Java对象内存布局(JOL)
前言
Java对象的内存布局主要由对象头(Object Header)、实例数据(instance data)、对齐填充(padding)三部分组成。

- 对象头:存储对象的基础信息(如锁状态、GC状态、元数据等),12byte
- 实例数据:存储对象实例数据
- 对齐填充:如果对象存储的字节数并非8的倍数,则将存储字节数填充到8的倍数以便对象的查找
HotSpot JVM使用称为oops(Ordinary Object Pointers-普通对象指针)的数据结构来表示指向对象的指针,这些oop相当于本机C指针,JVM中的所有指针(对象和数组)均基于称为oopDesc的特殊数据结构。 每个oopDesc使用mark word与可能压缩了的klass word描述指针,oopDesc的结构定义在oop.hpp文件中,oop.hpp部分源码如下:
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
}
instanceOops是用于表示Java普通对象实例的一种特殊oop,此外VM还支持保留在OpenJDK源代码树中的其他一些oop。instanceOop的内存布局很简单:它只是对象头,后面紧跟零个或多个对实例字段的引用。
对象头 - Object Header
对象头是每个GC管理的堆对象的起始通用结构,包含了JVM中堆对象的布局、类型、GC状态、同步状态和标识哈希代码的基本信息。对象头在JVM中主要由以下几部分组成:
- 一个具有多种用途的标记字mark word
- 一个可能压缩过的klass word(也称klass pointer),代表指向类元数据(属性、方法等)的指针
- 可能存在的32位数组长度标记,用于表示数组对象长度(只有arrayOop有)
- 一个可能存在的32位间隙来强制对象对齐
对于Java中的普通实例(表示为instanceOop),对象标头由mark和klass词以及可能的对齐填充组成。在对象头之后,可能有零个或多个对实例字段的引用(instance data)。word(mark word、klass word)是当前机器上的词,因此在传统的32位计算机上是32位,在更现代的系统上是64位。因此在64位体系结构中,一个对象至少有16个字节,包括8个字节的mark word,至少4个字节的klass word和4个填充字节。
mark word
mark word是每个对象头的第一个词,通常是一组位域,包括同步状态和标识哈希码,也可以是指向同步相关信息的指针(具有特征低位编码)。HotSpot JVM使用此词来存储身份哈希码,偏向锁标志,锁信息和GC元数据。mark word主要包含以下组成部分:
- unused:未使用空间
- identity_hashcode:对象哈希识别码,当我们不为类声明
hashCode()方法时,Java将为其使用身份哈希码。身份哈希码在对象的生存期内不会更改,因此,HotSpot JVM一旦计算出该值,便会将其存储在标记字中。 - age:分代年龄(4bit即最大值为15,即MaxTenuringThreshold最大为15),每次垃圾回收幸存后都会自增,当达到新生代的最大维持阈值(XX:MaxTenuringThreshold)后就会迁移到老年代
- biased_lock:偏向锁标志,0-无偏向锁,1-偏向锁
- lock:锁标志,00-轻量锁,01-解锁或偏向锁,10-重量锁,11-GC标记
- thread:偏向锁记录的线程标识
- epoch:充当时间戳,验证偏向锁的有效性
- ptr_to_lock_record:轻量锁指在无需争抢锁的情况下,JVM使用原子操作而不是OS(操作系统)互斥锁,这种技术称为轻量级锁定。对于轻量锁,JVM通过CAS操作在对象的header中设置一个指向锁定记录的指针。
- ptr_to_heavyweight_monitor:如果两个不同的线程在同一个对象上并发同步,则必须将轻量级锁膨胀为一个重量级监视器来管理等待的线程。对于重量锁,JVM在对象header中设置一个指向监视器的指针。
klass word(klass pointer)
每个对象头的第二个词,代表指向类元数据(属性、方法等)的指针,在Java 7之前保存在永久代(Permanent Generation),在Java 8之后保存在元空间(Metaspace),虚拟机通过该指针来确定这个对象是哪个类(Class)的实例。
不同情况下的Object Header
- 32位JVM下的ObjectHeader
|----------------------------------------------------------------------------------------|--------------------
| Object Header (64 bits) | State
|-------------------------------------------------------|--------------------------------|--------------------
| Mark Word (32 bits) | Klass Word (32 bits) |
|-------------------------------------------------------|--------------------------------|--------------------
| identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 正常(无状态)
|-------------------------------------------------------|--------------------------------|--------------------
| thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 偏向锁
|-------------------------------------------------------|--------------------------------|--------------------
| ptr_to_lock_record:30 | lock:2 | OOP to metadata object | 轻量锁
|-------------------------------------------------------|--------------------------------|--------------------
| ptr_to_heavyweight_monitor:30 | lock:2 | OOP to metadata object | 重量锁
|-------------------------------------------------------|--------------------------------|--------------------
| | lock:2 | OOP to metadata object | GC标记
|-------------------------------------------------------|--------------------------------|--------------------
- 64位JVM下的Object Header
|------------------------------------------------------------------------------------------------------------|--------------------
| Object Header (128 bits) | State
|------------------------------------------------------------------------------|-----------------------------|--------------------
| mark word (64 bits) | klass word (64 bits) |
|------------------------------------------------------------------------------|-----------------------------|--------------------
| unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 正常(无状态)
|------------------------------------------------------------------------------|-----------------------------|--------------------
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | 偏向锁
|------------------------------------------------------------------------------|-----------------------------|--------------------
| ptr_to_lock_record:62 | lock:2 | OOP to metadata object | 轻量锁
|------------------------------------------------------------------------------|-----------------------------|--------------------
| ptr_to_heavyweight_monitor:62 | lock:2 | OOP to metadata object | 重量锁
|------------------------------------------------------------------------------|-----------------------------|--------------------
| | lock:2 | OOP to metadata object | GC标记
|------------------------------------------------------------------------------|-----------------------------|--------------------
- 64位JVM下压缩指针的Object Header
|--------------------------------------------------------------------------------------------------------------|--------------------|
| Object Header (96 bits) | State |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| Mark Word (64 bits) | Klass Word (32 bits) | |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| unused:25 | identity_hashcode:31 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Normal |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| thread:54 | epoch:2 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Biased |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| ptr_to_lock_record | lock:2 | OOP to metadata object | Lightweight Locked |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| ptr_to_heavyweight_monitor | lock:2 | OOP to metadata object | Heavyweight Locked |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
| | lock:2 | OOP to metadata object | Marked for GC |
|--------------------------------------------------------------------------------|-----------------------------|--------------------|
对齐填充
对齐填充指JVM将填充添加到对象末尾,以便它们的大小是8字节的倍数,使用这些填充,oops的最后三位始终为零(8的倍数在二进制中末尾始终表示为000)。
CPU的位数代表着CPU一次性能够处理的数据的位数,32位代表cpu能够处理32位的数据,就是4个字节的大小,64位cpu代表cpu一次性能够处理64位的数据,也就是8个字节大小的数据。前面提到一个对象至少有16个字节,当对象在内存中所占的字节大小并非8的倍数时,JVM会填充0到对象末尾使对象内存大小为8字节的倍数,这样可以方便CPU在内存中查找所需的对象。
由于JVM已经知道后三位始终为零,因此将那些无关紧要的0存储在堆中毫无意义,所以JVM并不会把填充存到堆中。
- 当JVM需要在内存中查找对象时,会将指针左移3位
- 另一方面,当JVM加载指向堆的指针时,JVM将指针向右移动3位以丢弃填充的0。
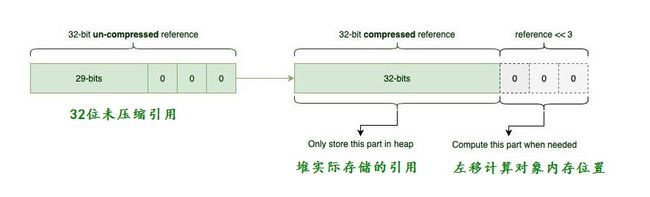
指针压缩Coops - Compressed OOPs
压缩指针主要是对类元数据指针(oopDesc.hpp中的_metadata)进行压缩。
-
为什么32位JVM限制为堆大小为4GB?
在32位计算机中,oops只有32bit,只能引用4GB(2^32bit)的内存。同样的限制也适用于操作系统级别,这就是为什么任何32位进程都被限制为4GB的地址空间。当oops的长度为64位时,它们可以引用TB级别的内存。
-
为什么需要指针压缩?
假设我们要从传统的32位体系结构切换到更现代的64位计算机,一开始我们可能期望立即得到性能提升。然而,当涉及到JVM时,情况并不总是如此。造成这种性能下降的主要原因是64位对象引用,64位引用占用32位引用的两倍空间,因此这通常会导致更多内存消耗和更频繁的GC周期。专门用于GC周期的时间越多,应用程序线程的CPU执行片段就越少。
那么我们应该切换回去,再次使用那些32位体系结构吗?即使这是一个选项,如果没有更多的工作,32位进程空间中的堆空间不能超过4GB。实际上,JVM可以通过**压缩对象指针(Compressed OOPs)**来避免浪费内存,这就可以两全其美:在64位机器中,允许32位引用的堆空间超过4GB!
-
哪些oop会被压缩?
- 每个oop中的klass字段
- 每个oop实例字段
- objArray中的每个元素
从Java7开始,当最大堆内存小于32GB时,默认会启用指针压缩;当最大堆内存大于32GB时,JVM将自动关闭指针压缩。压缩指针开关的VM参数如下:
- 开启指针压缩(默认):
-XX:+UseCompressedOops - 关闭指针压缩:
-XX:-UseCompressedOops
内存布局测试示例
检查JVM中对象的内存布局可以使用JOL(Java Object Layout - java)工具依赖:
org.openjdk.jol
jol-core
0.10
默认压缩指针测试用例
代码示例
@Data
@NoArgsConstructor
@AllArgsConstructor
public class LongVO {
private long val;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class IntegerVO {
private int val;
}
public class ObjectLayoutTest {
public static void main(String[] args) {
System.err.println("-------------------------VM details-------------------------------");
System.out.println(VM.current().details());
System.err.println("-------------------------Object details-------------------------------");
System.out.println(ClassLayout.parseInstance(new LongVO(1)).toPrintable());
System.out.println(ClassLayout.parseInstance(new LongVO(2)).toPrintable());
System.out.println(ClassLayout.parseInstance(new IntegerVO(1)).toPrintable());
}
}
控制台打印
-------------------------VM details-------------------------------
# Running 64-bit HotSpot VM. // 正在运行64位HotSpot VM
# Using compressed oop with 3-bit shift. // 正使用3bit填充压缩oop
# Using compressed klass with 3-bit shift. // 正使用3bit填充压缩klass
# Objects are 8 bytes aligned. // 对象以8字节对齐
// 按类型划分的字段大小: 引用占4字节,boolean、byte占1字节,short、char占2字节,int、float占4字节,long、double占8字节
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
// 数组元素大小,同上
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
-------------------------Object details-------------------------------
io.wilson.basic.LongVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 92 c3 00 f8 (10010010 11000011 00000000 11111000) (-134167662)
12 4 (alignment/padding gap)
16 8 long LongVO.val 1
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
io.wilson.basic.LongVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 92 c3 00 f8 (10010010 11000011 00000000 11111000) (-134167662)
12 4 (alignment/padding gap)
16 8 long LongVO.val 2
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
io.wilson.basic.IntegerVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) ed ce 00 f8 (11101101 11001110 00000000 11111000) (-134164755)
12 4 int IntegerVO.val 1
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
JVM默认使用了压缩指针,klass pointer会被压缩为4bytes(32位),例子中的LongVO对象头占了12字节(mark word 8bytes + klass word 4bytes),vo实例数据中的long类型占8个字节,对齐填充占4字节使对象内存占用为8的倍数24bytes(可以通过-XX:ObjectAlignmentInBytes=16调整默认的对齐大小为16bytes的倍数),且2个LongVO的klass pointer(类元数据指针)都是相同的92 c3 00 f8。
IntegerVO中的int类型只占4bytes,加上header的12bytes刚好16bytes为8bytes的倍数,所以无需填充对齐。
禁用压缩指针测试用例(VM options -XX:-UseCompressedOops)
代码示例
public class ObjectLayoutTest {
public static void main(String[] args) {
System.err.println("-------------------------VM details-------------------------------");
System.out.println(VM.current().details());
System.err.println("-------------------------Object details-------------------------------");
System.out.println(ClassLayout.parseInstance(new LongVO(1)).toPrintable());
}
}
控制台打印
-------------------------VM details-------------------------------
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
# Field sizes by type: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
-------------------------Object details-------------------------------
io.wilson.basic.LongVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) b8 43 da 1c (10111000 01000011 11011010 00011100) (484066232)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 8 long LongVO.val 1
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
当禁用指针压缩后VM的引用大小会被更改为8个字节,64位操作系统下klass pointer没有被压缩占8字节,其中最后32位(4byte)是以0填充的。由于LongVO在未开启指针压缩的情况下所占内存已是24bytes,所以无需进行对象填充。
对象哈希识别码(identity_hashcode)
前文提到mark word中存储了对象的哈希识别码,可是示例中对象头打印出来时显示的值却完全不像一个计算出来的哈希码,也不像覆写了对象hashCode()方法的值,原因在于HotSpot JVM延迟计算对象哈希码,当对对象实例调用System.identityHashCode(obj)或原生Object.hashCode()时,对象的哈希码才会被计算出来并记录到object header里。
代码示例
public class ObjectLayoutTest {
public static void main(String[] args) throws InterruptedException {
LongVO vo = new LongVO(5);
System.err.println("------------------------vo hash------------------------");
// 由于没有调用原生object.hashcode()或System.identityHashCode(obj),所以pbject header没有记录对象hashcode
System.err.println("vo.hashCode():" + vo.hashCode() + ", hex hashcode:" + Integer.toHexString(vo.hashCode()));
System.out.println(ClassLayout.parseInstance(vo).toPrintable());
Thread.sleep(500);
int systemHashCode = System.identityHashCode(vo);
System.err.println("object hashcode():" + vo.hashCode() + ", vo system hashcode:" + systemHashCode
+ ", hex hashcode:" + Integer.toHexString(systemHashCode));
System.out.println(ClassLayout.parseInstance(vo).toPrintable());
Thread.sleep(500);
System.err.println("------------------------obj hash------------------------");
Object obj = new Object();
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
Thread.sleep(500);
// 调用了原生object.hashcode(),所以object header记录了对象hashcode
System.err.println("obj.hashCode():" + obj.hashCode() + ", hex hashcode:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
Thread.sleep(500);
System.err.println("object hashcode():" + obj.hashCode() + ", object system hashcode:" + System.identityHashCode(obj)
+ ", hex hashcode:" + Integer.toHexString(System.identityHashCode(obj)));
}
};
控制台打印

从上例可以看出:
- 对象的hashcode会在调用原生的
Object.hashCode()或System.identityHashCode(obj)方法时生成并保存到对象头中,调用覆写了的hashCode()方法并不会计算并保持对象hashcode - mark word倒序存储
Object.hashCode()生成的十六进制值,因为JVM以低字节序(little-endian)格式存储该值。因此,如果要恢复十进制的哈希码值(如vo的1538399081),则须以相反的顺序读取69 1b b2 5b字节序列。
5b b2 1b 69 = 01011011 10110010 00011011 01101001 = 1538399081
字节序
字节序指字节的顺序,字节序分为两类:big-endian(大端模式)和little-endian(小端模式),引用标准的Big-Endian和Little-Endian的定义如下:
- little-endian:低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
- big-endian:高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
- 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
计算机内存存储方式是低位在前,高位在后,即little-endian。以上例object的哈希值6b 96 51 f3,当存到object header内存中时为f3 51 96 6b,若是big-endian字节序则不改变为6b 96 51 f3。
锁用例
代码示例
public class ObjectLayoutTest {
public static void main(String[] args) {
LongVO lockVO = new LongVO(5);
System.err.println("--------------------unlock vo--------------------");
System.out.println(ClassLayout.parseInstance(lockVO).toPrintable());
System.err.println("--------------------lock vo--------------------");
synchronized (lockVO) {
System.out.println(ClassLayout.parseInstance(lockVO).toPrintable());
}
}
}
控制台打印
--------------------unlock vo--------------------
io.wilson.basic.LongVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 92 c3 00 f8 (10010010 11000011 00000000 11111000) (-134167662)
12 4 (alignment/padding gap)
16 8 long LongVO.val 5
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
--------------------lock vo--------------------
io.wilson.basic.LongVO object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 48 f1 9d 03 (01001000 11110001 10011101 00000011) (60682568)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 92 c3 00 f8 (10010010 11000011 00000000 11111000) (-134167662)
12 4 (alignment/padding gap)
16 8 long LongVO.val 5
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
如上所示,当我们保持监视器锁(synchronized)时,mark word的位模式会改变。
参考资源
openjdk HotSpotGlossary
wiki-openjdk CompressedOops