Hadoop伪分布式模式搭建
首先必须保证单机模式能如上一篇文章一样运行起来!
1:进入Hadoop安装目录/etc/hadoop/
[root@bigdata128 hadoop-2.7.3]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@bigdata128 hadoop-2.7.3]# cd etc
[root@bigdata128 etc]# ls
hadoop
[root@bigdata128 etc]# cd hadoop
[root@bigdata128 hadoop]#
2:运行
[root@bigdata128 hadoop]# vi core-site.xml
添加下面内容
fs.defaultFS
hdfs://bigdata128:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.3/tmp
运行
hdfs-site.xml
添加
dfs.replication
1
dfs.namenode.secondary.http-address
bigdata128:50070
运行
mapred-site.xml
(该配置文件不存在,先复制)
运行
cp mapred-site.xml.template mapred-site.xml
添加
mapreduce.framework.name
yarn
④yarn-site.xml
yarn.resourcemanager.hostname
bigdata128
yarn.nodemanager.aux-services
mapreduce_shuffle
Slaves文件里使用默认localhost,或者添加 bigdata128(既是NameNode又是DataNode)
注:如果Slaves文件为空,就没有DataNode和NodeManager。
修改\etc\hosts配置文件
运行命令
vi \etc hosts
注释掉已有内容,添加虚拟机的ip及对应主机名:
192.168.163.128 bigdata128
修改\etc\hostname配置文件,运行命令
vi \etc hostname
添加虚拟机的主机名:
bigdata128
重启虚拟机,主机名生效。
3:格式化(必须进入到/opt/module/hadoop-2.7.3/bin目录)
hdfs namenode -format
成功如图:
4:启动(/opt/module/hadoop-2.7.3/sbin)
start-all.sh
成功如图所示(该过程中需要输入“yes”,以及虚拟机密码):
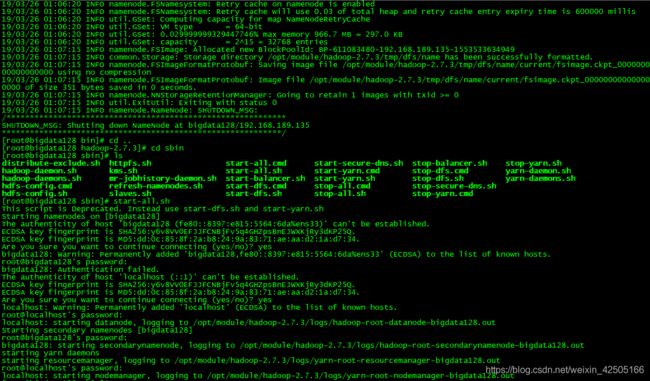
执行jps,如下图所示,NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager如果全部启动,伪分布式配置成功。
![]()
浏览器访问(注意时http不是https):http://192.168.189.135:50070 、http://192.168.189.135:8088


页面正常显示,则成功。
运行wordcount
在hdfs文件系统中创建input目录
hadoop fs -mkdir /input
进入mapreduce目录中把上次教程创建的in.txt文件上传到hdfs文件系统的input目录中
hdfs dfs -put in.txt /input
成功后可视化界面可看

运行
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/in.txt output/
成功界面如下:

执行:
hdfs dfs -ls /
显示如下多了一个user文件夹,其实在user文件夹下面还有一个root文件夹,在该文件夹下面会创建一个output文件夹,在该文件夹下面part-r-00000就是输出文件:

输出文件如下:
hdfs dfs -cat /user/root/output/part-r-00000
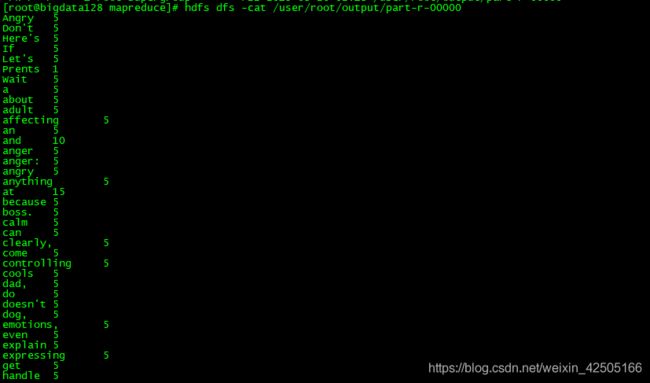
浏览器:
到此,伪分布式搭建完毕,欢迎咨询、留言,晚安!!!
2019 3.26 2:25