Pruning Convolutional Neural Networks for Resource Efficient Inference代码详解
Pruning Filter代码详解
github pytorch版实现
剪枝之后的VGG准确率从98.7% 掉到97.5%.
网络大小从 538 MB压缩到 150 MB.
在i7 CPU上,对一张图的推断时间从 0.78 减少为 0.277 s,几乎是3倍加速。
裁剪filter的依据是:
用Taylor展开来近似pruning的优化问题。
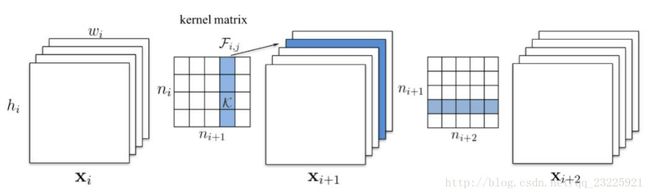
需要注意的是,裁剪某一层的filter后,下一层的weight也需要更新。
接下来是github中的代码详解:
代码中的三个类
class ModifiedVGG16Model
init函数:
model = models.vgg16(pretrained=True)#为加载的VGG16的模型
self.features = model.features #提取VGG16的卷积层做特征提取层
self.classifier = nn.Sequential() #新建3个fc层作为卷积层后的分类器forward函数:
x = self.features(x) #VGG16的卷积层做特征提取层
x = x.view(x.size(0), -1) #展成一维向量作为fc层的输入
x = self.classifier(x) #输入到fc层中,得到最后的输出x
return xclass PrunningFineTuner_VGG16
控制裁剪的整体过程:前向–》获取rank_filter–》计算prune_targets–》裁剪
init函数:
self.train_data_loader = dataset.loader(train_path)#加载数据
self.model = model #是传进来的model,为VGG16
self.criterion = torch.nn.CrossEntropyLoss()#定义网络的损失函数
self.prunner = FilterPrunner(self.model) #一个FilterPrunner类的实例
self.model.train()#设置为网络参数为“可以更新”class FilterPrunner
这个类主要实现:计算需要裁剪的filter
主要函数有:
forward#被PrunningFineTuner_VGG16类的train_batch调用
compute_rank#被forward调用,用于在grad更新时,计算值用于排序
normalize_ranks_per_layer#被PrunningFineTuner类调用,将每层的结果都归一化
get_prunning_plan#被PrunningFineTuner_VGG16类调用
lowest_ranking_filters#被get_prunning_plan调用,计算最小的512个filterstep 1 训练网络
通过如下指令进行网络训练:
python finetune.py –train
进入到finetune.py的main函数中
if __name__ == '__main__':
args = get_args()
if args.train:
model = ModifiedVGG16Model().cuda()#类ModifiedVGG16Model的实例,通过调用类的init函数,会移除VGG后面的fc并新建classifier
fine_tuner = PrunningFineTuner_VGG16(args.train_path, args.test_path, model)#fine_tuner为PrunningFineTuner_VGG16类的实例
if args.train:
fine_tuner.train(epoches = 20)#对新建的3个fc进行训练20个epoch
torch.save(model, "model")#存成modelPrunningFineTuner_VGG16的train函数:
if optimizer is None:
optimizer = \
optim.SGD(model.classifier.parameters(),
lr=0.0001, momentum=0.9)#优化器设置为SGD
for i in range(epoches):#训练epoch次数
print "Epoch: ", i
self.train_epoch(optimizer)
self.test()
print "Finished fine tuning."train_epoch函数对每一个batch分别调用train_batch函数进行训练
train_batch函数:
self.model.zero_grad()
input = Variable(batch)#将tensor转为Variable
if rank_filters:#train阶段为false,prun阶段为true
output = self.prunner.forward(input) #调用FilterPrunner的forward,会计算用于rank的值
#criterion调用CrossEntropyLoss()计算loss,再loss.backward()进行误差回传
self.criterion(output, Variable(label)).backward()
else:
#self.model是VGG16,计算的是VGG16的output与lable的CrossEntropyLoss
self.criterion(self.model(input),Variable(label)).backward()
optimizer.step()#更新参数因为只是train不pruning,所以rank为false,所以对loss进行计算后便更新参数,函数结束。一般训练20个epoch后,在test集上能达到98%的准确率。
step 2 对filter排序
需要调用以下命令:
python finetune.py –prune
if __name__ == '__main__':
elif args.prune:
model = torch.load("model").cuda()#加载train之后的model
fine_tuner = PrunningFineTuner_VGG16(args.train_path, args.test_path, model)#fine_tuner是PrunningFineTuner_VGG16类的实例
elif args.prune:
fine_tuner.prune()调用PruningFineTuner_VGG16类的prue函数:
def prune(self):
self.test()#在裁剪之前test一次
self.model.train()#设置成train模式,参数可调
for param in self.model.features.parameters():#打开所有层,使之可以学习
param.requires_grad = True
number_of_filters = self.total_num_filters() #网络总的filter数目
num_filters_to_prune_per_iteration = 512 #每次裁剪512个fitlter
iterations = int(float(number_of_filters) / num_filters_to_prune_per_iteration)
iterations = int(iterations * 2.0 / 3) #相当于2/3的sum 除以 512 也就是要剪掉2/3需要多少次迭代
print "Number of prunning iterations to reduce 67% filters", iterations
for _ in range(iterations):
print "Ranking filters.. "
#得到需要剪枝的layer和filter索引
prune_targets = self.get_candidates_to_prune(num_filters_to_prune_per_iteration)
layers_prunned = {}
for layer_index, filter_index in prune_targets:
if layer_index not in layers_prunned:
layers_prunned[layer_index] = 0
layers_prunned[layer_index] = layers_prunned[layer_index] + 1 #记录每一层pruning的数目
model = self.model.cpu()
for layer_index, filter_index in prune_targets:
model = prune_vgg16_conv_layer(model, layer_index, filter_index)#将需要裁剪的model裁剪掉,得到新的model
self.model = model.cuda()
message = str(100*float(self.total_num_filters()) / number_of_filters) + "%"
print "Filters prunned", str(message)
self.test()#进行测试
print "Fine tuning to recover from prunning iteration."
optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.train(optimizer, epoches = 10)#再用SGD重新训练10个epoch
print "Finished. Going to fine tune the model a bit more"
self.train(optimizer, epoches = 15)#全部减完之后再训练15个epoch
torch.save(model, "model_prunned")#最后得到裁剪完的model其中调用get_candidates_to_prune函数来生成裁剪对象prune_targets:
def get_candidates_to_prune(self, num_filters_to_prune):
self.prunner.reset()#重置
'''rank_filters = True,train_epoch函数会调用prunner.forward()得到rank_filter'''
self.train_epoch(rank_filters = True)
self.prunner.normalize_ranks_per_layer()#归一化rank_filter
#调用prunner.get_prunning_plan排序得到可以裁剪的对象
return self.prunner.get_prunning_plan(num_filters_to_prune)其中pruner.forward():
def forward(self, x):
self.activations = []
self.gradients = []
self.grad_index = 0
self.activation_to_layer = {}
'''为了计算泰勒值,我们需要forward和backward得到激励值以及梯度'''
activation_index = 0 #有几层conv层
for layer, (name, module) in enumerate(self.model.features._modules.items()):
x = module(x) #module是对应的层 x作为层的输入,得到输出x
if isinstance(module, torch.nn.modules.conv.Conv2d):#如果module是conv2d层
x.register_hook(self.compute_rank)#注册了一个钩子hook,一旦梯度计算完成,便会自动调用compite_rank函数
self.activations.append(x)#将得到的激励值x加到self.activations中
self.activation_to_layer[activation_index] = layer #记录对应的layer索引
activation_index += 1
return self.model.classifier(x.view(x.size(0), -1))#将x展成一维向量,作为后面全连接层classifier的输入,并将输出return其中的钩子注册的compute_rank函数:
activations的维度为:batch filter h w
def compute_rank(self, grad):
activation_index = len(self.activations) - self.grad_index - 1
activation = self.activations[activation_index]
#将activation与grad做点乘,并对每个filter分别求sum
values = \
torch.sum((activation * grad), dim = 0).\
sum(dim=2).sum(dim=3)[0, :, 0, 0].data
#对每个filter得到的值求均值
values = \
values / (activation.size(0) * activation.size(2) * activation.size(3))
if activation_index not in self.filter_ranks:
self.filter_ranks[activation_index] = \
torch.FloatTensor(activation.size(1)).zero_().cuda() #得到和activation.size(1)一样长的一维0向量,长度为filter的个数
self.filter_ranks[activation_index] += values #将算得的values赋给ranks
self.grad_index += 1
由此计算得到self.filter_ranks,其中是每一层对应的每个filter的均值。
现在开始对每一个需要裁剪的(layer,filter)进行剪枝,调用prune.py中的prune_vgg16_conv_layer函数:
#首先找到这个conv后面的一个conv层,记为next_conv
#卷积层的w的维度为:filter in h w
#由于减少了一个filter,所以新的new_conv的维度为:filter-1 in h w
#将[0,filter_index)拷贝到news中
new_weights[: filter_index, :, :, :] = old_weights[: filter_index, :, :, :]
#将[filter_index+1,)拷贝到news的[filter_index,)中,相当于去掉了filter_index这一层
new_weights[filter_index : , :, :, :] = old_weights[filter_index + 1 :, :, :, :]
这一层filter的减少,意味着out_channel的数量减少,对应下一层是减少了in_channel的数量,所以下一层的参数也要改为:filter in-1 h w。
#将除了filter_index的都赋值过来
new_weights[:, : filter_index, :, :] = old_weights[:, : filter_index, :, :]
new_weights[:, filter_index : , :, :] = old_weights[:, filter_index + 1 :, :, :]麻烦的是,如果conv的下一层不是conv层,而是全连接层。
首先要知道fc的权重为out*in,
最后一个conv层有filter个特征图,将每个特征图展成一维向量后(假设长度为hw),拼接成一维向量,作为fc层的输入,所以少了一个filter,意味着这个输入向量少了hw列。
#每一个channel的输入参数数目(一张特征图)
params_per_input_channel = old_linear_layer.in_features / conv.out_channels
#去掉filter_index所对应的params_per_input_channel列参数
new_weights[:, : filter_index * params_per_input_channel] = \
old_weights[:, : filter_index * params_per_input_channel]
new_weights[:, filter_index * params_per_input_channel :] = \
old_weights[:, (filter_index + 1) * params_per_input_channel :]