python实战之爬虫音乐下载
import re#python 的正则库
import requests #python的requests库
import time
songId = []#用来储存每首歌对应的数字
songName = []#用来储存每首歌的名字
#这里先下载一页的歌曲
for n in range(0,1):#先下载一页的歌曲
#字符串的格式化n代替{}
url = ‘http://www.htqyy.com/top/musicList/hot?pageIndex={}&pageSize=20’.format(n)
print(url,end=’\n’)
#模拟浏览器请求,拿到html代码
html = requests.get(url)
#用正则表达式捕获数字,()内为捕获的内容*?为任何内容
resultId = re.findall(‘sid="(.*?)">’,html.text)
#用正则表达式捕获歌名
resultName = re.findall(’’,html.text)
songId.extend(resultId)
songName.extend(resultName)
print(songId)
print(songName)
for m in range(0,len(songId)):
#字符串的格式m代替{}
songUrl = “http://f2.htqyy.com/play7/{}/mp3/10”.format(songId[m])
print(songUrl,end=’\n’)
print(‘正在下载第{}首。。。’.format(m+1))
#得到返回资源的内容
response = requests.get(songUrl).content
#以二进制的形式写入文件中
f = open(‘F:\music\{}.mp3’.format(songName[m]),‘wb’)
f.write(response)
f.close()
之前缺省songName.extend(resultName)
显示
http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
[‘33’, ‘62’, ‘55’, ‘58’, ‘261’, ‘56’, ‘231’, ‘329’, ‘591’, ‘3’, ‘26’, ‘57’, ‘163’, ‘176’, ‘108’, ‘31’, ‘23’, ‘34’, ‘61’, ‘1621’]
[]
http://f2.htqyy.com/play7/33/mp3/10
正在下载第1首。。。
Traceback (most recent call last):
File “F:\ttt.py”, line 1287, in
f = open(‘F:\music\{}.mp3’.format(songName[m]),‘wb’)
IndexError: list index out of range
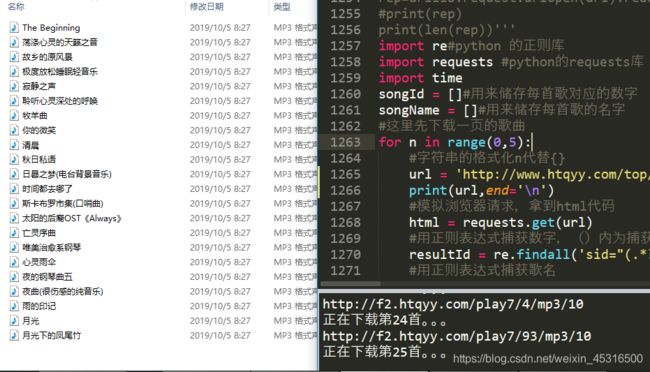
做了半天出错后,参考链接https://blog.csdn.net/weixin_41324527/article/details/80403159,谢谢大神的分享,终于找到了错误之处