Solr学习(五)DIH增量、定时导入并检索数据
注意:整个Solr学习系列使用的都是Solr4.5.1,更高版本应该也适用,耕地版本不知道。转载请注明出处:jiq·钦's technical blog
(一)引言:
前面我的文章 DIH全量导入 中已经学会了如何全量导入Oralce和MySQL的数据,大家都知道全量导入在数据量大的时候代价非常大,一般来说都会适用增量的方式来导入数据,下面介绍如何增量导入MYSQL数据库中的数据,以及如何设置 定时来做。
下面介绍的所有操作都是基于前面已经完成的全量导入的基础上来做的。
(一)DIH增量从MYSQL数据库导入数据:
1、数据库表的更改:
前面已经创建好了一个UserInfo的表,这里为了能够进行增量导入,需要新增一个字段,类型为TIMESTAMP,默认值为CURRENT_TIMESTAMP。

有了这样一个字段,Solr才能判断增量导入的时候,哪些数据是新的。
因为Solr本身有一个默认值last_index_time,记录最后一次做full import或者是delta import(增量导入)的时间,这个值存储在文件conf目录的dataimport.properties文件中。
2、data-config.xml中必要属性的设置:
注意这个只能返回ID字段
注意这个只能返回ID字段 有关“query”,“deltaImportQuery”, “deltaQuery”的解释,引用官网说明,如下所示:
- The query gives the data needed to populate fields of the Solr document in full-import
- The deltaImportQuery gives the data needed to populate fields when running a delta-import
- The deltaQuery gives the primary keys of the current entity which have changes since the last index time
然后从这些数据中根据deltaQuery指定的SQL语句查询出所有需要增量导入的数据的ID号。
最后根据deltaImportQuery指定的SQL语句返回所有这些ID的数据,即为这次增量导入所要处理的数据。
核心思想是:通过内置变量“${dih.delta.id}”和 “${dataimporter.last_index_time}”来记录本次要索引的id和最近一次索引的时间。
注意:刚新加上的UpdateTime字段也要在field属性中配置,同时也要在schema.xml文件中配置:
3、测试增量导入:
在浏览器中输入:http://localhost:8087/solr/dataimport?command=delta-import 然后到http://localhost:8087/solr/#/collection1/query检索一条不存在的数据,然后利用SQL语句插入一条数据:
INSERT INTO `test`.`userinfo`
(`UserID`,
`UserName`,
`UserAge`)
VALUES
(6,
'季义钦增量数据测试',
25);再次在浏览器中数据刚才的连接,再次检索。
(二)设置增量导入为定时执行的任务:
很多人利用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题。
但是更方便,更加与Solr本身集成度高的是利用其自身的定时增量导入功能。
1、下载apache-solr-dataimportscheduler-1.0.jar放到Tomcat的webapps的solr目录的WEB-INF的lib目录下:
下载地址:http://code.google.com/p/solr-dataimport-scheduler/downloads/list
也可以到我的云盘下载:http://pan.baidu.com/s/1dDw0MRn
2、修改solr的WEB-INF目录下面的web.xml文件:
为
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
3、新建配置文件dataimport.properties:
在SOLR_HOME\solr目录下面新建一个目录conf(注意不是SOLR_HOME\solr\collection1下面的conf),然后用解压文件打开apache-solr-dataimportscheduler-1.0.jar文件,将里面的dataimport.properties文件拷贝过来,进行修改,下面是最终我的自动定时更新配置文件内容:
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
# syncCores=game,resource #因为我的是single-core,所以注释掉了,默认就是collection1
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
port=8087
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
# 增量更新的请求参数
params=/dataimport?command=delta-import&clean=true&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
# 这里配置的是2min一次
interval=2
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=7200
# 重做索引的参数
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
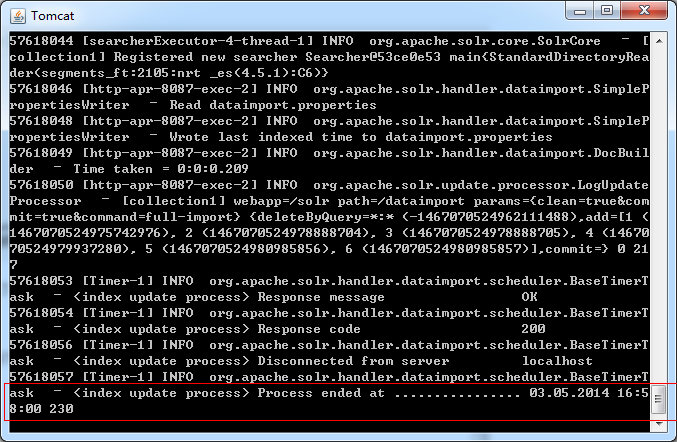
reBuildIndexBeginTime=03:10:00至此就完成了定时增量更新的配置,启动tomcat服务器,不需要再浏览器请求增量导入了,可以看到已经开始定期增量更新了。
================================ 一般来说要在你的项目中引入Solr需要考虑以下几点:
1、数据更新频率:每天数据增量有多大,随时更新还是定时更新
2、数据总量:数据要保存多长时间
3、一致性要求:期望多长时间内看到更新的数据,最长允许多长时间延迟
4、数据特点:数据源包括哪些,平均单条记录大小
5、业务特点:有哪些排序要求,检索条件
6、资源复用:已有的硬件配置是怎样的,是否有升级计划