc.NettyServer: [id: 0x60551752, /192.168.100.15:34310 => /192.168.100.11:5150] OPEN
17/09/03 22:59:09 INFO ipc.NettyServer: [id: 0x60551752, /192.168.100.15:34310 => /192.168.100.11:5150] BOUND: /192.168.100.11:5150
17/09/03 22:59:09 INFO ipc.NettyServer: [id: 0x60551752, /192.168.100.15:34310 => /192.168.100.11:5150] CONNECTED: /192.168.100.15:34310
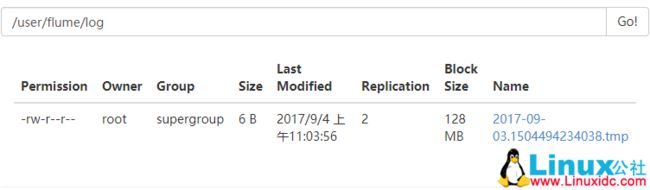
17/09/03 23:03:54 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
17/09/03 23:03:54 INFO hdfs.BucketWriter: Creating hdfs://master/user/flume/log/2017-09-03.1504494234038.tmp
六、总结
高可用flume-ng一般有两种模式:load_balance和failover。此次使用的是load_balance,failover的配置如下:
#set failover
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 10
a1.sinkgroups.g1.processor.priority.k2 = 1
a1.sinkgroups.g1.processor.maxpenalty = 10000
一些常用的source、channel、sink类型如下:

本文永久更新链接地址:http://www.linuxidc.com/Linux/2017-10/147645.htm
