【数据挖掘】视频版权检测优胜解决方案
CCF-BDCI 视频版权检测
随着移动互联网的发展和智能手机的普及,短视频已经成为重要的信息传播媒介,与此同时也带来了大量针对版权长视频的侵权行为。为了保护视频制作公司及原创者权益,需要通过自动化方式进行针对短视频的侵权行为检测。当前的侵权行为出现多样化及规模化特点,侵权视频多经过复合变换,要求算法模型中图像特征具有一定鲁棒性,并且有较快执行速度和并发能力。
赛题介绍
本次竞赛将考察经过复合变换后的短视频关联到对应长视频的算法效果,其中不仅要找到短视频的原始长视频,还要计算出对应的时间段。过程中可能包括视频解码抽帧、视频或图像特征及指纹、视频相似检索等相关算法及技术方案。除了考察视频特征的鲁棒性外,也需要算法模型有一定的实时及并发能力。
比赛链接:
https://www.datafountain.cn/competitions/354

refer版权库视频

query侵权视频
对于query侵权视频,可能会进行如下变换操作:
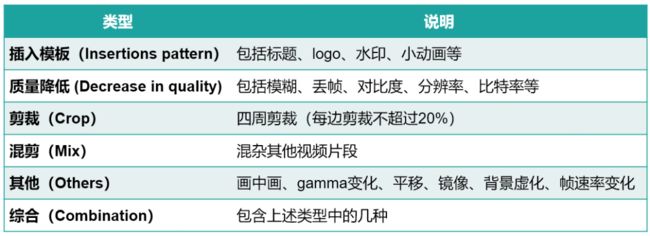
赛题的任务需要根据query找到refer,并且找到query中侵权部分与refer中对应的关系。如下图橙色部分为侵权部分,需要确定query视频中q_start和q_end位置,以及refer视频中的r_start和r_end位置。
Top1 恒扬数据
视频版权监测赛题的核心任务是在两个视频中找出内容相同,画面相似的视频片段(即拷贝片段),拷贝片段长度是几十秒至几分钟的视频图像。所谓内容相同是指指观看者看到的语义信息相同。画面相似包括不同形式的图像变形,如画面剪裁,饱和度改变,加字幕和LOGO,视频剪辑等处理。
竞赛任务有三个数据集:参考集,训练集和测试集。参考集是版权视频,有205个视频文件,平均时长为40分钟。训练集和测试集都是2至4分钟的视频片段,其中的拷贝片段只有1分钟,嵌入在片段的头部或中部。竞赛要求为每个查询视频(训练集或测试集)包含的拷贝片段找到参考集对应的视频文件和两个拷贝关系片段的开始时间和结束时间。
赛题的挑战和难点在于视频的变形程度,本次比赛中最难的变形是某些视频做了大幅度的裁剪:比如原视频有两个主持人,被裁成了一个,还有的视频把整个人的画面裁成只剩一只手等等。

参考集提取到视频特征向量后构建视频版权库,训练集和测试集的图片特征向量在版权库里面查找最近邻的图片特征向量(L2距离计算),返回前top-k个近邻值,然后通过视频匹配算法得到最终的匹配结果,该思路涉及到三个主要的算法:图片特征提取算法,搜索算法,视频匹配算法。
特征提取算法:提出一个卷积层特征+Gaussian_R-MAC的特征提取方法,增加中央部分的图像权重,这种方法能够有效解决裁剪和画面质量下降等变形;

视频匹配算法:根据每个侵权视频的图片在版权库中搜索返回的top-k最近邻进行视频匹配。

针对裁剪严重这一类情况,最初的思路是,只捕捉画面中央部分的特征,应该能大大提升算法的识别能力。但是通过实践证明只捕捉中央部分是行不通的,而应该改为加强图片中央部分特征的权重,同时降低周围区域特征的权重。最终在原算法的基础上引入二维高斯分布+RMAC算法,一举将成绩提升10几个百分点,分数直升95分。
Top2 博云视觉

此次参赛的视频检索方案的核心思想和算法流程是基于博云视觉团队在2019年刚刚完成的CDVA国际标准而制定的。在此基础上,博云视觉团队针对这次比赛对其进行了一定的改进。总体来说,博云视觉团队对查询视频和参考视频进行了关键帧识别、基于关键帧的CDVS手工设计特征和深度特征提取,并基于这些特征进行视频的检索匹配,最终生成具有匹配得分的视频对集合。
为了精准对齐视频对的帧序列时间节点,博云视觉团队设计了基于CDVS特征的时序节点滤波方法,该方法以CDVS特征为基础,融合帧排序、时间节点噪声抑制、对双视频序列进行相关滤波从而得到视频对的对齐节点,完成精准的时序匹配。
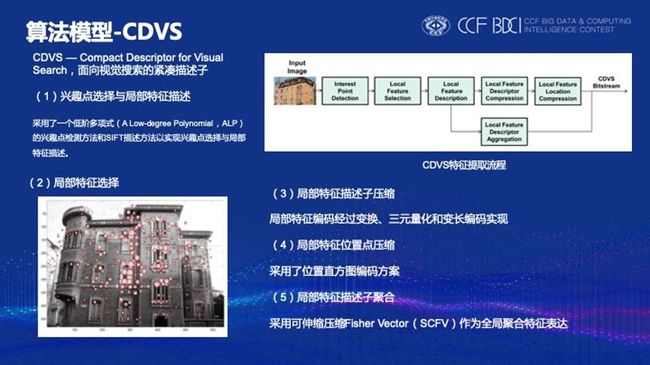
下面详细介绍该算法方案中使用到的相关技术,CDVS是“面向视觉搜索的紧凑描述子”,是类似于sift的手工特征,该特征可用于单张图像的检索和匹配。其提取包括5个流程,兴趣点的选择与局部特征描述,局部特征选择,局部特征描述子压缩,局部特征位置点压缩,最后进行局部特征描述子聚合。博云视觉团队设计的CDVS特征基于GPU,单机每秒可提取200张图像特征,特征大小为可伸缩的,可以实现512byte到16K不同特征大小的交叉匹配。

CDVA是“面向视频分析的紧凑描述子”,旨在对视频进行匹配、检索任务,是CDVS图像搜索的拓展。博云视觉团队首先使用颜色直方图完成视频关键帧的快速定位,此后基于关键帧,结合NIP深度特征和CDVS手工设计特征实现精准的帧级视频对匹配,从而快速地完成视频序列匹配任务。同时,从上图(右下)可以看到,深度特征对图像的旋转角度非常敏感,(红色曲线为深度特征在两个数据集上的检索性能,横轴为旋转角度,)当旋转一定角度后,深度特征检索性能明显下降;

Top3 小贾的老梁
构建参考视频帧级特征库,之后使用短视频的帧特征在特征库中进行检索通过匹配策略找到长视频,再逐帧比对特征确定侵权段,方案由特征提取、被侵权视频检索,被侵权视频段定位三部分组成。在特征提取阶段中,老梁团队采用Hessian Affine特征提取+SIFT描述子提取局部特征,然后采用Fisher vector将局部特征编码为二进制的全局特征。之前的工作证明,用该方式提取特征具有很好的区分度和鲁棒性。
其次,为了排除同时处理多个参考长视频对检测定位精度的影响,老梁将整个版权检测过程分为两个阶段:在第一阶段中,他采用求带权二部图的最大匹配的方式,找到与查询短视频能在一对一帧匹配的约束下,匹配权重和最大的长视频。之后在该长视频中,通过找到在密集匹配约束下的最长递增子序列来精确定位侵权段,即在该阶段匹配帧对时,不仅要求其满足一对一的约束关系,同时要满足匹配在时间上的顺序性和密集性。

然后,使用求带权二部图的最大匹配的思路寻找被侵权视频,即在一对一的帧匹配的限定条件下,对检索到的参考视频集中的每个参考视频段,求其与查询视频段形成的带权二分图中的最大匹配。将匹配权重和最大的参考视频作为被侵权视频。
Top4 葫芦兄弟
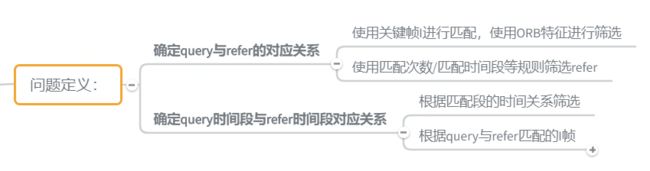
根据赛题任务要求,赛题具体任务为根据query视频找到对应的refer视频,并且找到query视频中qstart与qend时间与对应refer视频中的rstart与rend时间。因此赛题任务具体可以分为两个子任务:
(1) 视频对应:根据query视频找到对应的refer视频;
(2) 视频时间轴对应:找到query视频中qstart与qend时间与对应refer视频中的rstart与rend时间;
根据问题子任务的对应关系,问题整体的解决思路如下:
在现有的图像检索技术中CNN特征是非常有效的特征,其利用GPU加速可使提取速度增快,且对图像的内容语义进行编码,是非常适合用于图像检索的特征。在query视频与refer视频的对应任务中就是利用视频关键帧的CNN特征完成检索过程,具体过程步骤如下:
(1)对query视频关键帧提取ResNet18网络的卷积特征,并进行L2正则化;对refer视频关键帧提取ResNet18网络的卷积特征,并进行L2正则化;
(2.1 最初版)对于每一个query视频关键帧,利用其CNN特征在refer视频关键帧中搜索得到最相似的refer视频关键帧,且关键帧之间的相似度大于阈值;
(2.2 改进版)对于每一个query视频关键帧,利用其CNN特征在refer视频关键帧中搜索得到最相似Top100的refer视频关键帧,且关键帧之间的相似度小于阈值。进而将query视频关键帧与refer视频关键帧进行ORB关键点匹配进行二次筛选;
(3)对于同一个query视频,将该视频的关键帧搜索得到的refer视频关键帧进行筛选,利用refer视频次数以及关键帧相似度两个角度筛选得到;
利用上述步骤,就可以完成找到query视频与refer视频的对应关系。在具体实践步骤中使用了HNSW库来完成CNN特征的近似搜索,最终在训练集上query视频与refer视频的对应准确率为2650/3000。

Top5 颜值均值98方差100
算法流程具体主要分为三个部分:视频解帧、特征提取、以及检索比对算法设计。
在视频解帧方面,主要介绍北航团队针对比赛数据设计的视频帧采样方案,也包含了部分观察比赛数据特点方面的探索。
在特征提取方面,将简单介绍北航团队针对视频中部分噪音的针对性图像处理方案,以及为了节约计算成本和计算资源而采用的特征提取方案。
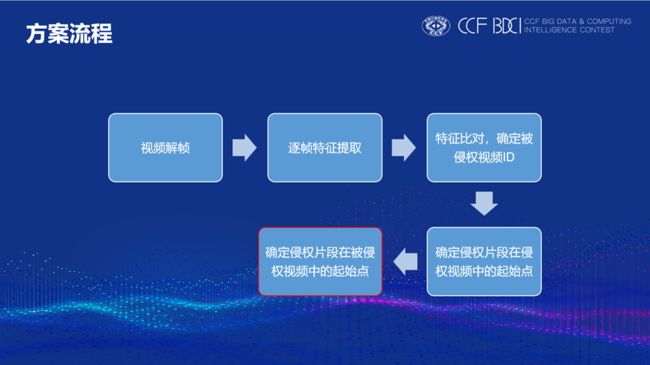
检索比对工作在得到每段视频的所有帧特征之后开始进行。检索比对工作主要分为三个部分,对于每段查询视频:首先,确认其涉嫌抄袭的refer集;其次,需确认其抄袭的片段在查询视频中的起始点;最后,确认抄袭片段在检索视频中的起始点。具体流程如下:

总结
前五名的思路大体类似,具体在特征提取提取方式上有一些差异:
Top1:使用CNN浅层特征 + RMAC
Top2:深度局部特征CVDS
Top3:SIFT + 匹配二分图
Top4:CNN + 关键帧匹配
Top5:CNN + 相似度矩阵
完整的Top5队伍的分享讲义,
关注作者公众号并回复【视频版权】

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看
让我知道你在看
