NLP预训练模型4 -- 训练方法优化(RoBERTa、T5)
系列文章,请多关注
NLP预训练模型1 – 综述
NLP预训练模型2 – BERT详解和源码分析
NLP预训练模型3 – 预训练任务优化(ERNIE、SpanBERT)
NLP预训练模型4 – 训练方法优化(RoBERTa、T5)
NLP预训练模型5 – 模型结构优化(XLNet、ALBERT、ELECTRA)
NLP预训练模型6 – 模型轻量化(ALBERT、Q8BERT、DistillBERT、TinyBERT等)
Transformer家族1 – Transformer详解和源码分析
1 背景
上文 NLP预训练模型3 – 预训练任务优化(ERNIE、SpanBERT)我们从预训练任务的角度讲解了如何对BERT进行优化,本文我们从训练方法的角度来讲解BERT优化。
训练方法包括数据语料、文本预处理、超参调整等。
- BERT使用的一套超参,比如batch_size、training steps、optimizer、learning rate,是否还有优化的空间呢?每个深度学习调参侠都知道答案是显然的。虽然BERT在大模型大数据的作用下,对超参不是很敏感,但超参调整始终是模型优化一个绕不开的话题。
- BERT使用了BooksCorpus和English Wikipedia,总共16G的数据,我们是否还能提供更多数据来提高performance呢?答案也是显然的,深度学习非常依赖大数据,more data,more performance。数据量越大,模型可学习的信息也就越多,performance也就越强。
本文从数据语料和超参调整的角度,来讲解怎么通过训练方法优化来提升预训练模型performance。训练方法优化这个角度始终让人感觉不像模型结构优化、预训练任务优化那样fancy,比如RoBERTa就被ICLR拒稿了。但个人认为,在工业界应用中,还是效果为王。不管白猫黑猫,只要抓到耗子就是好猫嘛。况且Google、Facebook耗费大量人力物力,大力出奇迹搞出来的预训练模型,在工业界下游任务中确实很香。本文主要以RoBERta和T5两个模型为例,进行分析。
2 RoBERTa
 论文信息:2019年7月,Facebook & 华盛顿大学
论文信息:2019年7月,Facebook & 华盛顿大学
论文地址 https://arxiv.org/abs/1907.11692
代码和模型地址 https://github.com/pytorch/fairseq
2.1 主要创新
2.1.1 Dynamic Masking
BERT在预处理阶段,对sequence进行了随机mask。训练时,同一个sequence中的mask,在不同的epochs中是不会改变的,也就是static masking静态掩码。这种固定mask的方式,不利于学习到更多不同信息。RoBERTa采用了动态掩码,dynamic Masking的方式,步骤为
- 将原始语料复制10份
- 每一份语料随机选择15%的token进行mask,[mask]、replace、keep的比例仍然为80%、10%、10%。
通过这种类似于cross-validation的方式,使得每一份语料产生了不同的mask,从而可以学习到更多不同信息。总共训练40个epochs,10份语料的情况下,每份语料应用到4个epochs中。这种方式就叫dynamic masking。
动态掩码是否有效果呢,实验证明,还是能提高一点performance的。
如上所示,效果不算很明显,原因应该是BERT包含的数据本身就很大了,信息量已经很充足了,故dynamic masking带来的信息增益不是很明显。
2.1.2 without NSP
在SpanBERT中,我们也提到过NSP反而会带来一定的副作用,主要原因为
- 两个语句拼接起来降低了单个语句长度(可能被截断),而长语句有利于模型学到更多信息,有利于预测mask
- NSP中的负样本,与当前语句关联度不大,不利于预测当前语句的mask。也就是NSP使得MLM任务引入了噪声
RoBERTa对有没有NSP,以及如何构建sequence,也进行了充足的实验,如下
作者进行了四种不同的sequence构造方法,进行了对比实验,如下:
- SEGMENT-PAIR + NSP:原始BERT的做法,仍然采用MLM + NSP,segment为来自同一个文档,或不同文档的多个句子,最后按512截断。两部分构成pair。
- SENTENCE-PAIR + NSP:MLM + NSP,两个来自同一文档或不同文档的,单个句子。这样会大大缩短sequence的长度,经常远远小于512 token。从上表也可以看到,其效果最差。故尽量使sequence长度更长,容纳更多信息,有助于提升模型performance。
- FULL-SENTENCES:去掉了NSP,不构造语句对pair。来自同一文档或不同文档的多个句子,按照512截断。从实验中可见,去掉NSP有助于提升模型效果,原因就是最上面分析的两点。
- DOC-SENTENCES:去掉了NSP,与FULL-SENTENCES不同的是,它的句子全部来自于同一个文档。从实验中可见,来自同一文档效果更好,这是因为减少了MLM的噪音。
RoBERTa的各种实验,基本是给NSP判了死刑。后面越来越多文章,都要么舍弃了NSP,要么对其进行了改造。
2.1.3 超参优化,增大batch size
RoBERTa对超参也进行了充分实验,增大batch size和训练迭代次数,有助于提升模型performance。 在相同总训练step的情况下,batch size的增加可以提升模型效果。这也很容易理解,数据量大的情况下,适当增加batch size可以有助于模型跳出局部最优点,单次训练信息量更充足,视野更宽阔。甚至有人还在尝试32k的batch size,只能说有矿真好。
在相同总训练step的情况下,batch size的增加可以提升模型效果。这也很容易理解,数据量大的情况下,适当增加batch size可以有助于模型跳出局部最优点,单次训练信息量更充足,视野更宽阔。甚至有人还在尝试32k的batch size,只能说有矿真好。
作者对总训练次数steps也做了分析,如下表,在相同data和batch size情况下,对比了总训练次数steps,分别在100k、300k、500k下的效果,最后还是steps=500k效果最好。毕竟训练充分,大力出奇迹嘛。但也要注意不要过拟合了。
2.1.4 增大数据量
原始BERT采用了BooksCorpus和English Wiki语料,总共16GB。XLNet认为是13G,主要差别在于二者English Wiki的预处理过滤方法不同,可以基本认为是一个意思。RoBERTa将原始语料增大到了160GB。主要包括
- BERT原始语料,16GB。原始语料来自BooksCorpus和English Wiki,质量很高。
- CC-NEWS,76GB。新闻语料实时性很强,有助于学习到很多新的实体和知识。
- OPENWEBTEXT,38GB。社区新闻语料,有助于学习到真实人类口语化表达,以及新的知识。提升模型泛化能力
- STORIES,31GB。故事风格的语料。
增大数据量带来的效果还是很明显的,上面那张表中对比了16GB和160GB语料下的模型效果。增大数据量能带来一定的模型效果提升。
2.1.5 文本编码
原始BERT采用字符级别的BPE编码,英文vocab size为30k。容易出现UNK问题,影响模型效果。RoBERTa采用了Byte级别的BPE词汇表,vocab size为50k。vocab size的增加使得模型参数量有所增加,BERT-base增加了15M,BERT-large增加了20M。但也提升了一定的效果。
2.2 实验结果
RoBERTa大力出奇迹,朴实无华的方法,带来了模型效果较大的提升,在GLUE上的表现远超BERT,如下表。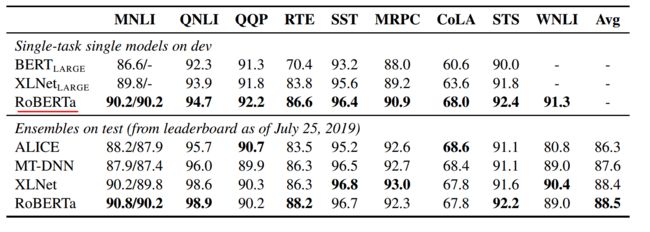
同时在SQuAD和RACE上效果也是比BERT,提升了很多。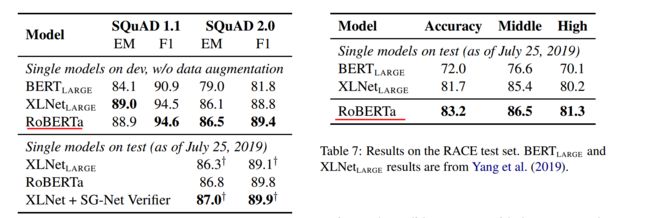
RoBERTa虽然创新点不是很fancy,其大力出奇迹的方法也没法复现,但确实大大提升了下游任务的performance。也使得各种比赛中,RoBERTa的应用越来越广泛。
3 T5

论文信息:2019年10月,谷歌
论文地址 https://arxiv.org/abs/1910.10683
代码和模型地址 https://github.com/google-research/text-to-text-transfer-transformer
3.1 主要创新
3.1.1 任务框架
T5创造性的将每个NLP任务,包括NLU和NLG,统一成了"text-to-text"的问题。如下图在机器翻译、文本分类、文本相似度、文本摘要四个不同任务上,添加不同的prefix在输入上,即可通过生成模型得到输出结果。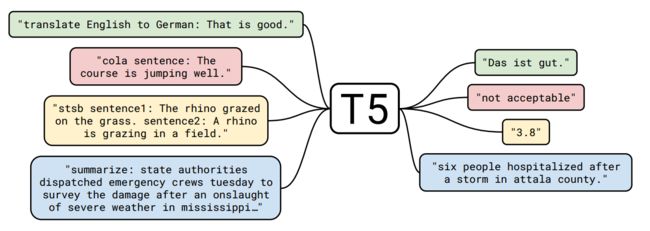
3.1.2 模型结构
由于统一成了生成问题,故采用了原版Transformer的encoder和decoder。而不像BERT仅采用了Transformer Encoder。不同之处在于采用了position embedding采用了相对位置编码。根据self-attention中「key」和「query」之间的偏置生成一个不同的position embedding,而不是固定的位置编码。
3.1.3 C4语料
作为大力出奇迹的典范,T5怎么可能会少了数据上的创新。T5采用了750GB的C4语料(**Colossal Clean Crawled Corpus **),大大超过了RoBERTa的160GB。对爬取到的网络数据,进行了很细致的清洗,大大提高了语料数量和质量。清洗过程我们就不赘述了。
3.1.4 训练方法
在训练方法层面,T5集众家之所长,进行了充分的对比实验,可谓是良心之作。
- 参考SpanBERT,采用span masking的方式,mask 15% token,span平均长度为3.
- 训练steps更长,1M steps
- 使用multi-task,在无监督数据中混入一些有监督任务数据
- fine-tune阶段参考了MT-DNN,先利用glue和super-glue任务,进行multi-task精调,减少了过拟合,并充分利用了有监督数据。然后在各个特定任务上单独精调。
- seq2seq的decoder,大部分采用了greedy decoding,对于机器翻译等语句较长的采用了beam search
3.2 实验结果
3.2.1 模型参数量
T5最大模型可达110亿参数,是BERT-base的100倍。真的是大力出奇迹啊。 为了适应不同使用场景,T5有五个不同size。Small、Base、Large、3B 和 11B, 模型参数量分别为 6000 万、2.2 亿、7.7 亿、30 亿和 110 亿。
为了适应不同使用场景,T5有五个不同size。Small、Base、Large、3B 和 11B, 模型参数量分别为 6000 万、2.2 亿、7.7 亿、30 亿和 110 亿。
3.2.2 GLUE结果
T5五个不同size模型在glue上的结果如下,11B参数量的T5模型,刷新了大多数任务的SOTA。
4 其他方法和总结
增加语料数据和精细化调参,其他论文和模型也有一定的体现。比如XLNet采用了126GB数据,ERNIE(baidu)增加了很多中文语料。语料数据的增加和精细化调参,对提升模型performance还是很重要的。虽然不是那么fancy,而且需要大量人力物力投入,但还是大大提升了下游任务效果,造福了工业界。
系列文章,请多关注
NLP预训练模型1 – 综述
NLP预训练模型2 – BERT详解和源码分析
NLP预训练模型3 – 预训练任务优化(ERNIE、SpanBERT)
NLP预训练模型4 – 训练方法优化(RoBERTa、T5)
NLP预训练模型5 – 模型结构优化(XLNet、ALBERT、ELECTRA)
NLP预训练模型6 – 模型轻量化(ALBERT、Q8BERT、DistillBERT、TinyBERT等)
Transformer家族1 – Transformer详解和源码分析