Flink SQL & Table简单实例
Flink SQL & Table简单实例
- 简介
- pom依赖
- 数据源流源码
- 数据源流源码
- FlinkSQL处理代码
-
- OutputSelector处理
- 解析表数据转流数据toRetractStream
- 实现效果
- 附录
-
- 问题描述
- 问题现象
- 原因
- 解决方案
简介
与传统的SQL查询相比,FlinkSQL是动态表查询,SQL不会中止,会不断的执行;
Kafka数据不断的被注入到动态表中,FlinkSQL则会在这张动态表中不断的执行。FLink从0.9版本中支持FLinkSQL,但是目前为止,FlnikSQL和Table没有支持完全的业务场景,有些场景没有调优等。所以需要到官网进行查询是否支持业务场景。
与传统SQL一样,但是增加和窗口和排序。先指定一个 key
Flink SQL&Table位于DataStream和DataSet的上层,正是因为它(Flink SQL&Table)的存在,Flink才真正做到了批流一体:一套API完成批处理和流处理操作。
Calcite->从图中可以看到无论是批查询 SQL 还是流式查询 SQL,都会经过对应的转换器 Parser 转换成为节点树 SQLNode tree,然后生成逻辑执行计划 Logical Plan,逻辑执行计划在经过优化后生成真正可以执行的物理执行计划,交给 DataSet 或者 DataStream 的 API 去执行。
图片来源:王知无《42讲通关Flink》
pom依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
数据源流源码
数据源的pojo用户信息对象数据在下文的博客中的“模拟数据对象代码”中已有说明,不再赘述:
Flink的常见算子和实例代码
数据源流源码
public class UserImageSource implements SourceFunction<UserImage>{
private boolean is_Running = true;
@Override
public void run(SourceContext<UserImage> ctx) throws Exception {
// TODO Auto-generated method stub
int i = 0;
while(is_Running) {
UserImage user = new UserImage();
ctx.collect(user);
//每1秒一个数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
// TODO Auto-generated method stub
is_Running=false;
}
}
FlinkSQL处理代码
public class FlinkSQLDemo {
public static void main(String[] args) throws Exception {
//配置运行环境
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
bsEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv);
//
SingleOutputStreamOperator<UserImage> source = bsEnv.addSource(new UserImageSource()).map(new MapFunction<UserImage, UserImage>() {
@Override
public UserImage map(UserImage value) throws Exception {
// TODO Auto-generated method stub
//不做处理 仅仅转换为DataStream
return value;
}
});
DataStream<UserImage> leader = source.split(new OutputSelector<UserImage>() {
@Override
public Iterable<String> select(UserImage value) {
// TODO Auto-generated method stub
//根据实现方法设置返回类型
List<String> output = new ArrayList<>();
//分流操作:设置分流类别
if(value.getGroupId()==1) {
output.add("leader");
}else {
output.add("stranger");
}
//返回分流类别
return output;
}
//源码: Output object for which the output selection should be made. 输出的是选中类别,即select("leader")标记的UserImage value 这个value在源码中是OUT
}).select("leader");
//复制方法
DataStream<UserImage> stranger = source.split(new OutputSelector<UserImage>() {
@Override
public Iterable<String> select(UserImage value) {
// TODO Auto-generated method stub
//根据实现方法设置返回类型
List<String> output = new ArrayList<>();
//分流操作:设置分流类别
if(value.getGroupId()==1) {
output.add("leader");
}else {
output.add("stranger");
}
//返回分流类别
return output;
}
//源码: Output object for which the output selection should be made. 输出的是选中类别,即select("leader")标记的UserImage value 这个value在源码中是OUT
}).select("stranger");
leader.printToErr();
stranger.printToErr();
//创建SQL表 //TableName,DataStream,cloumn
bsTableEnv.createTemporaryView("leaderTable", leader, "name,groupId,groupName");
bsTableEnv.createTemporaryView("strangerTable", stranger, "name,groupId,groupName");
Table queryTable = bsTableEnv.sqlQuery("select name,groupId,groupName from leaderTable");
//打印出多态表单的所有数据
queryTable.printSchema();
//打印筛选数据:表转换为流;
//toRetractStream缩进模式:始终可以使用此模式。返回值是boolean类型。它用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回
bsTableEnv.toRetractStream(queryTable, TypeInformation.of(new TypeHint<Tuple3<String,Integer,String>>(){
})).print();
//bsTableEnv.toRetractStream(queryTable, TypeInformation.of(new TypeHint<Tuple4<Integer,String,Integer,String>>(){
})).print();
bsEnv.execute("streaming sql job");
}
}
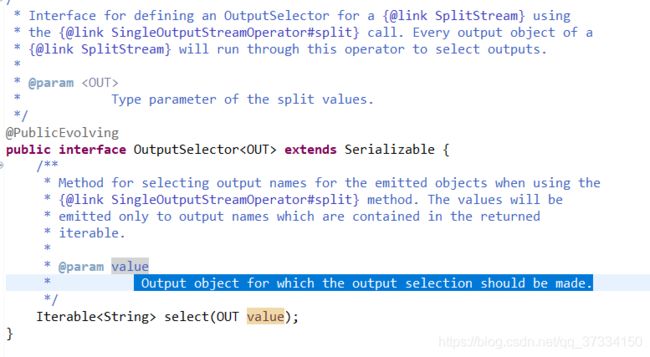
OutputSelector处理
源码中:
Output object for which the output selection should be made. 为输出对象选中类别,即处理代码中的output的arraylist是标记输出流对象数据的类别,select(“leader”)标记的UserImage value则是选中类别为"leader"的对象。
解析表数据转流数据toRetractStream
使用flinkSQL处理实时数据把表转化成流有两种方法:
toAppendStream与toRetractStream
- toAppendStream
追加模式:只有在动态Table仅通过INSERT更改修改时才能使用此模式,即它仅附加,并且以前发出的结果永远不会更新。
如果更新或删除操作使用追加模式会失败报错
- toRetractStream:
始终可以使用此模式。返回值是boolean类型。它用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回
引用来源:flink实战——flinkSQL 追加模式与缩进模式(toRetractStream)的区别
实现效果
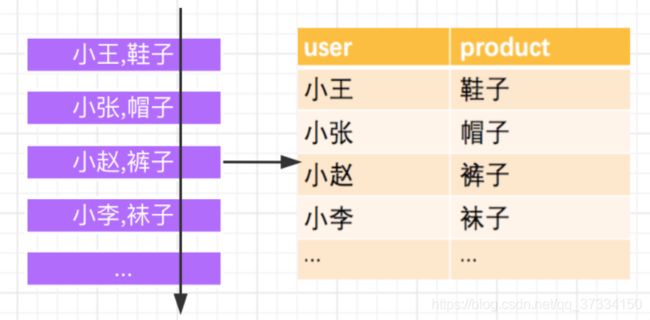
FlinkSQL过滤出主角团——草帽海贼团的用户画像。

附录
问题描述
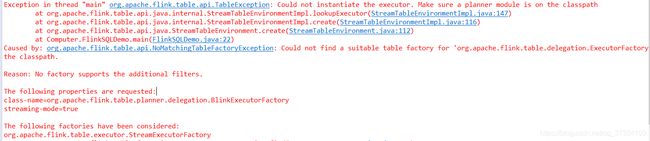
Exception in thread “main” org.apache.flink.table.api.TableException: Could not instantiate the executor. Make sure a planner module is on the classpath
at org.apache.flink.table.api.java.internal.StreamTableEnvironmentImpl.lookupExecutor(StreamTableEnvironmentImpl.java:147)
at org.apache.flink.table.api.java.internal.StreamTableEnvironmentImpl.create(StreamTableEnvironmentImpl.java:116)
at org.apache.flink.table.api.java.StreamTableEnvironment.create(StreamTableEnvironment.java:112)
at Computer.FlinkSQLDemo.main(FlinkSQLDemo.java:22)
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for ‘org.apache.flink.table.delegation.ExecutorFactory’ in
the classpath.
问题现象
原因
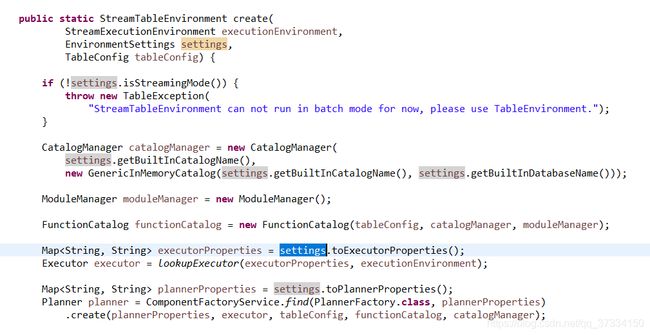
定位到EnvironmentSettings有问题。
解决方案
修改为StreamTableEnvironment 多态的StreamExecutionEnvironment参数形式。
//配置运行环境
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
bsEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv);
如果看懂了点个赞,评论鼓励一下,给编者点小动力,不做拿来主义者,谢谢啦~