R语言绘制州市地图进行可视化分析
目的
将经纬度数据对应的数值先进行聚类,然后将聚类的结果和经纬度数据进行合并,将不同的聚类结果在地图上进行热力板块展示。type是聚类的类型结果
数据展示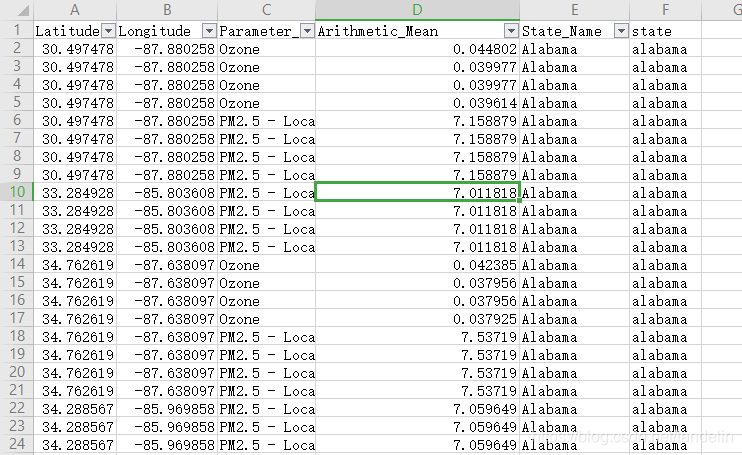
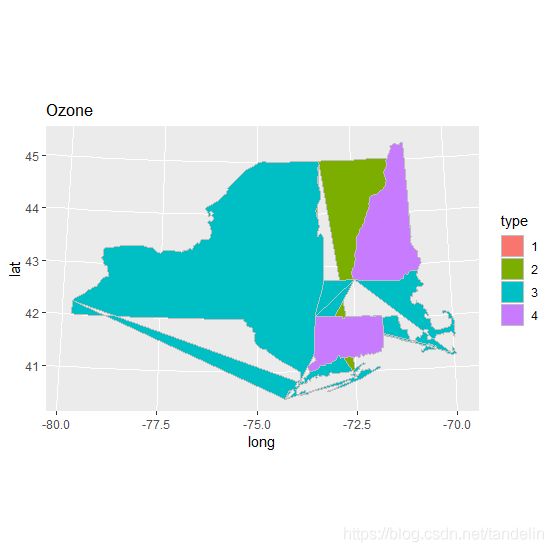
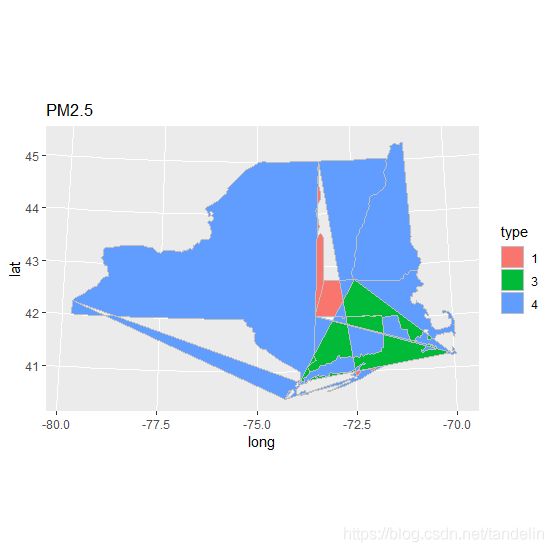
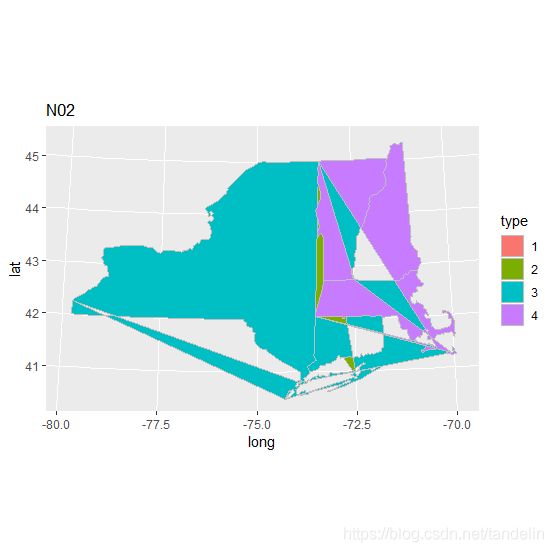
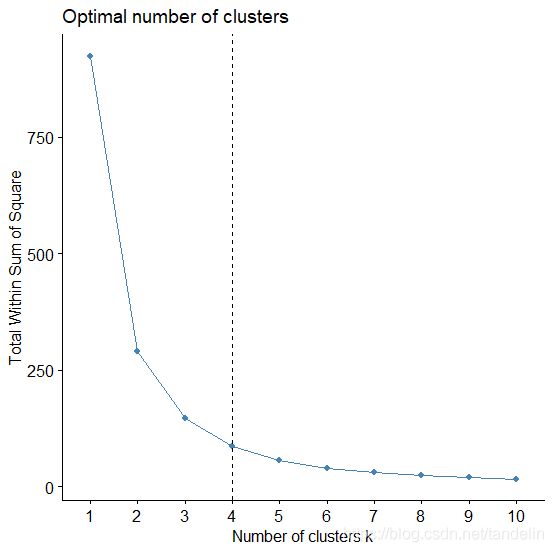
聚类结果判断图,聚成4类。
聚类包加载
install.packages("factoextra")
数据读取
data=read.csv("C:\\Users\\Administrator\\Desktop\\Rap\\annual_conc_by_monitor_20181.csv",header=T)
## 得出有效数据:筛选列数:根据确定要研究的变量指标名称只需要选择5列:"Latitude","Longitude","Parameter_Name","Arithmetic_Mean","County_Name"
head(data)
subdata1<-data[,c("Latitude","Longitude","Parameter_Name","Arithmetic_Mean","State_Name")]
## 得出分析数据:筛选符合条件的数据:筛选城市、筛选研究指标
# 1.在指标State_Name中筛选城市New York, Vermont, New Hampshire, Massachusetts, Connecticut 这五个地方
# 2.在指标Parameter_Name中筛选 Ozone, Nitrogen dioxide, PM2. 5 local这三个变量值。
str(subdata1)
subdata2 <- subset(subdata1,State_Name=c("New York","Vermont","New Hampshire","Massachusetts","Connecticut"))
subdata2$State=tolower(subdata2$State_Name)
newdata1 = subdata2[subdata2$Parameter_Name == 'Ozone',]
newdata2 = subdata2[subdata2$Parameter_Name == 'PM2.5 - Local Conditions',]
newdata3 = subdata2[subdata2$Parameter_Name == 'Nitrogen dioxide (NO2)',]
endata1 <- newdata1
endata2 <- newdata2
endata3 <- newdata3
#write.csv(endata1,"Ozone.csv")
#write.csv(endata2,"Nitrogen dioxide.csv")
#write.csv(endata3,"PM2.5.csv")
str(endata1)
聚类分析
#install.packages("fpc")
library(fpc)
## 聚类数据提取
mydata1<-endata1[,"Arithmetic_Mean"]
mydata2<-endata2[,"Arithmetic_Mean"]
mydata3<-endata3[,"Arithmetic_Mean"]
## 聚类个数判断
library(factoextra)
df1 <- scale(mydata1)
fviz_nbclust(df1, kmeans, method = "wss") + geom_vline(xintercept = 4, linetype = 2) ##得出第一个数据聚成4类
df2 <- scale(mydata2)
fviz_nbclust(df2, kmeans, method = "wss") + geom_vline(xintercept = 4, linetype = 2)
df3 <- scale(mydata3)
fviz_nbclust(df3, kmeans, method = "wss") + geom_vline(xintercept = 4, linetype = 2)
## 进行聚类
kmd1=kmeans(mydata1,centers = 4)
kmd2=kmeans(mydata2,centers = 4)
kmd3=kmeans(mydata3,centers = 4)
##聚类结果合并
cldata1<-cbind(endata1,type=kmd1$cluster) #聚类结果和原始数据合并
cldata2<-cbind(endata2,type=kmd2$cluster) #聚类结果和原始数据合并
cldata3<-cbind(endata3,type=kmd3$cluster) #聚类结果和原始数据合并
head(cldata1)
str(cldata1)
cldata1$type=factor(cldata1$type)
cldata2$type=factor(cldata2$type)
cldata3$type=factor(cldata3$type)
地图绘制
euro <- map_data("state", region = c("new york","vermont",
"new hampshire","massachusetts", "connecticut"))
hb_map1<-merge(euro,cldata1,by.x="region",by.y="State")
hb_map2<-merge(euro,cldata2,by.x="region",by.y="State")
hb_map3<-merge(euro,cldata3,by.x="region",by.y="State")
### 地图1
ggplot(hb_map1,aes(x=long,y=lat,fill=type))+
geom_polygon(colour="grey")+
coord_map("polyconic")+ggtitle("Ozone")
### 地图2
ggplot(hb_map2,aes(x=long,y=lat,fill=type))+
geom_polygon(colour="grey")+
coord_map("polyconic")+ggtitle("PM2.5")
### 地图3
ggplot(hb_map3,aes(x=long,y=lat,fill=type))+
geom_polygon(colour="grey")+
coord_map("polyconic")+ggtitle("N02")