网易云音乐是怎么做曲库缓存的?设计动机大揭秘!
云音乐曲库缓存随着多年的实践、改善,结合曲库数据的特点,形成自有的一套缓存使用体系,并能够取得了很好的效果。
在工作过程中,有些喜欢刨根问底的同学会经常来讨论这样设计的原因,想在其它场景中借鉴一样的思路,在此想以文章进行历程介绍,让更多的同学了解背后设计的动机。
本篇文章较少形而上的理论知识,更多以实战为主,以解决问题作为切入点,讲述曲库缓存的设计之道
缓存基础介绍
缓存是系统设计中,用于提升底层系统访问能力的一种技术手段,它同样作用于云音乐的各个系统中,一种常用的缓存使用调用链路如下:
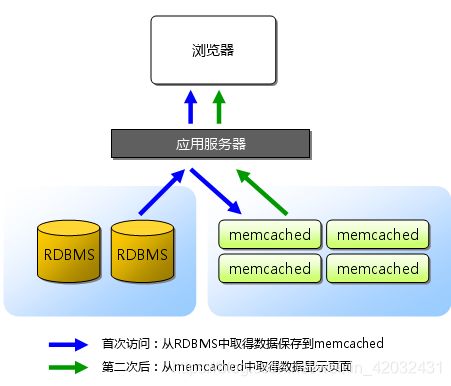
转化为时序图,如下图所示:
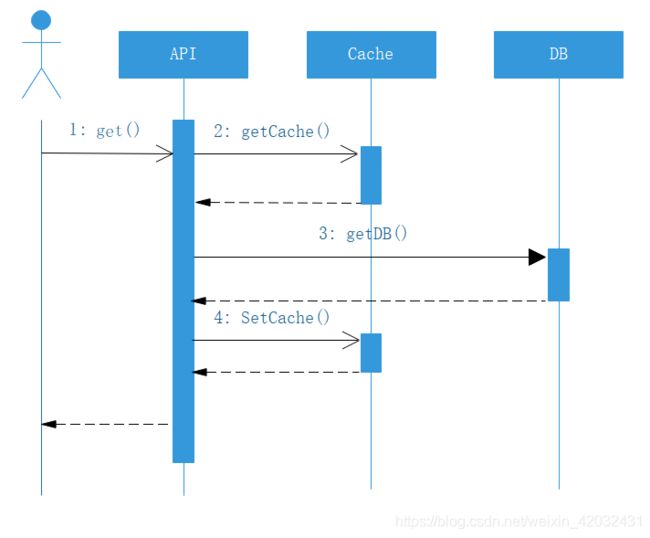
整个缓存的数据放入,是采用懒加载的方式,先取缓存,取到则返回,取不到则透过到下一层,拿到后会回写当前层的缓存,这是整个云音乐缓存使用的整体思路
在正式进入实战之前,介绍一些概念数据:
- 一次简单的DB操作,耗时在 0.5~0.6ms
- 一次简单缓存操作(非本机),耗时在 0.5~0.6ms
- 一次简单的本机缓存操作,耗时在0.2~0.3 ms
云音乐曲库读是整个云音乐服务中接口调用量最高的几个之一,曲库读整体服务的rpc峰值调用qps能够达到 50w+ (双机房累加),通过多种缓存使用的尝试及调优,并最终从以下角度进行考虑并实践,得到较好的效果
曲库数据的特点
很多中间件、组件等设计,在考虑设计时,都会朝通用化方式去实现,而契合业务场景的特点,则更能将性能做到极致,曲库的缓存实现,是与曲库数据特性有着深度的联系,具体如下:
- 读多写少
- 可以读写分离
- 数据变化秒级延迟用户不敏感
- 热点数据集中
- 通过List(列表)获取数据的场景很多,有大量 MultiGet 操作
有上述特点的业务场景,都可以参考曲库的缓存使用姿势。
实战场景1: 防穿透
什么是穿透?
缓存穿透是指缓存和数据库中都没有的数据,而不断有请求过来请求,导致请求不断向下到DB查询,会给底层带来极大的压力
这里有个简单而通用的思路
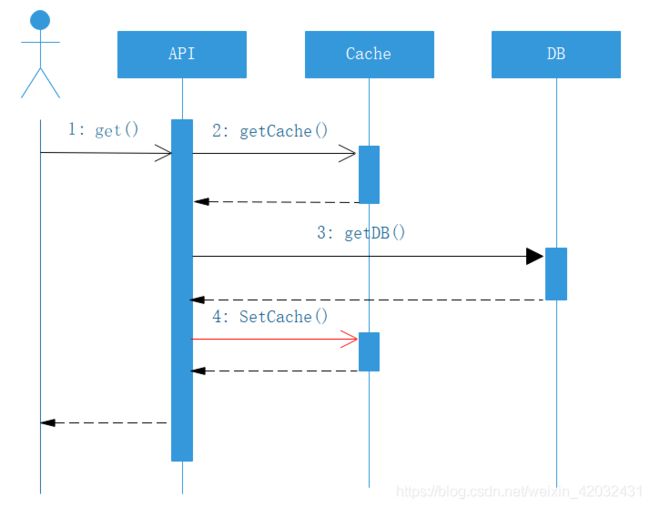
从缓存取不到的数据,在数据库中也没有取到,这时也可以在缓存中写入一个特殊值进行标记,缓存时间的设置可以视情况确定(如果主动清理可以设置长一点、否则短一点)
由于这种做法比较通用,故而在曲库封装的缓存代码中,将其通用化封装,即对于下面时序图,第四步进行设置:
实战场景2:扩容
扩容咋一看是比较简单的运维场景,但实际上也有很多考究,具体如下:
场景1:memcache容量不够
随着曲库数据量的逐步变大,memcache的占用量也越来越高,扩容memcache一个简单的做法,就是加机器节点,如果对于只有一组缓存(云音乐大部分都是这样),并且采用的是一致性哈希,需要在低峰期进行加节点(加的瞬间会有部分不命中);如果是普通哈希,则节点扩容风险非常高
曲库是一致性哈希,可以在低峰期加节点,但这里需要有一点需要注意,如果 MultiGet 的使用非常频繁,节点数的增加可能会导致性能下降
具体是什么原因呢?
我们使用Multiget一次性获取100个键对应的数据,系统最初只有一台Memcached服务器,随着数据量的增加,系统容量捉襟见肘,于是我们又增加了一台Memcached服务器,数据散列到两台服务器上,开始那100个键在两台服务器上各有50个,问题就在这里:原本只要访问一台服务器就能获取的数据,现在要访问两台服务器才能获取,服务器加的越多,需要访问的服务器就越多,所以问题不会改善,甚至还会恶化
从曲库的使用经验来看,底层节点控制在 4~6 个,性能与容量较为均衡
场景2:单组memcache性能达到上限
容量上解决后,还有就是memcache本身性能瓶颈,大部分场景下,我们系统的请求量达不到memcache的系统瓶颈。但假设memcache上限qps是20w,此时系统压力在 30w 该怎么做呢?
曲库侧的最佳实践,就是使用多组缓存,假设一组缓存的上限 qps,此时有两组一样数据内容的缓存,通过随机读的方式,是否上限能达到原来的两倍呢?
从这个思路出发,曲库进行了实践,实践的关键难点是:如何保障两组缓存数据是 一样 的呢?
这里设计了一个MemcacheManager的代理,所有的memcache操作均通过这个代理,而代理对于命令是:随机读、顺序写 的方式
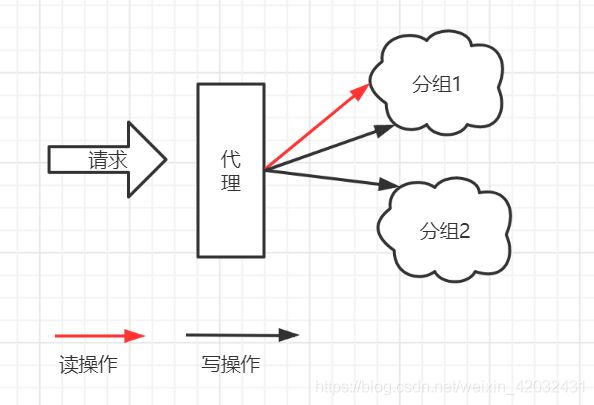
关于代理
本文在此处使用的代理,是本地的一种动态代理实现,用于增强MemcacheManager的使用,具体如下:
这里简化下,假设,云音乐MemcacheManager的接口定义如下:
public interface MemcacheManager {
public Object get(String key);
public boolean set(String key, Object value);
}
为了保持使用上一致,我们定义它的代理类 MemcachedSelect2ManagerImpl,但对于使用上进行增强,如下:
public class MemcachedSelect2ManagerImpl implements InvocationHandler, FactoryBean {
private final MemcachedSelector memcachedSelector = new MemcachedSelector(); // memcache选择器
...
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName(); // 根据方法名枚举,有限的方法名,如 Set/Get 等
boolean syncWrite = (this.writeSync || this.forceWriteSync) && this.writeSyncMethods.contains(methodName); //根据设置以及方法名 判断是否需要顺序写
if (syncWrite || syncMethods.contains(methodName)) {
return call(method, args, this.memcachedSelector.getMemcacheds()); // 拿到全部的memcache进行顺序操作执行
}
return call(method, args, this.memcachedSelector.select()); // 如果不需要顺序写,则选一个memcache 进行读
}
}
代理类大概上述实现
场景3:运维层面多组缓存如何扩容
上面说了一些理论层面的实践,实际过程中,使用多组缓存有个难点,从运维角度,如何加上新的分组呢?
如果直接添加一组空的缓存过去,则由于两组缓存瞬间是不对等的,如果此时就均匀访问,一定会引起很多超时,最初曲库是采用跑一遍曲库数据并设置Key-Value的方式,不过那样非常不灵活,过于大动干戈,后来通过在 场景2 中的代理类进行改造,通过设置缓存请求的比例来配置
如下,是曲库dg集群的缓存配置:
{
"writeSync":true, // 表示同步写以下各组缓存
"configs":[
{
"memcacheName":"music-rep2-g1-memcache_dg",
"servers":[
"music-memcache1.dg.163.org:11253"
],
"poolSize":16, // 连接数
"opTimeout":1000, // 超时时间
"rate":100, // 读比例
"codec":1, // 序列化方式 1 标识 Hessian
"hash":1 // 1表示使用一致性哈希
},
{
"memcacheName":"music-rep2-memcache_dg3",
"servers":[
"music-rep-g3-memcache1.dg.163.org:11253"
],
"poolSize":16, // 连接数
"opTimeout":1000, // 超时时间
"rate":100, // 读比例
"codec":1, // 序列化方式 1 标识 Hessian
"hash":1 // 1表示一致性哈希
}
]
}
通过设置rate值来控制每组缓存的请求量,当设置为 0 时,则只写入,无读请求,作为预热;然后根据预热情况,逐步从0调整至100
同样的,为了更好的做均衡,将缓存的健康度也引入考虑,按照响应时间进行缓存分组的选择,这也是曲库缓存代码实现的一些细节技巧
场景4:容量够、性能不够,如何使用多级缓存、本地缓存
对于缓存的使用,更极端的一个问题是,如果memcache缓存的qps上线是20w,此时有 2000w 的qps请求,并且这些请求的接口或数据较为集中(2-3个接口数据占了 40% 请求量),有没有更好的方式呢?
这里的表现,就是容量足够、性能不能满足的情况,按照上述分组的方式,按照这样的比例,需要10个分组甚至更多,这样存放全量数据,也是非常浪费的。
针对这个问题,曲库采用了加上一级本地缓存的两级缓存策略处理,具体如下:
- 在选择部署机器时,选择大内存的的云主机,并在云主机本身启动本地Memcache
- 把核心高请求量的接口结果用本地Memcache进行缓存,同样适用懒加载方式
为什么使用本地部署Memcache 而不是JVM内做内存缓存呢?
- Memcache进程与JVM进程隔离
- Memcache独立部署,监控、干预等各环节较简单(包括淘汰策略)
以曲库读为例,每台机器的本地缓存请求量已经接近 0.6w,单机房200台机器,本地缓存拦截到的调用总qps可达到 120w,如果这些调用全部到上述的分组缓存中,则硬件成本、代理的顺序写代价也是很高的。
结合实战场景3的防击穿设置,其时序图如下:

什么样的数据比较适合使用本地缓存呢?
- 调用量极高
- 仍然是读多写少、变化少
- 对象较小(因为本地缓存较小)
实战场景3:防止瞬间击穿
什么是瞬间击穿?
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发请求特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
这种的解决方式有多种,比如在请求数据库侧进行加锁、设置永不过期等(memcache最长30d)
曲库采用的是缓存穿刺的做法,具体是怎样的呢?
对于缓存中的 Key-Value ,将每个Value变成这样一个对象:
public static class HoleWrapper implements Serializable {
private long expire; // 对象的过期时间
private T target; // 对象本身
}
即每个在缓存中的对象,都带上自身的过期时间,这样在获取对象的时候,就知道缓存是否快过期了,如果能得到这个信息,结合业务特点 对于秒级延迟不敏感、热点数据集中,则可以这么进行设置,在曲库,我们称之为 穿刺 :
- 通过 key 获取 HoleWrapper
- 查看 HoleWrapper中的 expire 是否 快过期(快过期:可以定义5min、1h)
- 如果是,当前线程将获取到的 HoleWrapper 的 expire 时间延长,并放入缓存(此操作耗时较少)
- 当前线程向下穿透到下一层取数据,并将最新数据进行更新
时序图如下:
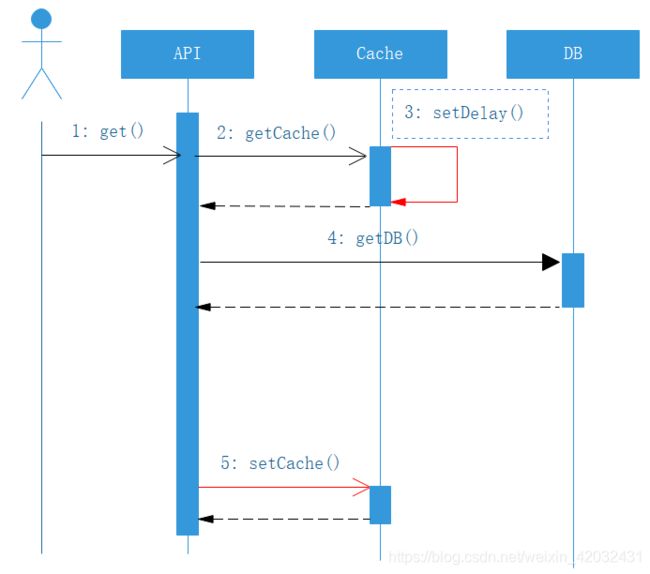
穿刺 体现在步骤3中,此处不能完全杜绝击穿的风险,但由于缓存操作远远快于DB操作,这样产生击穿的概率就下降了极多;有了穿刺,对于热点数据就能很好的做好防护,并且qps越高、越热点,越能体现优势。
实战场景4:缓存清理
缓存清理不是本篇内容的重点,不过曲库在实践中有个小技巧,在缓存 Key-Value 设计时一个遵循的原则:
- 所有的缓存清理,由于曲库数据支持秒级延迟的特点,可以进行异步清理
- 所有的缓存清理,由数据库变更(NDC消息)消息触发
- 所有关联的Key,可以由单条NDC生成
能满足上述3个原则,曲库缓存的清理就能变得比较轻巧,可以采用异步监听NDC消息的方式进行清理
总结
以上,是曲库缓存使用的实践历程,涉及的细节较多,不同业务场景可以参考不同的考虑方式进行部分借鉴
后续曲库缓存的发展方向,是将元数据中额MetaData数据与状态数据分开,并将MetaData数据进行纯静态化处理,结合业务数据变化的特点,将状态部分数据的降级等引入考虑,进行更深度的缓存使用
特别注意
从时序图也可以看到,曲库缓存通过分级、穿刺等设计,增加了缓存操作的链路,所以,假设缓存命中率不够高,会将平均路径变长,进而会导致耗时增长,并非所有场景都适合直接使用,需要各业务场景结合各业务特点进行合理的采纳思维进行推进
作者:廖祥俐
看到这里的小伙伴,如果你喜欢这篇文章的话,别忘了转发、收藏、留言互动!
如果你想知道更多大厂同学亲授的干货,可以私信我!
还有新整理的海量资料,包含面经分享、模拟试题、视频干货…… 需要1V1的学习规划、职业规划也可以加V(weizhuanye234)
