三级数据库知识点学习(一)
文章目录
- 一.外模式、模式、内模式
-
- 1.外模式
- 2.模式
- 3.内模式
- 二.应用服务器
- 三.关系模型
- 四.数据库设计
- 五.建立索引
- 六.触发器、Check约束、Default约束
-
- 1.触发器
- 2.Check约束
- 3.Default约束
- 七.临时表、Tempdb数据库
-
- 1.临时表
- 2.Tempdb数据库
- 八.分布式数据库、并行数据库
-
- 1.分布式数据库
- 2.并行数据库
- 九.数据挖掘
- 十.数据页和数据行
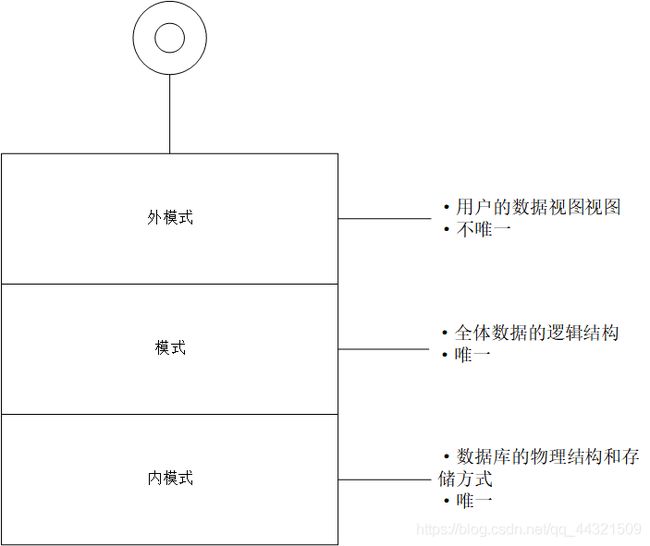
一.外模式、模式、内模式
1.外模式
外模式也称子模式或用户模式,是用户可见的部分数据的可见形式,也就是用户的数据视图。
一个数据库可以有多个外模式。
2.模式
模式也称逻辑模式,是全体数据的逻辑结构,且用户不可见。
一个数据库只有一个模式。
3.内模式
内模式也称存储模式,是数据库的物理结构和存储方式。
一个数据库只有一个内模式。
二.应用服务器
应用服务器是通过各种协议把商业逻辑提供给客户端的程序。
- 提供了访问商业逻辑的途径以供客户端应用程序使用,并接收来自于Web浏览器的用户请求,根据应用领域业务规则执行相应的数据库应用程序,通过访问接口并像数据库服务器提出数据操作请求;
- 接收来自于数据库服务器的数据访问结果,并通过客户端将结果返回客户。
三.关系模型
关于关系模型中的一些基本概念,如元组、属性、值域、健、候选键、主键这些就不解释了,这里描述关系模型中的关系模式和关系。
- 关系模式:在二维表中的行定义,即对关系的描述。一般表示为(属性1,属性2,…,属性n),如下列教师的关系模型可以表示为教师(教师号,姓名,性别,年龄,职称,所在学院)。
关系模式描述关系的静态,是静态的、稳定的。
| 教师号 | 姓名 | 性别 | 年龄 | 职称 | 所在学院 |
|---|---|---|---|---|---|
| 001 | 张三 | 男 | 30 | 讲师 | 会计学院 |
| 002 | 李四 | 女 | 46 | 教授 | 信息学院 |
- 关系:一个关系对应着一个二维表,二维表就是关系名。
关系是动态的、随用户对数据库的操作而变化的。
四.数据库设计
数据库设计是根据用户的需求在某一具体的数据库管理系统上,设计数据库的结构和建立数据库的过程。数据库系统需要操作系统的支持。
数据库设计的六个阶段分别为:
1.需求分析
2.概念设计
3.逻辑设计
4.物理设计
5.验证设计
6.运行与维护设计
五.建立索引
索引就是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。用户无法看到索引,它们只能被用来加速搜索/查询。
用户在查询数据库信息的时候,有时候数据特别多就会造成查询速度缓慢的情况,建立索引就是为了加速查询的时间。
- 建立索引的语法如下
CREATE INDEX index_name ON table_name (column_name)
其中index_name表示索引名,索引名可自行定义,table_name表示需要建立索引的表名,column_name表示需要建立索引的列名。
建立索引的例子如下
CREATE INDEX StudentIndex ON Student (LastName)
其中StudentIndex表示索引名,Student表示需要建立索引的学生表,LastName表示需要建立索引的姓。
- 另一种建立索引的方法是建立唯一索引,唯一的索引意味着两个行不能拥有相同的索引值。
建立唯一的语法如下
CREATE UNIQUE INDEX index_name ON table_name (column_name)
可见此语法与上一个语法的区别是多了一个UNIQUE,UNIQUE就代表唯一的意思。
六.触发器、Check约束、Default约束
为什么将触发器、Check约束和Default约束放在一起呢,因为他们都具有约束功能。
1.触发器
触发器是在满足某个特定条件自动触发执行的专用存储过程,用于保证表中的数据遵循数据库设计者确定的规则和约束。
创建触发器语法如下
CREATE TRIGGER trigger_name
trigger_time
trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中
- trigger_name:表示触发器名称,用户可自行定义;
- trigger_time:表示触发时机,取值为 before或 after;
- trigger_event:表示触发事件,取值为 insert、update 或 delete;
- tbl_name:表示建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:表示触发器程序体,可以是一句SQL语句,或者用 begain 和 end 包含的多条语句。
创建触发器的例子如下
//创建一个触发器,当学生表中的数据被更新时,显示学生表中的所有数据。
create trigger student_change
on student after insert,update,delete
as
select * from student;
2.Check约束
check约束用于限制列中的值的范围,例如性别只能为“男”或“女”、银行卡密码只能为六位等。
- 创建check约束的例子如下
CREATE TABLE Persons
(
Id_P int NOT NULL CHECK (Id_P>0),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
上例中在 “Persons” 表创建时为 “Id_P” 列创建 CHECK 约束。CHECK 约束规定 “Id_P” 列必须只包含大于 0 的整数。
3.Default约束
default约束用于向列中插入默认值。如果该列中没有规定其他的值,那么默认为default所约束的值。比如“城市”列没有规定其他的值,在“城市列”创建有default约束为“贵阳”,那么就默认为“贵阳”。
- 创建default约束的例子如下
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT ‘Guiyang’
)
七.临时表、Tempdb数据库
1.临时表
临时表与实体表类似,只是在使用过程中,临时表是存储在系统数据库tempdb中。当我们不再使用临时表的时候,临时表会自动删除。
临时表分为全局临时表和局部临时表。
如我们平时见到的#Temp一样,此处介绍的局部临时表就是用户在创建表的时候添加了"#"前缀的表。
- 创建临时表的例子如下
SELECT * INTO #Customers FROM Customers
上例创建了一个和customers相同的临时表#customers,这时就可以查询到临时表#customers
SELECT * FROM #Customers
- 创建临时表的作用
临时表在比较复杂的嵌套查询中是可以提高查询效率的。
(ps:此处就不演示如何提高效率了,作者本人也不是特别懂,反正就记住它的作用是能提高查询效率
/手动滑稽)
2.Tempdb数据库
Tempdb系统数据库是一个全局资源,可供连接到 SQL Server 实例或 SQL 数据库的所有用户使用 。
tempdb 用于保留:
- 显式创建的临时用户对象 ,例如:上一节提到的全局或局部临时表及索引、临时存储过程、表变量、表值函数返回的表或游标。
- 由数据库引擎创建的内部对象 。
- 版本存储区,数据页的集合,它包含支持使用行版本控制的功能所需的数据行。
八.分布式数据库、并行数据库
1.分布式数据库
分布式数据库是用计算机网络将物理上分散的多个数据库单元连接起来组成的一个逻辑上统一的数据库。每个被连接起来的数据库单元称为站点或节点。
基本特点:
- 物理分布性
- 逻辑整体性
- 站点自治性
分布式数据库系统抽象为4层结构模式,分别为:
- 全局外层
- 全局概念层
- 局部概念层
- 局部内层
2.并行数据库
并行数据库系统是新一代高性能的数据库系统,是在MPP和集群并行计算环境的基础上建立的数据库系统。
目标:
- 高性能
- 高可用性
- 可扩充性
九.数据挖掘
数据挖掘又译为资料探勘,是按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法。
数据挖掘的目标是从数据库中发现隐含的、有意义的知识。
数据挖掘技术包括:
- 关联分析
- 序列分析
- 分类分析
- 预测分析
- 聚类分析
- 时间序列分析
数据挖掘的流程:
- 问题定义
- 建立数据挖掘库
- 分析数据
- 调整数据
- 模型化
- 评价和解释
十.数据页和数据行
数据页是SQL sever 中数据存储的基本单位。页的基本大小为8KB,即1MB中总共有128页。每页的开头有96字节的标头,用于存储有关页的系统信息。每个数据页能存储8060字节的数据。
数据行无固定大小,行不能跨页,但是行的部分可以移出所在的页,因此行实际可能非常大。
- 数据页和数据行的例题
在SQL sever 2008中,每个数据页可存储8060字节的数据。设表T有10000行数据,每行占用4031字节,则存储该表数据大约需要_____MB存储空间。(结果按四舍五入取整)
解析:由于题目中2行数据加起来的存储空间大于数据页,所以每页只能存储一行,因为1M有128页,也就可以存储128行,10000/128=78.125,所以结果为78。
(PS:上一篇文章命令提示符cmd查询IP地址时显示的各个值分别表示什么到现在已经有了1100+访问量,还收获了很多点赞和评论,真的让我很意外,作者真诚地感谢那些给我点赞和评论的朋友,让我们一起奋进,我还得多多向你们学习才是。本次分享的是作者在学习三级数据库过程中遇到的不懂的问题,通过查询资料然后结合自己的观点而写的,我自己都感觉很乱,看来还是需要不断学习才是!如果文中有错误的或者大佬们有更好的观点的地方还请指出来,愚愿虚心求教~)