MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
[arxiv: https://arxiv.org/pdf/1904.11492.pdf] [github: https://github.com/xvjiarui/GCNet; https://github.com/dl19940602/GCnet-pytorch]
我的博客尽可能提取文章内的主要传达的信息,既不是完全翻译,也不简单粗略。论文的motivation和网络设计细节,将是我写这些博客关注的重点。
[Non-Local Attention 系列]
Non-local neural networks
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond [my CSDN]
Asymmetric Non-local Neural Networks for Semantic Segmentation [my CSDN]
Efficient Attention: Attention with Linear Complexities [my CSDN]
CCNet: Criss-Cross Attention for Semantic Segmentation [my CSDN]
Non-locally Enhanced Encoder-Decoder Network for Single Image De-raining [my CSDN]
Image Restoration via Residual Non-local Attention Networks [my CSDN]
Table of Contents
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
Abstract
Introduction
Analysis on Non-local Networks
Revisiting the Non-local Block
Analysis
Method
Simplifying the Non-local Block
Global Context Modeling Framework
Global Context Block
My Note
Abstract
The Non-Local Network (NLNet) presents a pioneering approach for capturing long-range dependencies, via aggregating query-specific global context to each query position. However, through a rigorous empirical analysis, we have found that the global contexts modeled by non-local network are almost the same for different query positions within an image.
NLNet可以捕获long-range dependencies,即一个query position可以对应于特定的global context。但本文发现,对于不同的query positions, 建模到的global contexts几乎一致。如下图。(这意味着不需要学习每个query position对应的global context。)
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第1张图片](http://img.e-com-net.com/image/info8/26233e737f9745aca9fc755a2c4794f4.jpg)
In this paper, we take advantage of this finding to create a simplified network based on a query-independent formulation, which maintains the accuracy of NLNet but with significantly less computation. We further observe that this simplified design shares similar structure with Squeeze-Excitation Network (SENet). Hence we unify them into a three-step general framework for global context modeling. Within the general framework, we design a better instantiation, called the global context (GC) block, which is lightweight and can effectively model the global context. The lightweight property allows us to apply it for multiple layers in a backbone network to construct a global context network (GCNet), which generally outperforms both simplified NLNet and SENet on major benchmarks for various recognition tasks. The code and configurations are released at https://github.com/xvjiarui/GCNet.
本文的GCNet,是一个query-independent formulation,而且保持NLNet准确度的同时,减少计算量。这种简单的设计结构上与SENet类似。但SENet不具备global context modeling。于是设计了global context (GC) block,即能够像NLNet一样有效的对全局上下文建模,又能够像SENet一样lightweight。这种lightweight特征可以用于多个层当中,可以超越NLNet和SENet。
Introduction
Capturing long-range dependency, which aims to extract the global understanding of a visual scene, is proven to benefit a wide range of recognition tasks, such as image/video classification, object detection and segmentation.
获取long-range dependency的目的是实现全局理解,这有利于high-level视觉应用,如分类、识别、语义分割等。
In convolution neural networks, as the convolution layer builds pixel relationship in a local neighborhood, the long-range dependencies are mainly modeled by deeply stacking convolution layers. However, directly repeating convolution layers is computationally inefficiente. This would lead to ineffective modeling of long-range dependency, due in part to difficulties in delivering messages between distant positions.
CNN方法的局限:建立的是像素在临近邻域内的关系,学习long-range dependency需要堆叠很多层网络,这样的堆叠方式计算效率不高,且距离很远的两个点的long-range dependency未必能学的很好。
The query-specific attention weights in the non-local network generally imply the importance of the corresponding positions to the query position. While visualizing the query-specific importance weights would help the understanding in depth, such analysis was largely missing in the original paper. We bridge this regret, as in Figure 1, but surprisingly observe that the attention maps for different query positions are almost the same, indicating only query-independent dependency is learnt.
NLNet原文并没有分析query-specific importance weights能够起到提高理解深度的作用。而本文发现,不同的query positions对应的attention map几乎一致,即只有query-independent dependency被学习到。
之后的两段写得很深奥,因为这是整个文章的原理缩影。不妨先看正文,再回读,方可理解。
Analysis on Non-local Networks
Revisiting the Non-local Block
这节的目的是简单介绍NLNet的原理和结构。顺便给出模型在本文中的书写格式。
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第2张图片](http://img.e-com-net.com/image/info8/97c6103204d444e8bc8455833c306ca9.jpg)
We denote ![]() as the feature map of one input instance (e.g., an image or video), where Np is the number of positions in the feature map (e.g., Np=H·W for image, Np=H·W·T for video). x and z denote the input and output of the non-local block, respectively, which have the same dimensions. The non-local block can then be expressed as
as the feature map of one input instance (e.g., an image or video), where Np is the number of positions in the feature map (e.g., Np=H·W for image, Np=H·W·T for video). x and z denote the input and output of the non-local block, respectively, which have the same dimensions. The non-local block can then be expressed as
![]()
where i is the index of query positions, and j enumerates all possible positions. f (xi , xj ) denotes the relationship between position i and j, and has a normalization factor C (x). Wz and Wv denote linear transform matrices (e.g., 1x1 convolution). For simplification, we denote ![]() as normalized pairwise relationship between position i and j.
as normalized pairwise relationship between position i and j.
本段给出本文对NLNet的数学书写方式。看上图,很容易理解。图中给的wij是Embedded Gaussian。
Four instantiations of the non-local block with different ωij are designed, namely Gaussian, Embedded Gaussian, Dot product, and Concat.
这段介绍了四种常用的normalized pairwise relationships。上图中,Embedded Gaussian可表示为:

可以参考 [2018CVPR, Non-local Neural Networks]。
The non-local block can be regarded as a global context modeling block, which aggregates query-specific global context features (weighted averaged from all positions via a query-specific attention map) to each query position. As attention maps are computed for each query position, the time and space complexity of the non-local block are both quadratic to the number of positions Np.
因为attention maps需要对每个query position计算,所以时间和空间复杂度都是Np的二次方。(耗时,耗内存。)
Analysis
这段是进一步证实一个惊人的发现:for different query positions, their attention maps are almost the same!
Results for two distance measures on two standard tasks are shown in Table 1. First, large values of cosine distance in the ‘input’ column show that the input features for the non-local block can be discriminated across different positions. But the values of cosine distance in ‘output’ are quite small, indicating that global context features modeled by the non-local block are almost the same for different query positions. Both distance measures on attention maps (‘att’) are also very small for all instantiations, which again verifies the observation from visualization. In other words, although a non-local block intends to compute the global context specific to each query position, the global context after training is actually independent of query position. Hence, there is no need to compute query-specific global context for each query position, allowing us to simplify the non-local block.
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第3张图片](http://img.e-com-net.com/image/info8/fbd7097bde8249ddb732ef4217733132.jpg)
从统计分析方法,发现输出的余弦距离值非常小,这表明非局部块所建模的全局上下文特征对于不同的query positions几乎是相同的。
‘att’的余弦距离和Jensen-Shannon divergence (JSD)都很小,即说明attention maps are almost the same。
换句话说,尽管NLNet计算特定于每个query positions的全局上下文,但是训练后的全局上下文实际上独立于query position。因此,不需要为每个query positions计算特定于query 的全局上下文,从而允许我们简化NLNet。
Method
Simplifying the Non-local Block
we adopt the most widely-used version, Embedded Gaussian, as the basic non-local block.
we simplify the non-local block by computing a global (query-independent) attention map and sharing this global attention map for all query positions.
Following the results in [2018CVPR, Relation networks for object detection] that variants with and without Wz achieve comparable performance, we omit Wz in the simplified version. Our simplified non-local block is defined as
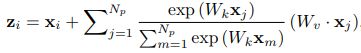 (Eqn 2)
(Eqn 2)
如下图:1. 采用了Embedded Gaussian;2. 共享一个global attention map (从Wk出来只有1xHxW); 3. 省略了Wz,因为发现有没有它对结果没什么影响。
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第4张图片](http://img.e-com-net.com/image/info8/cf206802ab834b40a6948503ecb7b3d5.jpg)
To further reduce the computational cost of this simplified block, we apply the distributive law to move Wv outside of the attention pooling, as
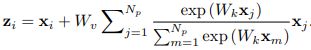 (Eqn 3)
(Eqn 3)
The FLOPs of the 1x1 conv Wv is reduced from O(HWC2 ) to O(C2 ).
进一步简化,将Wv移出attention pooling,如下图。此时浮点计算复杂度从 O(HWC^2 ) 降到O(C^2 )!
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第5张图片](http://img.e-com-net.com/image/info8/a06c393521a04a6e98d59f9a1c541611.jpg)
Different from the traditional non-local block, the second term in Eqn 3 is independent to the query position i, which means this term is shared across all query positions i. We thus directly model global context as a weighted average of the features at all positions, and aggregate (add) the global context features to the features at each query position.
和NLNet不同,Eqn3 的第二项独立于query position,也就是说这一项能够共享于所有的query position。所以,global context可以直接作为所有位置的特征的加权平均,然后将得到的全局上下文特征加到输入上(残差模型)。
In experiments, we directly replace the non-local (NL) block with our simplified non-local (SNL) block, and evaluate accuracy and computation cost on three tasks, object detection on COCO, ImageNet classification, and action recognition, shown in Table 2(a), 4(a) and 5. As we expect, the SNL block achieves comparable performance to the NL block with significantly lower FLOPs.
试验证明了,这种简单粗暴的方式,在不影响准确率的同时,大大减少了计算复杂度。
Global Context Modeling Framework
上面simplified non-local (SNL) 的整个流程即为:
(a) global attention pooling, which adopts a 1x1 convolution Wk and softmax function to obtain the attention weights, and then performs the attention pooling to obtain the global context features
(b) feature transform via a 1x1 convolution Wv
(c) feature aggregation, which employs addition to aggregate the global context features to the features of each position.
We regard this abstraction as a global context modeling framework:
context modeling;feature transform;fusion function
将上述模型进一步抽象,即一个Global Context Modeling Framework可以归结为包含这样三个部分:
context建模;特征传递;融合函数
Interestingly, the squeeze-excitation (SE) block proposed in [14] is also an instantiation of our proposed framework.
Different from the non-local block, this SE block is quite lightweight, allowing it to be applied to all layers with only a slight increase in computation cost.
SENet 也可以归结为这样的结构。
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第6张图片](http://img.e-com-net.com/image/info8/fd7a76543c034fad836ab7e01eeba80e.jpg)
Global Context Block
In the simplified non-local block, the transform module has the largest number of parameters, including from one 1x1 convolution with C·C parameters. When we add this SNL block to higher layers, e.g. res5, the number of parameters of this 1x1 convolution, C·C=2048·2048, dominates the number of parameters of this block.
SNL block在fusion过程还是会产生很多参数。
【我的笔记】我们一般用NLNet只用于整个网络的low-level端和后面的high-level端,一般C=64。本文的作者的一个目的便是,希望SNL能放在网络的任何一层中,这才有了GCNet的诞生,否则到SNL就停止了。
To obtain the lightweight property of the SE block, this 1x1 convolution is replaced by a bottleneck transform module, which significantly reduces the number of parameters from C·C to 2·C·C/r, where r is the bottleneck ratio and C/r denotes the hidden representation dimension of the bottleneck. With default reduction ratio set to r=16, the number of params for transform module can be reduced to 1/8 of the original SNL block.
于是模仿SENet,采用瓶颈模式,参数从C·C 降到 2·C·C/r。r=16,也就是参数再次降低到SNL 的1/8。最终模型如下图。
![MyDLNote - Network: [NL系列] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond_第7张图片](http://img.e-com-net.com/image/info8/e5b724db45344427a013cbce59dabca2.jpg)
As the two-layer bottleneck transform increases the difficulty of optimization, we add layer normalization inside the bottleneck transform (before ReLU) to ease optimization, as well as to act as a regularizer that can benefit generalization.
两层瓶颈传播会增加最优化的难度(为什么?),在ReLU前增加了一层归一化层使得最优化更容易(为什么?),同时也可以用来做为正则化,有益于泛化。
The detailed architecture of the global context (GC) block is formulated as:
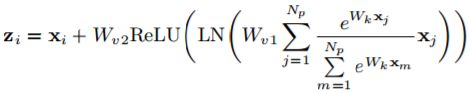
Specifically, our GC block consists of:
(a) global attention pooling for context modeling;
(b) bottleneck transform to capture channel-wise dependencies; and
(c) broadcast element-wise addition for feature fusion.
给出GCNet的表达式,也包括前面提到的三个过程。
Since the GC block is lightweight, it can be applied in multiple layers to better capture the long-range dependency with only a slight increase in computation cost. Taking ResNet-50 for ImageNet classification as an example, GC-ResNet-50 denotes adding the GC block to all layers (c3+c4+c5) in ResNet-50 with a bottleneck ratio of 16. GCResNet-50 increases ResNet-50 computation from ∼3.86 GFLOPs to ∼3.87 GFLOPs, corresponding to a 0.26% relative increase. Also, GC-ResNet-50 introduces ∼2.52M additional parameters beyond the ∼25.56M parameters required by ResNet-50, corresponding to a ∼9.86% increase.
这段讲GC block是如何嵌入到ResNet的。
GC-ResNet-50是将GC block嵌入到 all layers (c3+c4+c5) in ResNet-50。
运行时间,比原ResNet-50增加了 ∼3.86 GFLOPs to ∼3.87 GFLOPs(增加率为~0.26%)。
参数量,比原ResNet-50增加了 ∼2.52M(增加率为~9.86%)。
Global context can benefit a wide range of visual recognition tasks, and the flexibility of the GC block allows it to be plugged into network architectures used in various computer vision problems. In this paper, we apply our GC block to three general vision tasks – image recognition, object detection/segmentation and action recognition.
GC block可以为很多应用提供Global context的学习,本文应用于图像识别,物体识别/分割,行为识别。
Relationship to non-local block.
大意是:GCNet和NLNet一样,能够对global context进行建模,但GCNet比NLNet lightweight的多。
Rlationship to squeeze-excitation block.
大意是:GCNet和SENet一样, lightweight,但SENet不能对global context进行建模。
My Note
这篇文章最大的贡献是
1) 发现了NLNet中,attention maps for different query positions are almost the same。
2) 继而提出了SNL。
3) 对比NL,SNL,SE,提出了Global Context Modeling Framework的基本框架,三点:Context Modeling,transform,fusion。
4) 结合SNL和SE,提出了最终的 GCNet。
5) 大量有价值的统计和实验结果。