【TensorFlow随手笔记】tensorboard踩过的坑
出错错误:
1. 无法正常显示
直接点击网址无法访问
解决方案:
直接用 localhost:6006
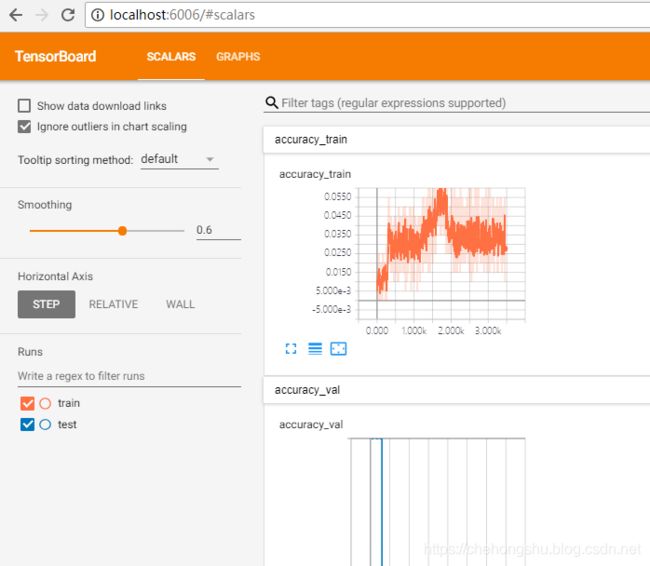
错误二和三
二:
Expected dimension in the range [-1, 1), but got 1 [[Node: accuracy_5/ArgMax_1 = ArgMax[T=DT_FLOAT, Tidx=DT_INT32, output_type=DT_INT64, _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_y_label_0_1, accuracy_5/ArgMax/dimension)]]
三:
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor ' input_placeholder/ys_val-input' with dtype float and shape [378,77][[node input_placeholder/ys_val-input (defined at D:/新建文件夹/79class_claification/TF_CNN.py:121) = Placeholder[dtype=DT_FLOAT, shape=[378,77], _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]] [[{{node handle_onehot_label/input_producer/input_producer/mul/_21}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_68_handle_onehot_label/input_producer/input_producer/mul", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
![]()
思考问题
以上两个问题老是在修改后,调bug过程中不断交互出现。
我以前一直都是好用的,但是在我修改之后程序出现问题。
我本以为是修改后的 arg_max和argmax有区别。
我修改的部分主要为: 分别写出两个过程一个针对traindata,一个针对val_data,因为两个的shape不一样,我用的又是一维卷积所以placeholder那里shape是固定写的。所以针对这两个过程分别加入tensorboard的scalar变量。主要是以下四个。
train_acc, val_acc, train_loss, val_loss
解决问题
经过分析可知,这种情况下不能直接用merged = tf.summary.merge_all()直接把train的标量和val的标量一起merge掉,并且在sess.run的过程中都是喂入 merged,正常来讲应该train和val各有一个merge,之后各自喂到各自的sess上。
修改代码demo如下即可:
with tf.name_scope('loss_func'):
cross_entropy = tf.losses.sparse_softmax_cross_entropy(logits=y_inference, labels=tf.arg_max(ys, 1))
cross_entropy_val = tf.losses.sparse_softmax_cross_entropy(logits=yval_inference, labels=tf.argmax(ys_val, 1))
loss = tf.reduce_mean(cross_entropy)
loss_val = tf.reduce_mean(cross_entropy_val)
summary_losstrain = tf.summary.scalar('loss', loss) ###################################
summary_lossval = tf.summary.scalar('loss_val', loss_val)
with tf.name_scope('train_step_Optimizer'):
train_step = tf.train.GradientDescentOptimizer(learning_rate=LEARNING_RATE_BASE).minimize(loss)
with tf.name_scope('acc_train'):
correct_prediction_train = tf.equal(tf.argmax(ys, 1), tf.argmax(y_inference, 1))
accuracy_train = tf.reduce_mean(tf.cast(correct_prediction_train, tf.float32), name="accuracy_train")
summary_acc_train = tf.summary.scalar('accuracy_train', accuracy_train) ###################
with tf.name_scope('acc_val'):
correct_prediction_val = tf.equal(tf.argmax(ys_val, 1), tf.argmax(yval_inference, 1))
accuracy_val = tf.reduce_mean(tf.cast(correct_prediction_val, tf.float32), name="accuracy_val")
summary_acc_val = tf.summary.scalar('accuracy_val', accuracy_val)######################
with tf.name_scope("save_model"):
Saver = tf.train.Saver()
with tf.Session() as sess:
tf.local_variables_initializer().run()
tf.global_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
#merged = tf.summary.merge_all()
# 修改后
merged_train = tf.summary.merge([summary_losstrain, summary_acc_train])###########################
merged_val = tf.summary.merge([summary_lossval, summary_acc_val])###############################
#train_writer = tf.summary.FileWriter(LOG_DIR, sess.graph)
train_writer = tf.summary.FileWriter(LOG_DIR + '/train', sess.graph)################################
test_writer = tf.summary.FileWriter(LOG_DIR + '/test')##########################################
yy_test_onehot, yy_val_onehot = sess.run([y_test_onehot, y_val_onehot])
validate_feed = {xs_val: X_val, ys_val: yy_val_onehot}
for epoch in range(TRAINING_STEPS):
x_train_batchdata, y_train_batchdata = sess.run([x_train_batch, y_train_batch])
summary_train = sess.run([merged_train], feed_dict={xs: x_train_batchdata, ys: y_train_batchdata})
train_writer.add_summary(summary_train, epoch)
summary_val= sess.run([merged_val], feed_dict=validate_feed)
test_writer.add_summary(summary_val, epoch)