卷积神经网络——第一周 卷积神经网络基础——第三部分
1.7 单层卷积网络(One layer of a convolutional network)
今天我们要讲的是如何构建卷积神经网络的卷积层,下面来看个例子。
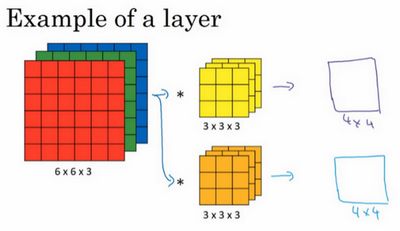
上节课,我们已经讲了如何通过两个过滤器卷积处理一个三维图像,并输出两个不同的4×4矩阵。假设使用第一个过滤器进行卷积,得到第一个4×4矩阵。使用第二个过滤器进行卷积得到另外一个4×4矩阵。
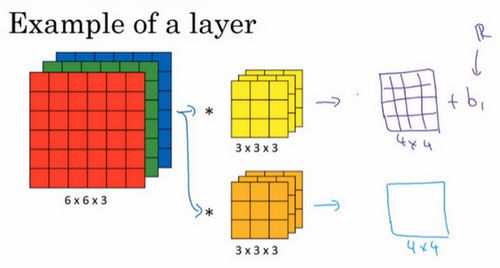
最终各自形成一个卷积神经网络层,然后增加偏差,它是一个实数,通过Python的广播机制给这16个元素都加上同一偏差。然后应用非线性函数,为了说明,它是一个非线性激活函数ReLU,输出结果是一个4×4矩阵。
对于第二个4×4矩阵,我们加上不同的偏差,它也是一个实数,16个数字都加上同一个实数,然后应用非线性函数,也就是一个非线性激活函数ReLU,最终得到另一个4×4矩阵。然后重复我们之前的步骤,把这两个矩阵堆叠起来,最终得到一个4×4×2的矩阵。我们通过计算,从6×6×3的输入推导出一个4×4×2矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
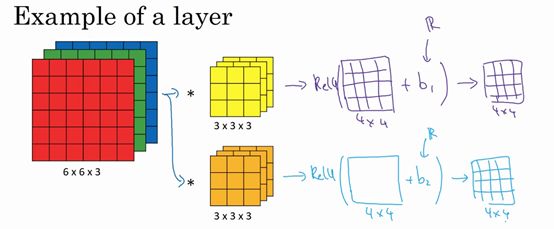
注意前向传播中一个操作就是,其中,执行非线性函数得到,即。这里的输入是,也就是,这些过滤器用变量表示。在卷积过程中,我们对这27个数进行操作,其实是27×2,因为我们用了两个过滤器,我们取这些数做乘法。实际执行了一个线性函数,得到一个4×4的矩阵。卷积操作的输出结果是一个4×4的矩阵,它的作用类似于,也就是这两个4×4矩阵的输出结果,然后加上偏差。
这一部分(图中蓝色边框标记的部分)就是应用激活函数ReLU之前的值,它的作用类似于,最后应用非线性函数,得到的这个4×4×2矩阵,成为神经网络的下一层,也就是激活层。
这就是到的演变过程,首先执行线性函数,然后所有元素相乘做卷积,具体做法是运用线性函数再加上偏差,然后应用激活函数ReLU。这样就通过神经网络的一层把一个6×6×3的维度演化为一个4×4×2维度的,这就是卷积神经网络的一层。
示例中我们有两个过滤器,也就是有两个特征,因此我们才最终得到一个4×4×2的输出。但如果我们用了10个过滤器,而不是2个,我们最后会得到一个4×4×10维度的输出图像,因为我们选取了其中10个特征映射,而不仅仅是2个,将它们堆叠在一起,形成一个4×4×10的输出图像,也就是。

为了加深理解,我们来做一个练习。假设你有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数表示,现在参数增加到28个。上一页幻灯片里我画了2个过滤器,而现在我们有10个,加在一起是28×10,也就是280个参数。
请注意一点,不论输入图片有多大,1000×1000也好,5000×5000也好,参数始终都是280个。用这10个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大,参数却很少,这就是卷积神经网络的一个特征,叫作“避免过拟合”。你已经知道到如何提取10个特征,可以应用到大图片中,而参数数量固定不变,此例中只有28个,相对较少。
最后我们总结一下用于描述卷积神经网络中的一层(以层为例),也就是卷积层的各种标记。

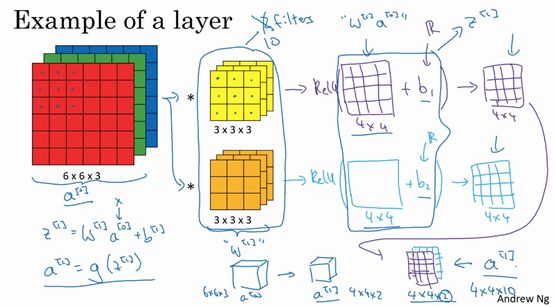
这一层是卷积层,用表示过滤器大小,我们说过过滤器大小为,上标表示层中过滤器大小为。通常情况下,上标用来标记层。用来标记padding的数量,padding数量也可指定为一个valid卷积,即无padding。或是same卷积,即选定padding,如此一来,输出和输入图片的高度和宽度就相同了。用标记步幅。
这一层的输入会是某个维度的数据,表示为,某层上的颜色通道数。
我们要稍作修改,增加上标,即,因为它是上一层的激活值。
此例中,所用图片的高度和宽度都一样,但它们也有可能不同,所以分别用上下标和来标记,即。那么在第层,图片大小为,层的输入就是上一层的输出,因此上标要用。神经网络这一层中会有输出,它本身会输出图像。其大小为,这就是输出图像的大小。
前面我们提到过,这个公式给出了输出图片的大小,至少给出了高度和宽度,(注意:(直接用这个运算结果,也可以向下取整)。在这个新表达式中,层输出图像的高度,即,同样我们可以计算出图像的宽度,用替换参数,即,公式一样,只要变化高度和宽度的参数我们便能计算输出图像的高度或宽度。这就是由推导以及推导的过程。
那么通道数量又是什么?这些数字从哪儿来的?我们来看一下。输出图像也具有深度,通过上一个示例,我们知道它等于该层中过滤器的数量,如果有2个过滤器,输出图像就是4×4×2,它是二维的,如果有10个过滤器,输出图像就是4×4×10。输出图像中的通道数量就是神经网络中这一层所使用的过滤器的数量。如何确定过滤器的大小呢?我们知道卷积一个6×6×3的图片需要一个3×3×3的过滤器,因此过滤器中通道的数量必须与输入中通道的数量一致。因此,输出通道数量就是输入通道数量,所以过滤器维度等于。

应用偏差和非线性函数之后,这一层的输出等于它的激活值,也就是这个维度(输出维度)。是一个三维体,即。当你执行批量梯度下降或小批量梯度下降时,如果有个例子,就是有个激活值的集合,那么输出。如果采用批量梯度下降,变量的排列顺序如下,首先是索引和训练示例,然后是其它三个变量。
该如何确定权重参数,即参数W呢?过滤器的维度已知,为,这只是一个过滤器的维度,有多少个过滤器,这()是过滤器的数量,权重也就是所有过滤器的集合再乘以过滤器的总数量,即,损失数量L就是层中过滤器的个数。
最后我们看看偏差参数,每个过滤器都有一个偏差参数,它是一个实数。偏差包含了这些变量,它是该维度上的一个向量。后续课程中我们会看到,为了方便,偏差在代码中表示为一个1×1×1×的四维向量或四维张量。

卷积有很多种标记方法,这是我们最常用的卷积符号。大家在线搜索或查看开源代码时,关于高度,宽度和通道的顺序并没有完全统一的标准卷积,所以在查看GitHub上的源代码或阅读一些开源实现的时候,你会发现有些作者会采用把通道放在首位的编码标准,有时所有变量都采用这种标准。实际上在某些架构中,当检索这些图片时,会有一个变量或参数来标识计算通道数量和通道损失数量的先后顺序。只要保持一致,这两种卷积标准都可用。很遗憾,这只是一部分标记法,因为深度学习文献并未对标记达成一致,但课上我会采用这种卷积标识法,按高度,宽度和通道损失数量的顺序依次计算。

我知道,忽然间接触到这么多新的标记方法,你可能会说,这么多怎么记呢?别担心,不用全都记住,你可以通过本周的练习来熟悉它们。而这节课我想讲的重点是,卷积神经网络的某一卷积层的工作原理,以及如何计算某一卷积层的激活函数,并映射到下一层的激活值。了解了卷积神经网络中某一卷积层的工作原理,我们就可以把它们堆叠起来形成一个深度卷积神经网络,我们下节课再讲。
1.8 简单卷积网络示例(A simple convolution network example)
上节课,我们讲了如何为卷积网络构建一个卷积层。今天我们看一个深度卷积神经网络的具体示例,顺便练习一下我们上节课所学的标记法。
假设你有一张图片,你想做图片分类或图片识别,把这张图片输入定义为,然后辨别图片中有没有猫,用0或1表示,这是一个分类问题,我们来构建适用于这项任务的卷积神经网络。针对这个示例,我用了一张比较小的图片,大小是39×39×3,这样设定可以使其中一些数字效果更好。所以,即高度和宽度都等于39,,即0层的通道数为3。

假设第一层我们用一个3×3的过滤器来提取特征,那么,因为过滤器时3×3的矩阵。,,所以高度和宽度使用valid卷积。如果有10个过滤器,神经网络下一层的激活值为37×37×10,写10是因为我们用了10个过滤器,37是公式的计算结果,也就是,所以输出是37×37,它是一个vaild卷积,这是输出结果的大小。第一层标记为,,等于第一层中过滤器的个数,这(37×37×10)是第一层激活值的维度。
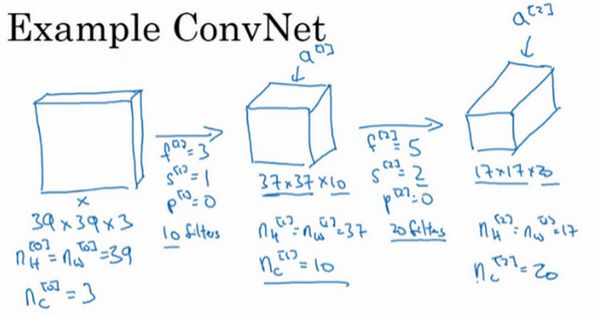
假设还有另外一个卷积层,这次我们采用的过滤器是5×5的矩阵。在标记法中,神经网络下一层的,即步幅为2,即。padding为0,即,且有20个过滤器。所以其输出结果会是一张新图像,这次的输出结果为17×17×20,因为步幅是2,维度缩小得很快,大小从37×37减小到17×17,减小了一半还多,过滤器是20个,所以通道数也是20,17×17×20即激活值的维度。因此,。

我们来构建最后一个卷积层,假设过滤器还是5×5,步幅为2,即,,计算过程我跳过了,最后输出为7×7×40,假设使用了40个过滤器。padding为0,40个过滤器,最后结果为7×7×40。

到此,这张39×39×3的输入图像就处理完毕了,为图片提取了7×7×40个特征,计算出来就是1960个特征。然后对该卷积进行处理,可以将其平滑或展开成1960个单元。平滑处理后可以输出一个向量,其填充内容是logistic回归单元还是softmax回归单元,完全取决于我们是想识图片上有没有猫,还是想识别种不同对象中的一种,用表示最终神经网络的预测输出。明确一点,最后这一步是处理所有数字,即全部的1960个数字,把它们展开成一个很长的向量。为了预测最终的输出结果,我们把这个长向量填充到softmax回归函数中。
这是卷积神经网络的一个典型范例,设计卷积神经网络时,确定这些超参数比较费工夫。要决定过滤器的大小、步幅、padding以及使用多少个过滤器。这周和下周,我会针对选择参数的问题提供一些建议和指导。

而这节课你要掌握的一点是,随着神经网络计算深度不断加深,通常开始时的图像也要更大一些,初始值为39×39,高度和宽度会在一段时间内保持一致,然后随着网络深度的加深而逐渐减小,从39到37,再到17,最后到7。而通道数量在增加,从3到10,再到20,最后到40。在许多其它卷积神经网络中,你也可以看到这种趋势。关于如何确定这些参数,后面课上我会更详细讲解,这是我们讲的第一个卷积神经网络示例。
一个典型的卷积神经网络通常有三层,一个是卷积层,我们常常用Conv来标注。上一个例子,我用的就是CONV。还有两种常见类型的层,我们留在后两节课讲。一个是池化层,我们称之为POOL。最后一个是全连接层,用FC表示。虽然仅用卷积层也有可能构建出很好的神经网络,但大部分神经望楼架构师依然会添加池化层和全连接层。幸运的是,池化层和全连接层比卷积层更容易设计。后两节课我们会快速讲解这两个概念以便你更好的了解神经网络中最常用的这几种层,你就可以利用它们构建更强大的网络了。

再次恭喜你已经掌握了第一个卷积神经网络,本周后几节课,我们会学习如何训练这些卷积神经网络。不过在这之前,我还要简单介绍一下池化层和全连接层。然后再训练这些网络,到时我会用到大家熟悉的反向传播训练方法。那么下节课,我们就先来了解如何构建神经网络的池化层。
1.9 池化层(Pooling layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性,我们来看一下。

先举一个池化层的例子,然后我们再讨论池化层的必要性。假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
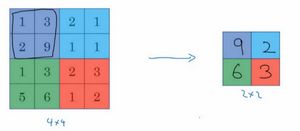
左上区域的最大值是9,右上区域的最大元素值是2,左下区域的最大值是6,右下区域的最大值是3。为了计算出右侧这4个元素值,我们需要对输入矩阵的2×2区域做最大值运算。这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数。
因为我们使用的过滤器为2×2,最后输出是9。然后向右移动2个步幅,计算出最大值2。然后是第二行,向下移动2步得到最大值6。最后向右移动3步,得到最大值3。这是一个2×2矩阵,即,步幅是2,即。
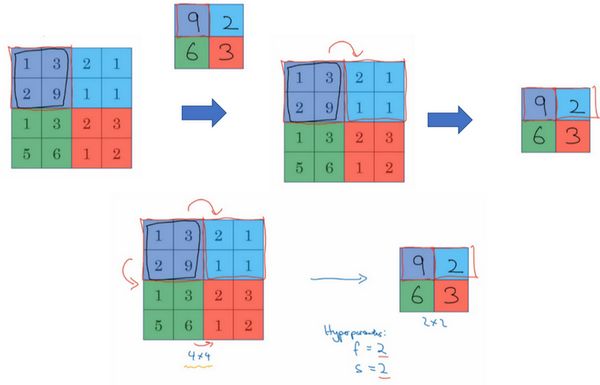
这是对最大池化功能的直观理解,你可以把这个4×4输入看作是某些特征的集合,也许不是。你可以把这个4×4区域看作是某些特征的集合,也就是神经网络中某一层的非激活值集合。数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的CAP特征。显然左上象限中存在这个特征,这个特征可能是一只猫眼探测器。然而,右上象限并不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
必须承认,人们使用最大池化的主要原因是此方法在很多实验中效果都很好。尽管刚刚描述的直观理解经常被引用,不知大家是否完全理解它的真正原因,不知大家是否理解最大池化效率很高的真正原因。
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了和,它就是一个固定运算,梯度下降无需改变任何值。
我们来看一个有若干个超级参数的示例,输入是一个5×5的矩阵。我们采用最大池化法,它的过滤器参数为3×3,即,步幅为1,,输出矩阵是3×3.之前讲的计算卷积层输出大小的公式同样适用于最大池化,即,这个公式也可以计算最大池化的输出大小。

此例是计算3×3输出的每个元素,我们看左上角这些元素,注意这是一个3×3区域,因为有3个过滤器,取最大值9。然后移动一个元素,因为步幅是1,蓝色区域的最大值是9.继续向右移动,蓝色区域的最大值是5。然后移到下一行,因为步幅是1,我们只向下移动一个格,所以该区域的最大值是9。这个区域也是9。这两个区域的最大值都是5。最后这三个区域的最大值分别为8,6和9。超参数,,最终输出如图所示。

以上就是一个二维输入的最大池化的演示,如果输入是三维的,那么输出也是三维的。例如,输入是5×5×2,那么输出是3×3×2。计算最大池化的方法就是分别对每个通道执行刚刚的计算过程。如上图所示,第一个通道依然保持不变。对于第二个通道,我刚才画在下面的,在这个层做同样的计算,得到第二个通道的输出。一般来说,如果输入是5×5×,输出就是3×3×,个通道中每个通道都单独执行最大池化计算,以上就是最大池化算法。
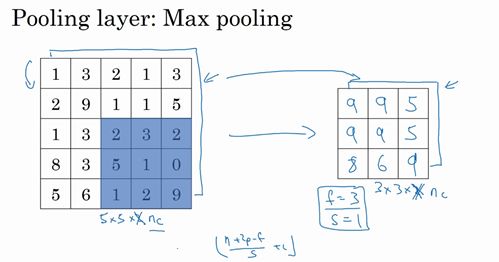
另外还有一种类型的池化,平均池化,它不太常用。我简单介绍一下,这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是3.75,后面依次是1.25、4和2。这个平均池化的超级参数,,我们也可以选择其它超级参数。

目前来说,最大池化比平均池化更常用。但也有例外,就是深度很深的神经网络,你可以用平均池化来分解规模为7×7×1000的网络的表示层,在整个空间内求平均值,得到1×1×1000,一会我们看个例子。但在神经网络中,最大池化要比平均池化用得更多。
总结一下,池化的超级参数包括过滤器大小和步幅,常用的参数值为,,应用频率非常高,其效果相当于高度和宽度缩减一半。也有使用,的情况。至于其它超级参数就要看你用的是最大池化还是平均池化了。你也可以根据自己意愿增加表示padding的其他超级参数,虽然很少这么用。最大池化时,往往很少用到超参数padding,当然也有例外的情况,我们下周会讲。大部分情况下,最大池化很少用padding。目前最常用的值是0,即。最大池化的输入就是,假设没有padding,则输出。输入通道与输出通道个数相同,因为我们对每个通道都做了池化。需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。

除了这些,池化的内容就全部讲完了。最大池化只是计算神经网络某一层的静态属性,没有什么需要学习的,它只是一个静态属性。
关于池化我们就讲到这儿,现在我们已经知道如何构建卷积层和池化层了。下节课,我们会分析一个更复杂的可以引进全连接层的卷积网络示例。