Spark执行原理概述
Spark优点
- 速度快
基于内存的计算比MapReduce快100倍以上; - 简单易用
支持多种语言API,快速构建不同应用; - 通用
提供统一的解决方案:SQL、Streaming、MLib、GraphX; - 可融合
资源管理和调度:YARN、Mesos;
数据存储:HDFS、HBase;
整体架构

整体上架构有三部分组成 Master、 Work和 Client,它们之间通过akka通信,具体的职责如下:
- Master:管理Worker,向Worker提交Application;
- Work:根据Master发送的Application,启动ExecutorBackend;
- Client:向Master注册并监控Application;

它们之间的消息传递:
- Master -> Worker:响应Worker注册、Worker重新注册、让Worker启动(停止)Executor和Driver;
- Worker -> Master:注册Worker、汇报Executor和Driver的运行状态、汇报心跳;
- Master -> Driver Client:响应Driver的注册状态、KillDriver的结果、查询Driver当前的运行状态;
- Driver Client -> Master:提交Driver、KillDriver、获取Driver的运行状态;
- Master -> AppClient(ClientActor):回复Application注册结果、告诉AppClient Worker启动了Executor和Executor状态更新了、ApplicationRemoved、Master故障恢复;
- AppClient(ClientActor) -> Master:注册Application、响应Master的故障恢复;
- Executor-> Driver:注册Executor、汇报Executor中运行的Task状态;
- Driver-> Executor:启动(停止)Task、响应Executor的注册请求
任务调度

DAGScheduler

当最后一个RDD(finalRDD)触发action操作之后,调用
SparkContext#runJob,然后调用
DAGScheduler#handleJobSubmitted完成整个job的提交。
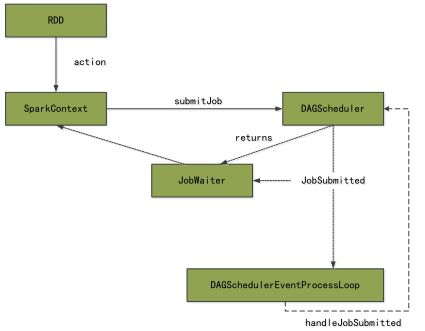

DAGScheduler将Job从后往前的回溯划分多个 Stage,根据宽依赖中的 ShuffleDependency生成ParentStage,每个Stage由多个逻辑完全相同的、并行执行的Task组成,只是每个Task处理的数据不同。DAGScheduler通过 TaskSet的方式,把其构造的所有Task提交给底层调度器TaskScheduler。
调用链路:
DAGScheduler#handleJobSubmitted
-> DAGScheduler#submitStage // 递归地将finalStage依赖的父stage先提交,最后提交finalStage
-> DAGScheduler#submitMissingTasks //ShuffleMapStage或者ResultStage创建ShuffleMapTask或ResultTask,即TaskSet
-> TaskScheduler#submitTasksTaskSchedulerImpl

TaskScheduler是一个与具体资源调度解耦合的接口,目前资源调度模式主要有:StandAlone(TaskSchedulerImpl)、Yarn、Mesos、Local、EC2或者其他自定义的资源调度器。
TaskScheduler负责Application的不同Job之间的调度、在Task执行失败重启以及为慢Task启动备份任务。
TaskScheduler#submitTasks是将TaskSet加入到TaskSetManager中进行管理。
SchedulerBuilder#addTaskSetManger确定TaskSetManager的调度顺序,然后按照TaskSetManager的本地特性确定每个Task具体运行在那个ExecutorBackend中。
TaskScheduler通过SparkDeploySchedulerBackend创建AppClient,而AppClient(ClientActor)向Standalone的Master注册Application,然后Master会通过Application的信息为它分配Worker,包括每个worker上使用CPU core的数目等。
CoarseGrainedSchedulerBackend

CoarseGrainedSchedulerBackend负责于Cluster Manager交互,负责收集Worker上的计算资源(Executor),并将这些资源传递给TaskSchedulerImpl,由它为Task最终分配资源。Standalone模式下,继承CoarseGrainedSchedulerBackend的SparkDeploySchedulerBackend负责集群资源的获取和调度。
SparkDeploySchedulerBackend#start 启动创建AppClient,
AppClient#start启动创建ClientEndPoint(ClientActor),ClientActor向Master注册当前Application;同时SparkDeploySchedulerBackend的父类CoarseGrainedSchedulerBackend启动的时候会创建DriverEndPoint(DriverActor),当CoarseGrainedExecutorBackend启动的时候向DriverActor注册,SparkDeploySchedulerBackend就获取了当前Application拥有的计算资源,TaskSchedulerImpl通过SparkDeploySchedulerBackend获取的计算资源运行Task。
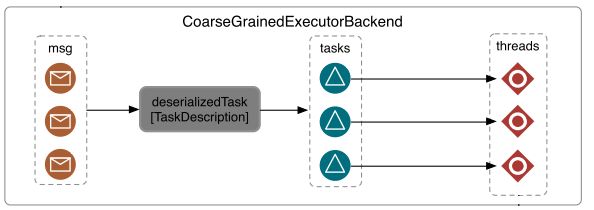
对应到代码当中,CoarseGrainedSchedulerBackend的输入是Executor列表,输出是TaskDescription(Task Id、Executor Id和Task执行环境的依赖信息)二维数组。最后,
CoarseGrainedSchedulerBackend.DriverActor#launchTasks将分配到Executor的Task进行分配;
调用链路:
TaskSchedulerImpl#submitTasks //
-> CoarseGrainedSchedulerBackend#reviveOffers // 发送ReviveOffers消息
-> CoarseGrainedSchedulerBackend.DriverActor#makeOffers // 处理发送来的ReviveOffers消息,WorkOffer表示Executor上可用的资源
-> TaskSchedulerImpl#resourceOffers // 为Task运行分配资源
-> CoarseGrainedSchedulerBackend.DriverActor#launchTasks // 启动Task的运行CoarseGrainedExecutorBackend
前面提到,ClientActor向Master注册当前Application,Master根据AppClient提交为Application分配资源选择Worker(Executor)。在选择Worker和确定Executor需要的CPU cores数量之后,Master向Worker发送LaunchExecutor请求,向ClientActor发送Executor已添加的消息,同时更新Master中的Worker信息。
Worker接收到来自Master的LaunchExecutor的消息后,会创建ExecutorRunner。ExecutorRunner会将SparkDeploySchedulerBackend中准备好的ApplicationDescription(CoarseGrainedExecutorBackend)以进程的形式启动起来,CoarseGrainedExecutorBackend启动后,通过传入的driverUrl向在CoarseGrainedSchedulerBackend.DriverActor发送RegisterExecutor,DriverActor接受到RegisterExecutor消息之后,将Executor的信息保存下来,并通过
CoarseGrainedExecutorBackend.DriverActor#launchTasks 实现在Executor上启动Task,同时DriverActor回复RegisteredExecutor,此时CoarseGrainedExecutorBackend收到RegisteredExecutor,会创建一个Executor。
Task

Executor为每个Task生成一个TaskRunner,TaskRunner最终放到ThreadPool中执行,调用Task的run方法来获得任务执行的结果。
ShuffleMapTask#runTask调用RDD的iterator()计算Task,ResultTask计算过程与之类似。区别:
ShuffleMapTask#runTask在计算具体的partition后实际上会通过shuffleManager把当前Task的计算结果写入到具体的文件中,操作结束后会把MapStatus发送给DAGScheduler;而
ResultTask#runTask会根据前面Stage的执行结果进行Shuffle,产生整个Job最后的结果。
CoarseGrainedSchedulerBackend#launchTasks
-> CoarseGrainedExecutorBackend#launchTask
-> TaskRunner#run
-> Task#run
-> ResultTask#runTask
-> RDD#iterator参考资料:
- Spark技术内幕:Executor分配详解
- Spark系统运行内幕机制循环流程
- 玄畅,图解Spark core.