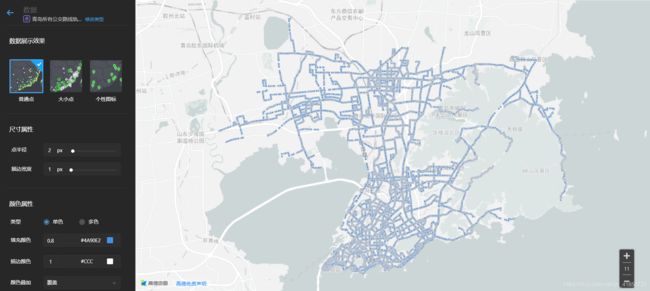
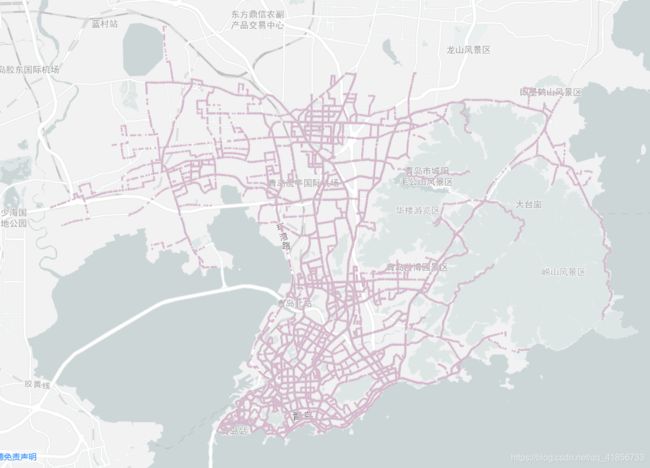
【大数据】城市公交网络分析与可视化(二):获取公交行驶路径并绘制散点图
博客内容说明
本博客为系列课题第二篇,一些必要的内容请见:
【大数据】城市公交网络分析与可视化(一):借助Python爬取公交车行驶路径等基本信息
本博客内容简介:借助高德地图API,爬取一个城市多条公交线路轨迹坐标,并绘制公交行驶路径(散点)图。(本博客以青岛举例,并依次绘制10条线路、49条线路、全部线路)
具体探究过程
运行环境:Anaconda 中的Spyder软件
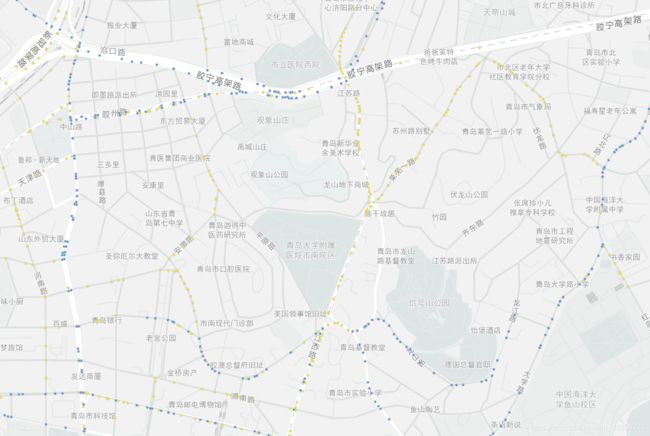
1、青岛市1路到10路公交运行路线(轨迹)
(1)直接可运行代码
确实有可能出现我这里运行的好好的,但他处不能运行的情况,emmmmm,祝你好运!
import requests
import json
import pandas as pd
def get_line(cityname,line,path):
#获取数据
url = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=a5b7479db5b24fd68cedcf24f482c156&output=json&city={}&offset=1&keywords={}&platform=JS'.format(cityname,line)
r = requests.get(url).text
rt = json.loads(r)
try:#若报错(即该没有线路)进入except,跳过
polyline=rt['buslines'][0]['polyline'] #获取沿途路径坐标
path=path+polyline #这里通过path字符串累计获取所有公交线路路径
return path
except:
print('没有{}路公交'.format(line))
pass
if __name__=="__main__":
path_str=''
for i in range(1,11):
path_str=get_line('青岛',str(i),path_str)
print(len(path_str)) #获取坐标字符串总长度(不是坐标总数,总数大约为这个数/21)
path={
}
path['station_coords']=path_str.split(";") #通过";"拆分每个路径坐标
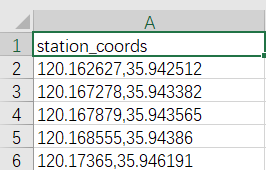
path=pd.DataFrame(path)
#将坐标拆解为经度longitude,和纬度latitude(请根据具体使用场景处理数据)
path['longitude'],path['latitude'] = path['station_coords'].str.split(',', 1).str
path.to_csv('青岛10条线路公交路线轨迹数据.csv',encoding='utf-8')
#path.drop(['station_coords'],axis=1,inplace=True) #狡兔死走狗烹,飞鸟尽良弓藏 经度,纬度提取出来,可以把原来的经纬度给删了
#path.to_csv('青岛10条线路公交路线轨迹数据.csv',index=False,encoding='utf-8-sig') #index=False即不显示index索引
(2)运行结果:
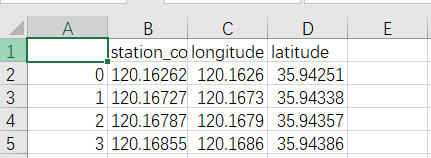
(3)删除一些不必要数据后的结果
这里处理是为了节省空间的情况下便于后面高德地图绘制,本来只需要一列经纬度就好了,我也按照高德地图要求去处理数据了,就是不行,很迷,遂放弃,两列就两列吧。

不行!!!
不知出于什么原因,删除坐标列,绘图平台读取数据不成功!
只好加回来了。

(继续看,后面有些问题原因)
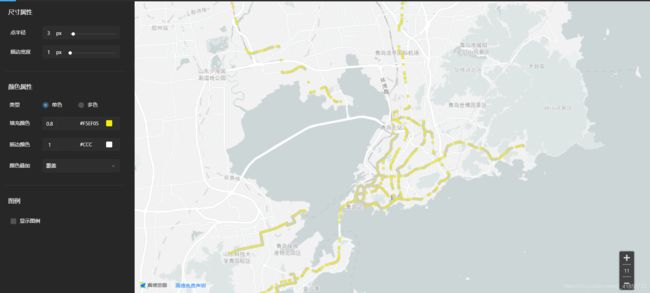
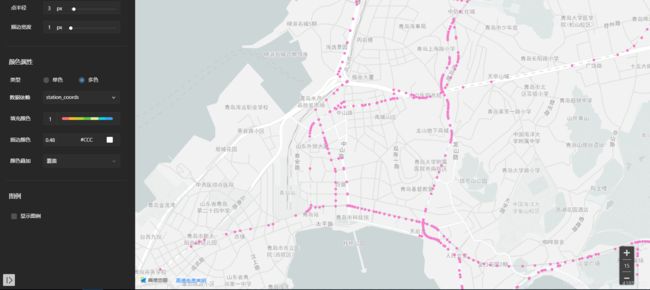
(4)可视化
如何知道我获取的路径数据是对的?
那就画出来吧!高德开发平台(Map Lab)
2、青岛市1路到50路(无44路)公交运行路线(轨迹)
(1)上面代码的修改版
import requests
import json
import pandas as pd
import time
def get_line(cityname,line,path):
#获取数据
url = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=a5b7479db5b24fd68cedcf24f482c156&output=json&city={}&offset=1&keywords={}&platform=JS'.format(cityname,line)
r = requests.get(url).text
rt = json.loads(r)
try:#若报错(即该没有线路)进入except,跳过
polyline=rt['buslines'][0]['polyline'] #获取沿途路径坐标
path=path+polyline #这里通过path字符串累计获取所有公交线路路径
return path
except:
print('没有{}路公交'.format(line))
#pass
return path #之前写pass,因为这个函数是有返回值的,故行不通
if __name__=="__main__":
#获取1路到50路公交的量较大,或许需要个计时器
t0=time.time()
print('显示程序开始的时间:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
path_str=''
for i in range(1,51):
path_str=get_line('青岛',str(i),path_str)
path={
}
path['station_coords']=path_str.split(";") #通过";"拆分每个路径坐标
path=pd.DataFrame(path)
path.to_csv('青岛50条线路公交路线轨迹数据.csv',index=False,encoding='utf-8') #index=False即不显示index索引
print("坐标数据有{}条".format(len(path['station_coords'])))
t1=time.time()
print('显示程序结束的时间:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
print("用时:%.6fs"%(t1-t0))
(2)运行结果:

(3)获取的表格数据
也不知道啥原理,这次只放一个坐标数据,也不要按要求那样加引号高德地图也能读取了!
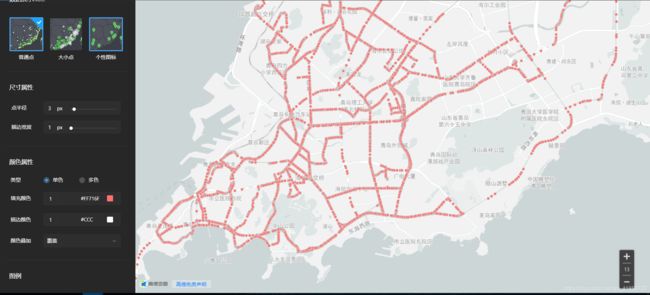
(4)那就数据可视化喽
49条公交线路,15983个坐标轨迹,已经很卡了

接下来,该干嘛,大家应该猜到了
3、青岛市所有公交(遍历1000路公交)运行轨迹!
(1)本质没变的代码:
import requests
import json
import pandas as pd
import time
def get_line(cityname,line,path,bus_num):
#获取数据
url = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=a5b7479db5b24fd68cedcf24f482c156&output=json&city={}&offset=1&keywords={}&platform=JS'.format(cityname,line)
r = requests.get(url).text
rt = json.loads(r)
try:
polyline=rt['buslines'][0]['polyline']
path=path+polyline #这里通过path字符串累计获取所有公交线路路径
return bus_num+1,path
except:
print('没有{}路公交'.format(line))
return bus_num,path
if __name__=="__main__":
t0=time.time()#记录时间用的
path_str=''
bus_num=0 #基本功没学好,关于python全局变量和传参问题一直搞得不清楚,所有采用比较捞的方法获取局部变量数据变化了
for i in range(1,1001):
bus_num,path_str=get_line('青岛',str(i),path_str,bus_num)
path={
}
path['station_coords']=path_str.split(";")
path=pd.DataFrame(path)
path.to_csv('青岛所有线路(循环1000路实现)公交路线轨迹数据.csv',index=False,encoding='utf-8')
print("坐标数据有{}条".format(len(path['station_coords'])))
print('遍历了{}条公交线路'.format(bus_num))
t1=time.time()
print("运行用时:%.2fs"%(t1-t0))
(2)实验结果
做过大数据项目的人应该知道,6分半运行时间还是能接受的!
遍历了424条公交线路可还行!

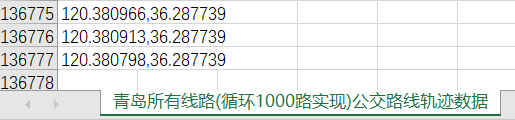
现在的问题是:136776条坐标数据!
为此我还专门查了:“Excel 2013版:列数最大16384(2的14次方),行数最大1048576(2的20次方)”
Execl是没问题了,高德地图传不上去呀!!!
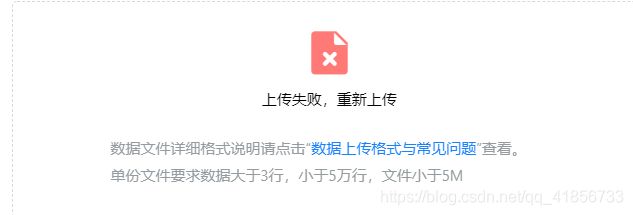
(3)做人要有梦想——补充代码
不让上传超过5万行的数据,最多能上传3个表格,有13多万条数据!
真実は一つだけです!
path.iloc[0:49000, :].to_csv('青岛所有线路(循环1000路实现)公交路线轨迹数据-拆分数据1.csv',index=False,encoding='utf-8')
path.iloc[49000:98000, :].to_csv('青岛所有线路(循环1000路实现)公交路线轨迹数据-拆分数据2.csv',index=False,encoding='utf-8')
path.iloc[98000:, :].to_csv('青岛所有线路(循环1000路实现)公交路线轨迹数据-拆分数据3.csv',index=False,encoding='utf-8')
顺带一说,我好像知道为什么最开始只直接上传坐标数据,高德读取不了,后来又可以了:不可以是因为加了索引;保存数据的时候加“index=False”,去掉索引就好了!
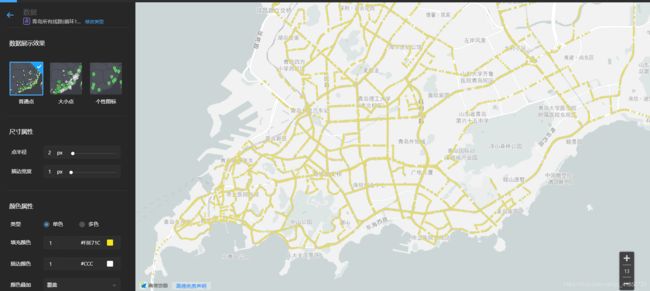
(4)分三次上传的数据绘制的结果!
①上传第一部分数据(黄色部分)
此时我的电脑,明显感到勉为其难了,每操作一下电脑风扇就疯狂地在抱怨~
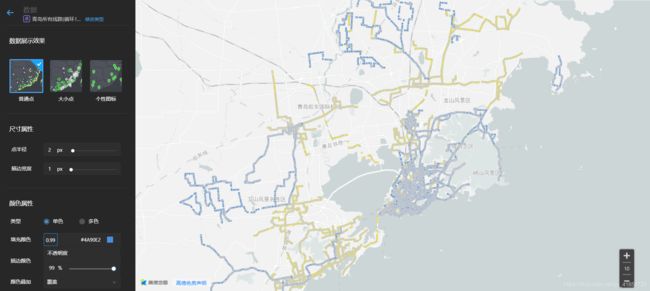
②上传第二部分数据(蓝色部分)
卡成PPT!!!
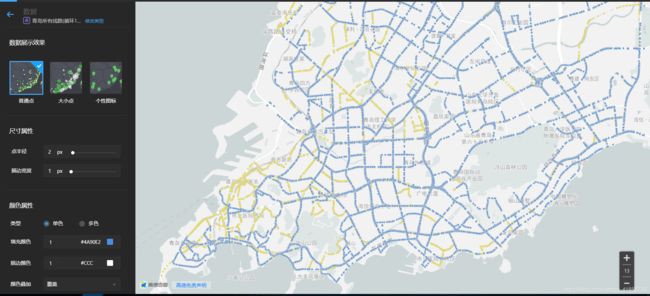
③上传第三部分数据(红色部分)
每一次操作都会伴随漫长的等待,2年半以前的笔记本究落伍了。(当然本身这个数据量这么大处理有问题是能理解的),突然理解为什么那么多专业款的电脑那么贵了,1.5TB内存顶配 Mac pro了解一下
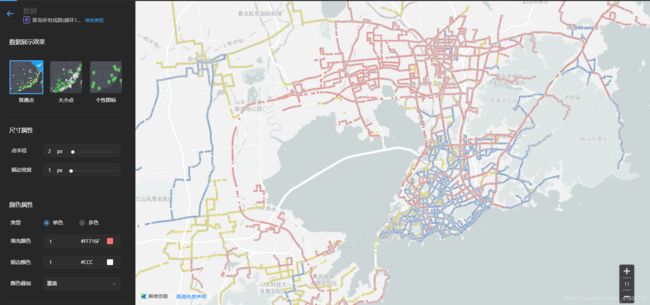
其实三种颜色也是有一定含义的,黄色表示该公交“路数”比较小(大约1路-200路左右),蓝色表示该公交“路数”中等(大约200路-500路),红色表示“路数偏大”(大约500路-950路)。
可见一般老城区,公交路数都不是很大~~~(认真想想,这不是显而易见的的道理嘛)
4、8684网站上获取青岛市区公交线路
1、根据具体背景优化的代码
遍历一定范围的数确实有其巧妙之处,但可能会遗漏一些特殊的专线公交,这时我们可以通过一些提供公交信息的网站,获取具体区域、更详细公交线路名信息:8684网青岛市区线路
import requests
import json
import pandas as pd
import time
def get_line(cityname,line,path):
#获取数据
url = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=a5b7479db5b24fd68cedcf24f482c156&output=json&city={}&offset=1&keywords={}&platform=JS'.format(cityname,line)
r = requests.get(url).text
rt = json.loads(r)
try:
polyline=rt['buslines'][0]['polyline']
path=path+polyline
return path
except:
print('没有{}公交'.format(line)) #正常情况下,这条语句不会执行
return path
if __name__=="__main__":
t0=time.time()
bus_name=[]
path_str=''
path={
}
#读取当前目录下的公交线路.txt文档,获取公交线路名
with open("公交线路.txt", "r", encoding="utf-8") as f:
bus_name = f.readlines()
bus_name = bus_name[0].split(",")
for i in bus_name:
path_str=get_line('青岛',i,path_str)
path['station_coords']=path_str.split(";")
path=pd.DataFrame(path)
path.to_csv('青岛所有公交路线轨迹数据(8684).csv',index=False,encoding='utf-8')
print('8684网站上获取青岛市区公交线路:',len(bus_name),"条")
print("这些公交路径坐标数据有{}条".format(len(path['station_coords'])))
t1=time.time()
print("运行用时:%.2fs"%(t1-t0))
(2)运行结果

这样的结果是错误的,很明显是有个逗号为中文逗号导致的!
修改后:

(3)补充代码
和之前一样,这样的数据量高德地图没法一次读入,需要分两个表格保存后上传。
path.iloc[0:49000, :].to_csv('青岛所有公交路线轨迹数据(8684)-拆分数据1.csv',index=False,encoding='utf-8')
path.iloc[49000:, :].to_csv('青岛所有公交路线轨迹数据(8684)-拆分数据2.csv',index=False,encoding='utf-8')
(4)可视化
这种规模的数据量搭配并不出色的电脑性能,不可避免的将创造的热情减少了不少ㄟ( ▔, ▔ )ㄏa
青岛市区所有公交线路轨迹图: