Hive的shell命令及建表
Hive简介
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Hive的架构



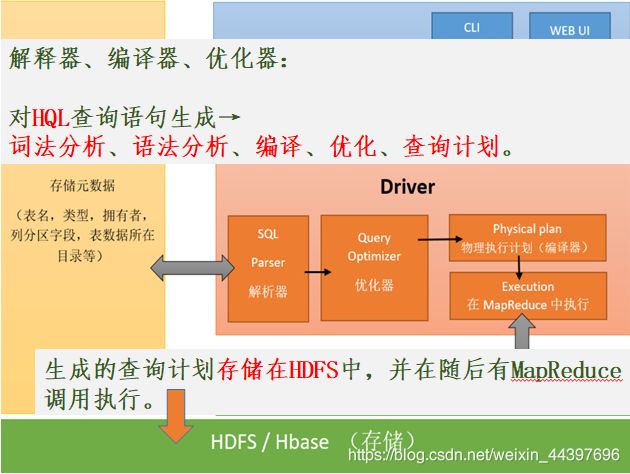
HQL→MR的语言翻译器
构建在Hadoop上的数据仓库框架,数据计算使用MapReduce,数据存储使用HDFS。
设计目的是让SQL技能良好,但Java技能较弱的分析师可以查询海量数据。
Hive 定义了一种类 SQL 查询语言——HQL(类似SQL,但不完全相同)。
通常用于进行离线数据处理(采用MapReduce)
使用hive统计一个网站某天某时的pv、uv访问值
步骤:
在hive中新建数据源表。
导入源文件到hive表中。
对hive原表做一个数据清洗,筛选有用的字段,新建清洗表。
新建分区表,从数据清洗表中把输入导入到分区表。
写HiveSql对分区表的数据进行分组统计。
使用sqoop导出数据到mysql中。
网站项目从Mysql读取这张表的信息。
创建数据源表
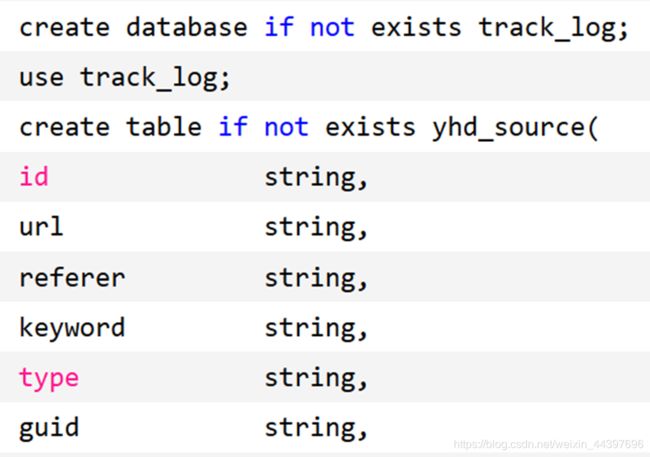

创建清洗表
create table if not exists yhd_clean(
id string,
url string,
guid string,
date string,
hour string)
row format delimited fields terminated by '\t'
insert into table yhd_clean select id,url,guid,substring(trackTime,9,2) date,substring(trackTime,12,2)
hour from yhd_source;
select id,date,hour from yhd_clean limit 5;
创建静态分区表
create table if not exists yhd_part1(
id string,
url string,
guid string
) partitioned by (date string, hour string)
row format delimited fields terminated by '\t'
insert into table yhd_part1 partition(date='28',hour='18') select id,url,guid from yhd_clean where date='28' and hour='18';
insert into table yhd_part1 partition(date='28',hour='19') select id,url,guid from yhd_clean where date='28' and
hour='19';
pv统计
select date,hour,count(url) PV from yhd_part1 group by date,hour;
uv统计
select date,hour,count(distinct(guid)) UV from yhd_part1 group by date,hour;
分区:按照经常查询的字段做不同的分区,从业务字段角度划分,主要用于查询。如按日志产生的日期列进行分区。
分桶:对列值哈希来组织数据的方式,从纯数据角度划分,主要就是用于抽样,表连接。
SQL→Hive Job(MapReduce任务)的整个编译过程分为六个阶段
**Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
**遍历AST Tree,抽象出查询的基本组成单元QueryBlock。
**遍历QueryBlock,翻译为执行操作树OperatorTree。
**逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量。
**遍历OperatorTree,翻译为hive job任务。
**物理层优化器进行hive job任务的变换,生成最终的执行计划
MapReduce实现 HiveQL 常见操作
1.Join的实现原理:
select u.name, o.orderid from order o join user u on o.uid=u.uid;

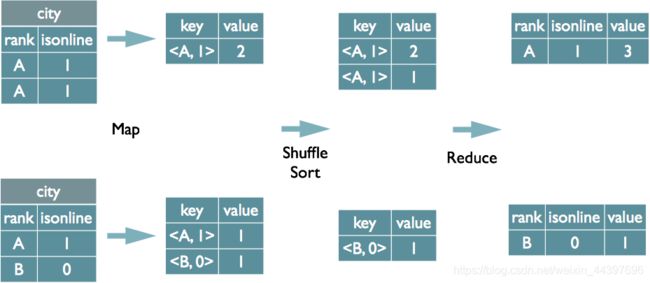
2.Group By的实现原理:
select rank,isonline, count(*) from city group by rank,isonline;
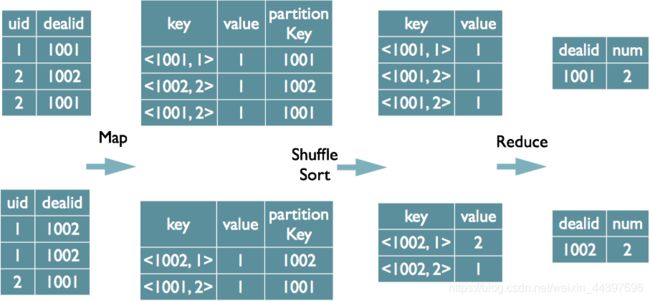
3.Distinct的实现原理:
select dealid,count(distinct uid) num from order group by dealid;
实验 Hive的shell命令及建表
软件 hive-1.1.0-cdh5.7.0.tar.gz
实验步骤
1.安装 Hive
(1)解压Hive
tar -zxvf hive-1.1.0-cdh5.7.0.tar -C /opt/module
(2)配置环境变量
vi /etc/profile添加内容
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
(3)配置hive-env.sh
cd /usr/local/hive/conf
cp -r hive-env.sh.template hive-env.sh
vi hive-env.sh配置内容
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
# export HIVE_AUX_JARS_PATH=
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export HIVE_HOME=/opt/module/hive
# HADOOP_HOME=${bin}/../../hadoop
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=$HIVE_HOME/conf
#Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/opt/module/lib/*
(4)修改 Hive 的配置文件 cd /opt/module/hive-1.1.0-cdh5.7.0/conf vi hive-site.xml,添加一下内容
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123123
2.客户端启动
Hive