flume 架构规划
具备缓冲数据峰值的能力
规划满足处理瞬时故障所需的容量
====
Flume 单层架构
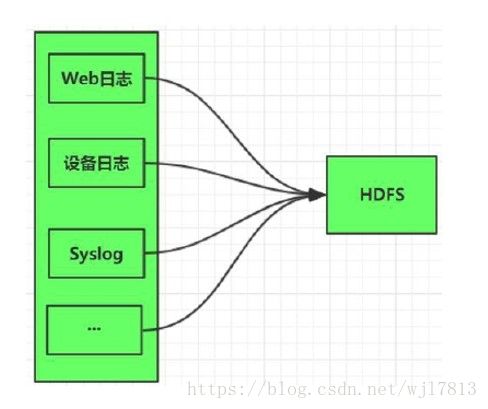
1. 架构简单
2. 配置管理复杂, 维护难度大
3. HDFS频繁写, 小文件多, HDFS压力大
4. 安全性差
5 flume 升级比较麻烦
=====Flume 分层架构==

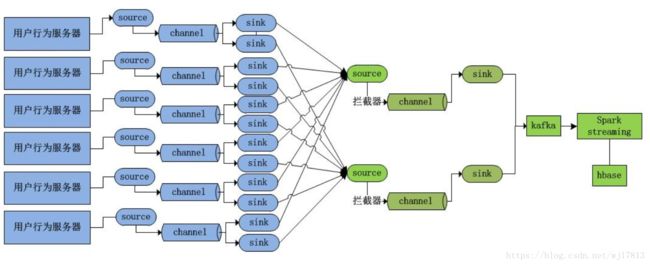
1. 安全性
汇聚层的Agent(Collector1与Collector2、
Collector3与Collector4)做负载均衡、高可用
2. HDFS小文件
汇聚层汇聚第一层多个Agent的event。
3. 扩展性、可用性
4. 升级维护
HDFS升级维护等, 只需要维护汇聚层的Agent
=========================
规划-规划每层节点数量=====
经验法则:
每4-16台agent做一层聚合Agent
根据每个聚合Agent的数据摄取能力。
理论上:最大的agent数量基于将网络带宽跑满。
最外层agent比可高达100:1
内层大幅减少agent数量
需要考虑Load Balancing、Failover
案例: 从100台Web Server 收集日志
1. 第一层:按照1:16规划agent数量, 不考虑load
balancing和failover。
第一层的agent数量: 100/16 =7.
2. 中间层:按照1:4规划agent数量, 不考虑load
balancing和failover。
第二层的agent数量:7/4 =2.
合计:两层, 9个Agent。
规划每层节点数量

规划- Sink Batch Size
基于前面的拓扑, 以Agent1为例:
考虑到稳定性, agent1能处理的最大event数量为1600个。
Agent1
1. 在一个周期内, 每台web server发送了100个event。
2. Agent1的接收的event数量:16*100=1600个,Agent1的出口event数量
3. 如果web Server的event变大, agent1的 出口event数量增加到2500个, 那么这个时候使用mutilple sinks。
Collector1
1. 从上游4个Agent接收数据, 每批次数据量: 4 * 1600 = 6400个。
2. 将 6400个分成3个sink, 每个sink的batch size为2150.
sink的batch size越大, 数据重复的风险就越大, 因为Flume只能保证每个event被推送到至少一个sink。
规划-Channel Capacity
Channel容量规划
根据故障处理要求规划,下游故障, 导致channel驻留大量的event
Channel选择
- Memory: 传输速度快, 可靠性差
- File: 数据持久化到磁盘, 数据不会丢失。重启断点续传。
- Kafka Channel: 传输速度快,安全可靠。
File Channel Capacity规划
假设能够容忍的下游故障处理时间为1个小时。
1个agent的传输event速率为100个/秒。
1个小时的event数为: 1*60*60*100 = 360000
File的磁盘容量需要满足360000个event的存储, 从安全性考虑, 设计File的磁盘容量
为360000*1.5=540000个event的容量。
Kafka Channel的规划
假设能够容忍的下游故障处理时间为1个小时
Kafka的segment配置保留时间大于1个小时。 从安全性考虑,适当增大。
Kafka的segment配置保留字节大小大于540000个event的容量。
规划-硬件
CPU核心数:(Source数量 + Sink数量)/ 2
如果使用Memory Channel, 尽量配置比较大的内存
如果使用File Channel, 磁盘越多, 吞吐量越大
参考引用文章链接:
https://tech.meituan.com/mt-log-system-arch.html
https://tech.meituan.com/mt-log-system-optimization.html
http://shiyanjun.cn/archives/1497.html